
Regular readers of the newsletter will know that I have long been negatively impressed by the routine hallucinations of LLMs, and that my favorite example has involved an alleged pet chicken named Henrietta that I allegedly own:

This, sent to me by a reader in 2023, is of course a hallucination. I don’t actually own a pet chicken, nor any pet named Henrietta. If I did own a pet chicken I rather doubt I would call it Henrietta.
I do, however, know the legendary Harry Shearer, and was lucky enough to dine with him yesterday in LA. Antecedent to our breakfast, he sent me a problematic biography of him (“vomited by AI” in the words of a professor friend of his who forwarded it to him), along with the comment “No pet chicken, but still…”:

The joke was that, as we have come to expect, the AI’s output was truth mixed with untruth, intermingled so finely that to the uninitiated it might appear as truth — especially given the encyclopedia-like tone.
And indeed some of it is true. Harry really does act and do voiceovers for a lot of the Simpson characters, and he did play the bass player in the legendary This is Spinal Tap.
But, come on, the name of the bass player in Spinal Tap was Derek Smalls, not David Stanhill (a made-up name that doesn’t correspond to anyone Harry or I know, in that film or otherwise). And Harry is an American actor, not British, born and raised in Los Angeles. And whatever X may allege, Harry assures me that he didn’t have anything to do with Jaws.
And then there are the errors of omission; Harry didn’t just play Derek Smalls, he co-wrote This is Spinal Tap, a rather important credit to omit. He wrote for and performed on Saturday Night Live, and acted in many other movies from The Truman Show to A Mighty Wind, wrote and directed a documentary about Hurricane Katrina, and so on. No mention either of lovely and talented wife Judith Owen, his radio shows or his Primetime Emmy Award or Grammy nominations, either.
The extra embarrassing part about all of this for GenAI is that almost of the above information could have been found quickly and easily with a two second search for his wikipedia page, and most of it could be found in the first screenful at that.
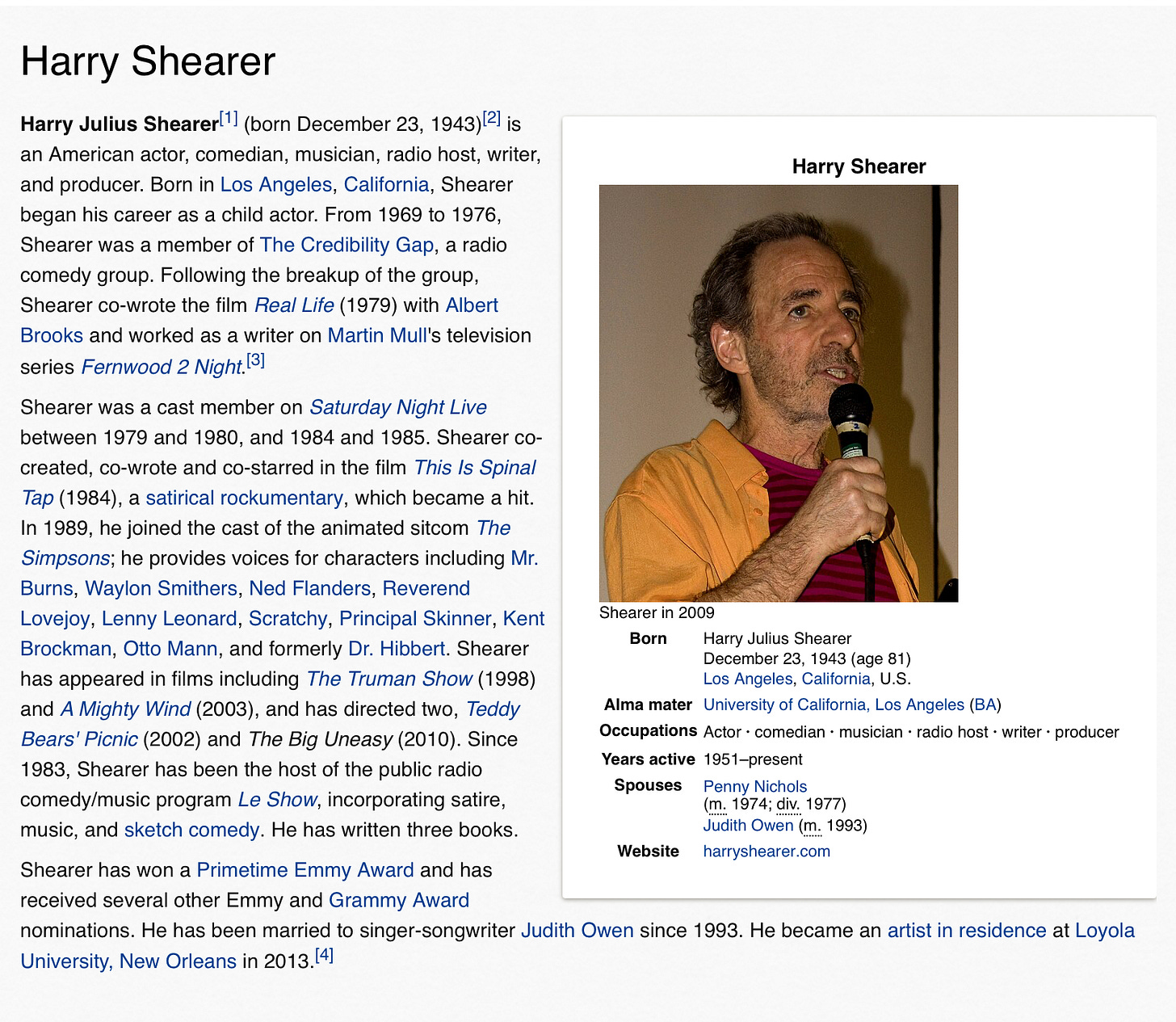
Three paragraphs and a box, and Google AI Overviews couldn’t get it right. Which raises the question: how could GenAI be so dumb that it could not fact check its own work against wikipedia? (And also, for another time, how could anyone think that a system so dumb is tantamount to AGI?)
§
As they occasionally say in the entertainment business, thereby lies a tale.
It is a tale of confusion: between what humans do, and what machines do.
That tale first started in 1965 with the simple AI system Eliza, which used a bunch of dopey keyword searches to fool humans into thinking it was far more intelligent than it actually was. You say “my girlfriend and I had a fight”, it matched the word “girlfriend” and spat back a phrase like “tell me more about your relationship”, and voila, some people imagined intelligence where there is nothing more than a simple party trick.
Because LLMS statistically mimic the language people have used, they often fool people into thinking that they operate like people.
But they don’t operate like people. They don’t, for example, ever fact check (as humans sometimes, when well motivated, do). They mimic the kinds of things of people say in various contexts. And that’s essentially all they do.
You can think of the whole output of an LLM as a little bit like Mad Libs.
[Human H] is a [Nationality N] [Profession P] known for [Y].
By sheer dint of crunching unthinkably large amounts of data about words co-occurring together in vast of corpora of text, sometimes that works out. Shearer and Spinal Tap co-occur in enough text that the systems gets that right. But that sort of statistical approximations lacks reliability. It is often right, but also routinely wrong. For example, some of the groups of people that Shearer belongs to, such as entertainers, actors, comedians, musicians and so forth includes many people from Britain, and so words for entertainers and the like co-occur often with words like British. To a next-token predictor, a phrase like Harry Shearer lives in a particular part of a multidimensional space. Words in that space are often followed by words like “British actor”. So out comes a hallucination.
And although I don’t own a pet chicken named Henrietta, another Gary (Oswalt) illustrated a book with Henrietta in the title. In the word schmear that is LLMs, that was perhaps enough to get an LLM to synthesize the bogus sentence with me and Henrietta.

Of course the systems are probabilistic; not every LLM will produce a hallucination every time. But the problem is not going away; OpenAI’s recent o3 actually hallucinates more than some its predecesssors.
The chronic problem with creating fake citations in research papers and faked cases in legal briefs is a manifestation of the same problem; LLMs correctly “model” the structure of academic references, but often make up titles, page numbers, journals and so on — once again failing to sanity check their outputs against information (in this case lists of references) that are readily found on the internet. So to is the rampant problem with numerical errors in financial reports, documented in a recent benchmark.
Just how bad is it? One recent study showed rates of hallucinations of between 15% and 60% across various models on a benchmark of 60 questions that were easily verifiable relative to easily found CNN source articles that were directly supplied in the exam. Even the best performance (15% hallucination rate) is, relative to an open-book exam with sources supplied, pathetic. That same study reports that, “According to Deloitte, 77% of businesses who joined the study are concerned about AI hallucinations”.
If I can be blunt, it is an absolute embarrassment that a technology that has collectively cost about half a trillion dollars can’t do something as basic as (reliably) check its output against wikipedia or a CNN article that is handed on a silver plattter. But LLMs still cannot – and on their own may never be able to — reliably do even things that basic.
LLMs don’t actually know what a nationality, or who Harry Shearer is; they know what words are and they know which words predict which other words in the context of words. They know what kinds of words cluster together in what order. And that’s pretty much it. They don’t operate like you and me. They don’t have a database of records like any proper business would (which would be a strong basis to solve the problem); and they don’t have what people like Yann LeCun or Judea Pearl or I would call a world model.
Even though they have surely digested Wikipedia, they can’t reliably stick to what is there (or justify their occasional deviations therefrom). They can’t even properly leverage the readily available database that parses wikipedia boxes into machine-readable form, which really ought to be child’s play for any genuinely intelligent system. (Those systems also can’t reliably stick to the rules of chess despite having them – and millions of games – in their database, a manifestation of the related problem of extracting statistical tendencies without every fully deriving and apprehending the correct abstractions).
LLMs have their uses – next-token prediction is great for a kind of fancy autocomplete for coding, for example — but it is a fallacy to think that because GenAI outputs sound human-like that their computations are human-like. LLMs mimic the rough structure of human language, but 8 years and roughly half a trillion dollars after their introduction, they continue to lack a grasp of a reality.
And they have such a superficial understanding of their own output that they can’t begin to fact check it.
We will eventually get to something better, but continuing to put all our eggs in the Henrietta’s LLM basket is absurd to the point of being delusional.
Dr. Gary Marcus has been warning people about the inherent problem of hallucinations in neural networks since 2001.
Bonus track: Harry Shearer contemplating LLMs, May 4, 2025, in his hometown of Los Angeles, photo by the author:
