
Hao Zhang, a PhD student at the University of Illinois at Urbana-Champaign (UIUC), focuses on 3D/4D reconstruction, generative modeling, and physics-driven animation. He is currently a research intern at Snap Inc. and has previously interned at Stability AI and the Shanghai Artificial Intelligence Laboratory. This project, Stable Part Diffusion 4D (SP4D), is a collaboration between Stability AI and UIUC, capable of generating temporally and spatially consistent multi-view RGB and kinematic part sequences from monocular video, which can be further enhanced into bindable 3D assets. Personal homepage: https://haoz19.github.io/
In character animation and 3D content creation, rigging and part segmentation are essential for creating animatable assets. However, existing methods have significant limitations:
Automatic Rigging: Dependent on limited-scale 3D datasets and skeletal/skinning annotations, it struggles to cover diverse object forms and complex poses, resulting in insufficient model generalization.
Part Segmentation: Current methods often rely on semantic or appearance features (such as “head,” “tail,” “legs,” etc.) for segmentation, lacking modeling of true kinematic structures, resulting in instability across viewpoints or time sequences, making them challenging to apply directly to animation-driven tasks.

To address this, we propose a core motivation: to leverage large-scale 2D data and the strong prior knowledge of pre-trained diffusion models to tackle the problem of kinematic part segmentation and extend it to automatic rigging. This approach can break through the bottleneck of scarce 3D data, enabling AI to genuinely learn to generate 3D animatable assets that adhere to the laws of physical motion.
Research Methods and Innovations
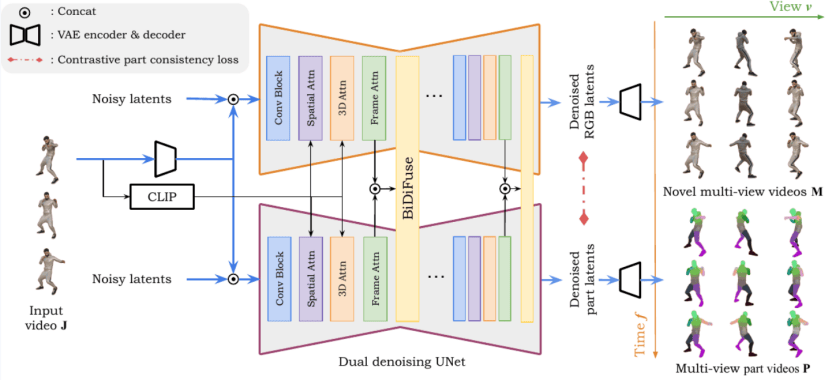
Based on this motivation, we propose Stable Part Diffusion 4D (SP4D) — the first multi-view video diffusion framework aimed at kinematic part segmentation. Key innovations include:
Dual-Branch Diffusion Architecture: Simultaneously generating appearance and kinematic structure to achieve joint modeling of RGB and parts.
BiDiFuse Bidirectional Fusion Module: Enabling cross-modal interaction between RGB and part information to enhance structural consistency.
Contrastive Consistency Loss: Ensuring that the same part remains stable and consistent across different viewpoints and time.
KinematicParts20K Dataset: The team constructed over 20,000 skeletal annotated objects based on Objaverse-XL, providing high-quality training and evaluation data.
This framework not only generates temporally and spatially consistent part segmentation but also elevates the results to bindable 3D meshes, deriving skeletal structures and skinning weights, which can be directly applied to animation production.
Experimental Results
On the KinematicParts20K validation set, SP4D achieved significant improvements over existing methods:
Segmentation Accuracy: mIoU improved to 0.68, significantly ahead of SAM2 (0.15) and DeepViT (0.17).
Structural Consistency: ARI reached 0.60, far exceeding SAM2’s 0.05.
User Study: On the metrics of “part clarity, cross-view consistency, and animation adaptability,” SP4D averaged a score of 4.26/5, significantly outperforming SAM2 (1.96) and DeepViT (1.85) 2509.10687v1.

In the automatic rigging task, SP4D also demonstrated stronger potential:
On KinematicParts20K-test, SP4D achieved a Rigging Precision of 72.7, showing a clear advantage over Magic Articulate (63.7) and UniRig (64.3).
In user evaluations of animation naturalness, SP4D averaged a score of 4.1/5, far exceeding Magic Articulate (2.7) and UniRig (2.3), showcasing better generalization for unseen categories and complex forms.
These results strongly demonstrate that the 2D prior-driven approach not only addresses the long-standing challenges of kinematic part segmentation but also effectively extends to automatic rigging, promoting full automation in animation and 3D asset generation.

Conclusion
Stable Part Diffusion 4D (SP4D) represents not only a technical breakthrough but also the result of interdisciplinary collaboration, accepted as a Spotlight at Neurips 2025. It showcases how to leverage large-scale 2D priors to open new avenues in 3D kinematic modeling and automatic rigging, laying the foundation for automation and intelligence in fields such as animation, gaming, AR/VR, and robotic simulation.返回搜狐,查看更多