
This post was written with Dominic Catalano from Anyscale.
Organizations building and deploying large-scale AI models often face critical infrastructure challenges that can directly impact their bottom line: unstable training clusters that fail mid-job, inefficient resource utilization driving up costs, and complex distributed computing frameworks requiring specialized expertise. These factors can lead to unused GPU hours, delayed projects, and frustrated data science teams. This post demonstrates how you can address these challenges by providing a resilient, efficient infrastructure for distributed AI workloads.
Amazon SageMaker HyperPod is a purpose-built persistent generative AI infrastructure optimized for machine learning (ML) workloads. It provides robust infrastructure for large-scale ML workloads with high-performance hardware, so organizations can build heterogeneous clusters using tens to thousands of GPU accelerators. With nodes optimally co-located on a single spine, SageMaker HyperPod reduces networking overhead for distributed training. It maintains operational stability through continuous monitoring of node health, automatically swapping faulty nodes with healthy ones and resuming training from the most recently saved checkpoint, all of which can help save up to 40% of training time. For advanced ML users, SageMaker HyperPod allows SSH access to the nodes in the cluster, enabling deep infrastructure control, and allows access to SageMaker tooling, including Amazon SageMaker Studio, MLflow, and SageMaker distributed training libraries, along with support for various open-source training libraries and frameworks. SageMaker Flexible Training Plans complement this by enabling GPU capacity reservation up to 8 weeks in advance for durations up to 6 months.
The Anyscale platform integrates seamlessly with SageMaker HyperPod when using Amazon Elastic Kubernetes Service (Amazon EKS) as the cluster orchestrator. Ray is the leading AI compute engine, offering Python-based distributed computing capabilities to address AI workloads ranging from multimodal AI, data processing, model training, and model serving. Anyscale unlocks the power of Ray with comprehensive tooling for developer agility, critical fault tolerance, and an optimized version called RayTurbo, designed to deliver leading cost-efficiency. Through a unified control plane, organizations benefit from simplified management of complex distributed AI use cases with fine-grained control across hardware.
The combined solution provides extensive monitoring through SageMaker HyperPod real-time dashboards tracking node health, GPU utilization, and network traffic. Integration with Amazon CloudWatch Container Insights, Amazon Managed Service for Prometheus, and Amazon Managed Grafana delivers deep visibility into cluster performance, complemented by Anyscale’s monitoring framework, which provides built-in metrics for monitoring Ray clusters and the workloads that run on them.
This post demonstrates how to integrate the Anyscale platform with SageMaker HyperPod. This combination can deliver tangible business outcomes: reduced time-to-market for AI initiatives, lower total cost of ownership through optimized resource utilization, and increased data science productivity by minimizing infrastructure management overhead. It is ideal for Amazon EKS and Kubernetes-focused organizations, teams with large-scale distributed training needs, and those invested in the Ray ecosystem or SageMaker.
Solution overview
The following architecture diagram illustrates SageMaker HyperPod with Amazon EKS orchestration and Anyscale.
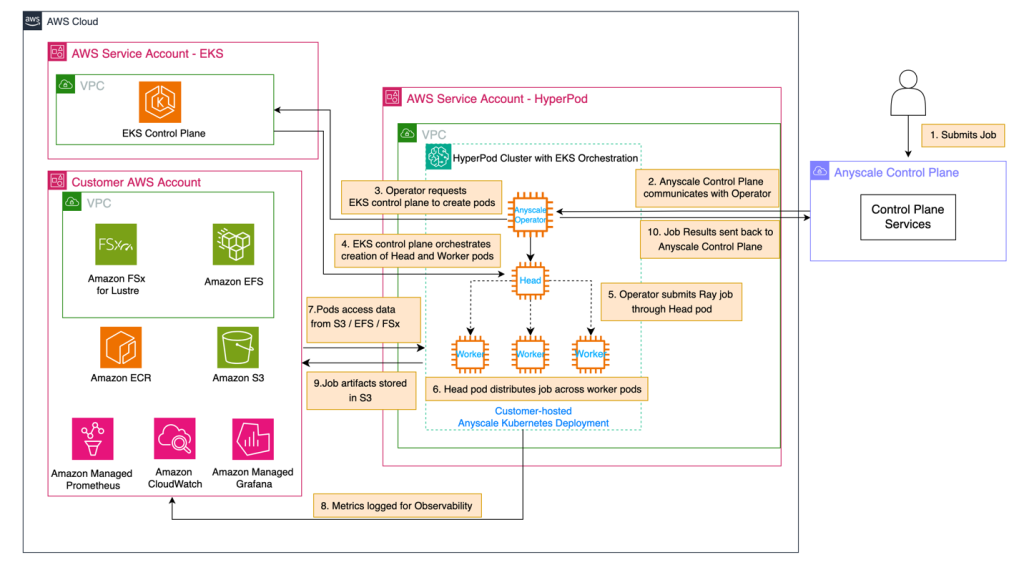
The sequence of events in this architecture is as follows:
A user submits a job to the Anyscale Control Plane, which is the main user-facing endpoint.
The Anyscale Control Plane communicates this job to the Anyscale Operator within the SageMaker HyperPod cluster in the SageMaker HyperPod virtual private cloud (VPC).
The Anyscale Operator, upon receiving the job, initiates the process of creating the necessary pods by reaching out to the EKS control plane.
The EKS control plane orchestrates creation of a Ray head pod and worker pods. These pods represent a Ray cluster, running on SageMaker HyperPod with Amazon EKS.
The Anyscale Operator submits the job through the head pod, which serves as the primary coordinator for the distributed workload.
The head pod distributes the workload across multiple worker pods, as shown in the hierarchical structure in the SageMaker HyperPod EKS cluster.
Worker pods execute their assigned tasks, potentially accessing required data from the storage services – such as Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), or Amazon FSx for Lustre – in the user VPC.
Throughout the job execution, metrics and logs are published to Amazon CloudWatch and Amazon Managed Service for Prometheus or Amazon Managed Grafana for observability.
When the Ray job is complete, the job artifacts (final model weights, inference results, and so on) are saved to the designated storage service.
Job results (status, metrics, logs) are sent through the Anyscale Operator back to the Anyscale Control Plane.
This flow shows distribution and execution of user-submitted jobs across the available computing resources, while maintaining monitoring and data accessibility throughout the process.
Prerequisites
Before you begin, you must have the following resources:
Set up Anyscale Operator
Complete the following steps to set up the Anyscale Operator:
In your workspace, download the aws-do-ray repository:
This repository has the commands needed to deploy the Anyscale Operator on a SageMaker HyperPod cluster. The aws-do-ray project aims to simplify the deployment and scaling of distributed Python application using Ray on Amazon EKS or SageMaker HyperPod. The aws-do-ray container shell is equipped with intuitive action scripts and comes preconfigured with convenient shortcuts, which save extensive typing and increase productivity. You can optionally use these features by building and opening a bash shell in the container with the instructions in the aws-do-ray README, or you can continue with the following steps.
If you continue with these steps, make sure your environment is properly set up:
Verify your connection to the HyperPod cluster:
Obtain the name of the EKS cluster on the SageMaker HyperPod console. In your cluster details, you will see your EKS cluster orchestrator.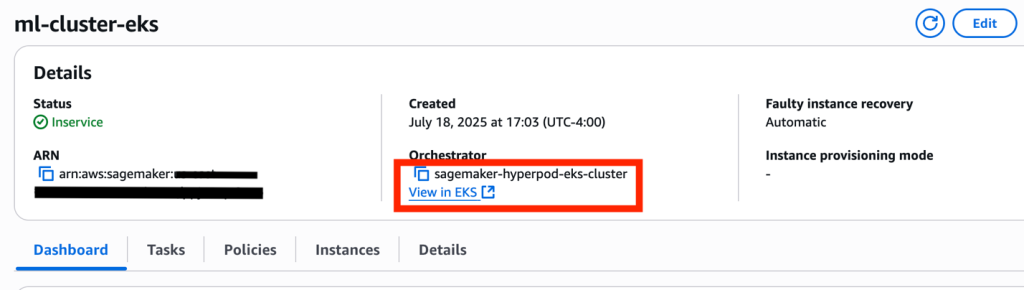
Update kubeconfig to connect to the EKS cluster:
The following screenshot shows an example output.

If the output indicates InProgress instead of Passed, wait for the deep health checks to finish.

Review the env_vars file. Update the variable AWS_EKS_HYPERPOD_CLUSTER. You can leave the values as default or make desired changes.
Deploy your requirements:
This creates the anyscale namespace, installs Anyscale dependencies, configures login to your Anyscale account (this step will prompt you for additional verification as shown in the following screenshot), adds the anyscale helm chart, installs the ingress-nginx controller, and finally labels and taints SageMaker HyperPod nodes for the Anyscale worker pods.

Create an EFS file system:
Amazon EFS serves as the shared cluster storage for the Anyscale pods.
At the time of writing, Amazon EFS and S3FS are the supported file system options when using Anyscale and SageMaker HyperPod setups with Ray on AWS. Although FSx for Lustre is not supported with this setup, you can use it with KubeRay on SageMaker HyperPod EKS.
Register an Anyscale Cloud:
This registers a self-hosted Anyscale Cloud into your SageMaker HyperPod cluster. By default, it uses the value of ANYSCALE_CLOUD_NAME in the env_vars file. You can modify this field as needed. At this point, you will be able to see your registered cloud on the Anyscale console.
Deploy the Kubernetes Anyscale Operator:
This command installs the Anyscale Operator in the anyscale namespace. The Operator will start posting health checks to the Anyscale Control Plane.
To see the Anyscale Operator pod, run the following command:kubectl get pods -n anyscale
Submit training job
This section walks through a simple training job submission. The example implements distributed training of a neural network for Fashion MNIST classification using the Ray Train framework on SageMaker HyperPod with Amazon EKS orchestration, demonstrating how to use the AWS managed ML infrastructure combined with Ray’s distributed computing capabilities for scalable model training.Complete the following steps:
Navigate to the jobs directory. This contains folders for available example jobs you can run. For this walkthrough, go to the dt-pytorch directory containing the training job.
Configure the required environment variables:
Create Anyscale compute configuration:
./1.create-compute-config.sh
Submit the training job:
./2.submit-dt-pytorch.shThis uses the job configuration specified in job_config.yaml. For more information on the job config, refer to JobConfig.
Monitor the deployment. You will see the newly created head and worker pods in the anyscale namespace.
kubectl get pods -n anyscale
View the job status and logs on the Anyscale console to monitor your submitted job’s progress and output.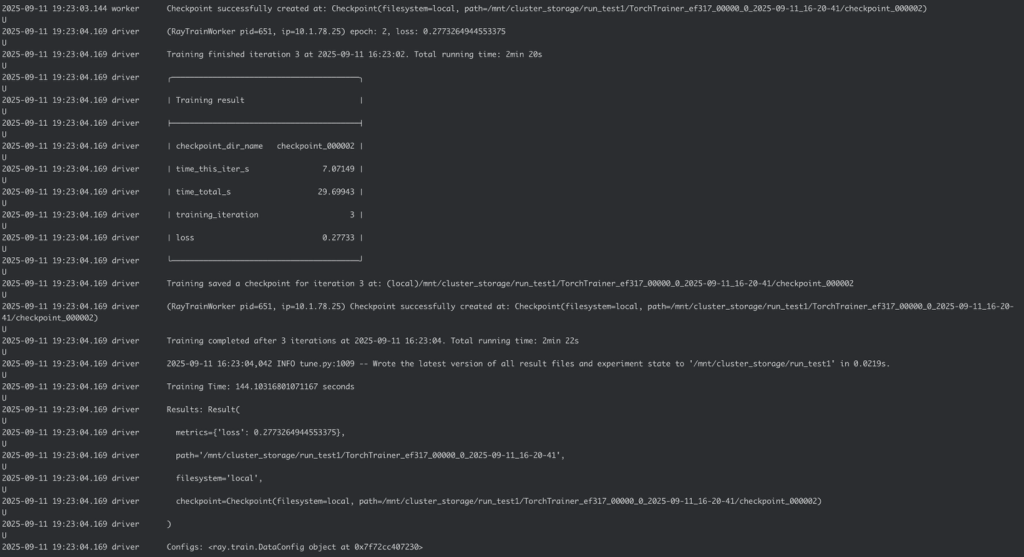
Clean up
To clean up your Anyscale cloud, run the following command:
To delete your SageMaker HyperPod cluster and associated resources, delete the CloudFormation stack if this is how you created the cluster and its resources.
Conclusion
This post demonstrated how to set up and deploy the Anyscale Operator on SageMaker HyperPod using Amazon EKS for orchestration.SageMaker HyperPod and Anyscale RayTurbo provide a highly efficient, resilient solution for large-scale distributed AI workloads: SageMaker HyperPod delivers robust, automated infrastructure management and fault recovery for GPU clusters, and RayTurbo accelerates distributed computing and optimizes resource usage with no code changes required. By combining the high-throughput, fault-tolerant environment of SageMaker HyperPod with RayTurbo’s faster data processing and smarter scheduling, organizations can train and serve models at scale with improved reliability and significant cost savings, making this stack ideal for demanding tasks like large language model pre-training and batch inference.
For more examples of using SageMaker HyperPod, refer to the Amazon EKS Support in Amazon SageMaker HyperPod workshop and the Amazon SageMaker HyperPod Developer Guide. For information on how customers are using RayTurbo, refer to RayTurbo.
About the authors
 Sindhura Palakodety is a Senior Solutions Architect at AWS and Single-Threaded Leader (STL) for ISV Generative AI, where she is dedicated to empowering customers in developing enterprise-scale, Well-Architected solutions. She specializes in generative AI and data analytics domains, helping organizations use innovative technologies for transformative business outcomes.
Sindhura Palakodety is a Senior Solutions Architect at AWS and Single-Threaded Leader (STL) for ISV Generative AI, where she is dedicated to empowering customers in developing enterprise-scale, Well-Architected solutions. She specializes in generative AI and data analytics domains, helping organizations use innovative technologies for transformative business outcomes.
 Mark Vinciguerra is an Associate Specialist Solutions Architect at AWS based in New York. He focuses on generative AI training and inference, with the goal of helping customers architect, optimize, and scale their workloads across various AWS services. Prior to AWS, he went to Boston University and graduated with a degree in Computer Engineering.
Mark Vinciguerra is an Associate Specialist Solutions Architect at AWS based in New York. He focuses on generative AI training and inference, with the goal of helping customers architect, optimize, and scale their workloads across various AWS services. Prior to AWS, he went to Boston University and graduated with a degree in Computer Engineering.
 Florian Gauter is a Worldwide Specialist Solutions Architect at AWS, based in Hamburg, Germany. He specializes in AI/ML and generative AI solutions, helping customers optimize and scale their AI/ML workloads on AWS. With a background as a Data Scientist, Florian brings deep technical expertise to help organizations design and implement sophisticated ML solutions. He works closely with customers worldwide to transform their AI initiatives and maximize the value of their ML investments on AWS.
Florian Gauter is a Worldwide Specialist Solutions Architect at AWS, based in Hamburg, Germany. He specializes in AI/ML and generative AI solutions, helping customers optimize and scale their AI/ML workloads on AWS. With a background as a Data Scientist, Florian brings deep technical expertise to help organizations design and implement sophisticated ML solutions. He works closely with customers worldwide to transform their AI initiatives and maximize the value of their ML investments on AWS.
 Alex Iankoulski is a Principal Solutions Architect in the Worldwide Specialist Organization at AWS. He focuses on orchestration of AI/ML workloads using containers. Alex is the author of the do-framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. Over the past 10 years, Alex has worked on helping customers do more on AWS, democratizing AI and ML, combating climate change, and making travel safer, healthcare better, and energy smarter.
Alex Iankoulski is a Principal Solutions Architect in the Worldwide Specialist Organization at AWS. He focuses on orchestration of AI/ML workloads using containers. Alex is the author of the do-framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges. Over the past 10 years, Alex has worked on helping customers do more on AWS, democratizing AI and ML, combating climate change, and making travel safer, healthcare better, and energy smarter.
 Anoop Saha is a Senior GTM Specialist at AWS focusing on generative AI model training and inference. He is partnering with top foundation model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop has held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Senior GTM Specialist at AWS focusing on generative AI model training and inference. He is partnering with top foundation model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop has held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
 Dominic Catalano is a Group Product Manager at Anyscale, where he leads product development across AI/ML infrastructure, developer productivity, and enterprise security. His work focuses on distributed systems, Kubernetes, and helping teams run AI workloads at scale.
Dominic Catalano is a Group Product Manager at Anyscale, where he leads product development across AI/ML infrastructure, developer productivity, and enterprise security. His work focuses on distributed systems, Kubernetes, and helping teams run AI workloads at scale.