
Organizations gain competitive advantage by deploying and integrating new generative AI models quickly through Generative AI Gateway architectures. This unified interface approach simplifies access to multiple foundation models (FMs), addressing a critical challenge: the proliferation of specialized AI models, each with unique capabilities, API specifications, and operational requirements. Rather than building and maintaining separate integration points for each model, the smart move is to build an abstraction layer that normalizes these differences behind a single, consistent API.
The AWS Generative AI Innovation Center and Quora recently collaborated on an innovative solution to address this challenge. Together, they developed a unified wrapper API framework that streamlines the deployment of Amazon Bedrock FMs on Quora’s Poe system. This architecture delivers a “build once, deploy multiple models” capability that significantly reduces deployment time and engineering effort, with real protocol bridging code visible throughout the codebase.
For technology leaders and developers working on AI multi-model deployment at scale, this framework demonstrates how thoughtful abstraction and protocol translation can accelerate innovation cycles while maintaining operational control.
In this post, we explore how the AWS Generative AI Innovation Center and Quora collaborated to build a unified wrapper API framework that dramatically accelerates the deployment of Amazon Bedrock FMs on Quora’s Poe system. We detail the technical architecture that bridges Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, demonstrate how a template-based configuration system reduced deployment time from days to 15 minutes, and share implementation patterns for protocol translation, error handling, and multi-modal capabilities. We show how this “build once, deploy multiple models” approach helped Poe integrate over 30 Amazon Bedrock models across text, image, and video modalities while reducing code changes by up to 95%.
Quora and Amazon Bedrock
Poe.com is an AI system developed by Quora that users and developers can use to interact with a wide range of advanced AI models and assistants powered by multiple providers. The system offers multi-model access, enabling side-by-side conversations with various AI chatbots for tasks such as natural language understanding, content generation, image creation, and more.
This screenshot below showcases the user interface of Poe, the AI platform created by Quora. The image displays Poe’s extensive library of AI models, which are presented as individual “chatbots” that users can interact with.

The following screenshot provides a view of the Model Catalog within Amazon Bedrock, a fully managed service from Amazon Web Services (AWS) that offers access to a diverse range of foundation models (FMs). This catalog acts as a central hub for developers to discover, evaluate, and access state-of-the-art AI from various providers.
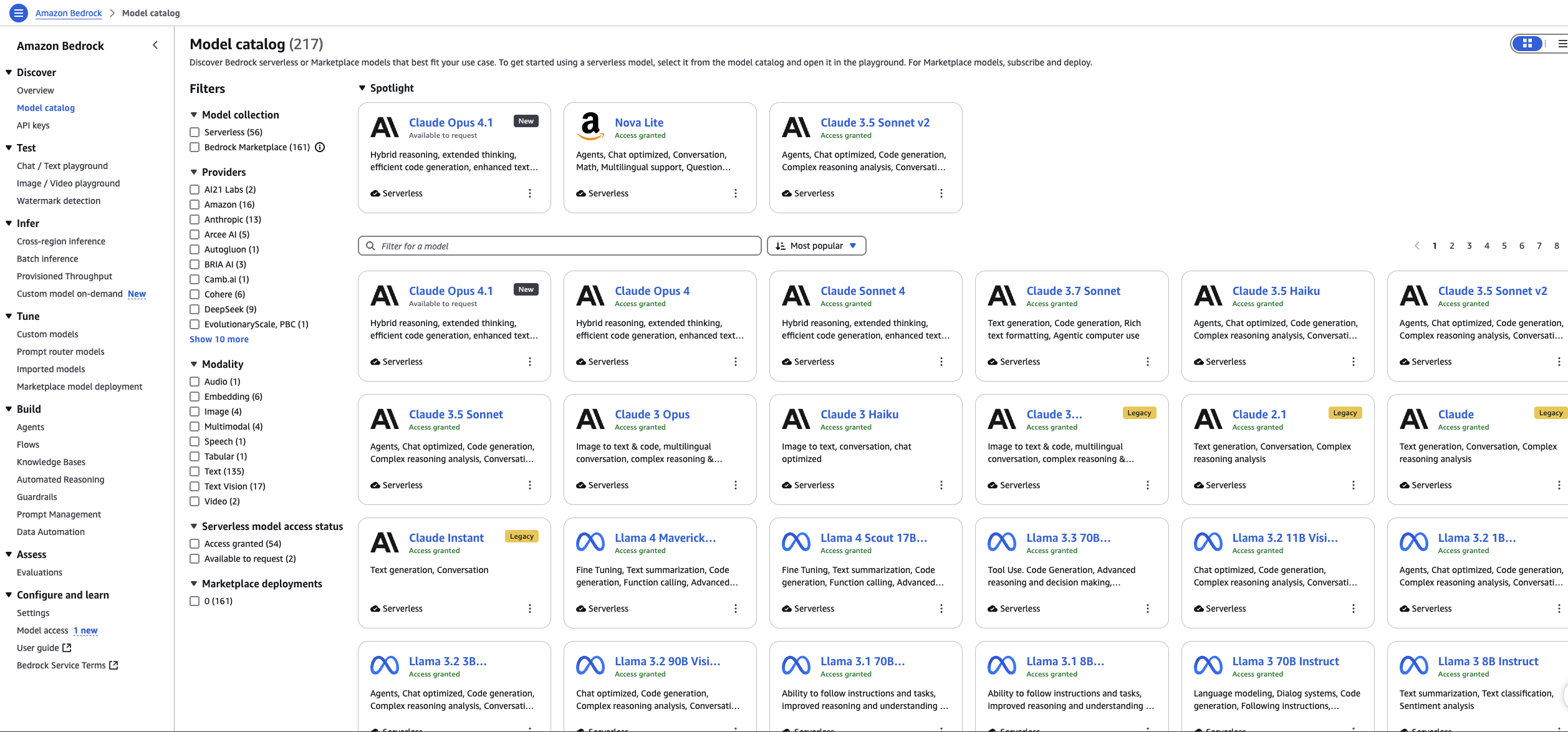
Initially, integrating the diverse FMs available through Amazon Bedrock presented significant technical challenges for the Poe.com team. The process required substantial engineering resources to establish connections with each model while maintaining consistent performance and reliability standards. Maintainability emerged as an extremely important consideration, as was the ability to efficiently onboard new models as they became available—both factors adding further complexity to the integration challenges.
Technical challenge: Bridging different systems
The integration between Poe and Amazon Bedrock presented fundamental architectural challenges that required innovative solutions. These systems were built with different design philosophies and communication patterns, creating a significant technical divide that the wrapper API needed to bridge.
Architectural divide
The core challenge stems from the fundamentally different architectural approaches of the two systems. Understanding these differences is essential to appreciating the complexity of the integration solution. Poe operates on a modern, reactive, ServerSentEvents-based architecture through the Fast API library (fastapi_poe). This architecture is stream-optimized for real-time interactions and uses an event-driven response model designed for continuous, conversational AI. Amazon Bedrock, on the other hand, functions as an enterprise cloud service. It offers REST-based with AWS SDK access patterns, SigV4 authentication requirements, AWS Region-specific model availability, and a traditional request-response pattern with streaming options. This fundamental API mismatch creates several technical challenges that the Poe wrapper API solves, as detailed in the following table.
Challenge Category
Technical Issue
Source Protocol
Target Protocol
Integration Complexity
Protocol Translation
Converting between WebSocket-based protocol and REST APIs
WebSocket (bidirectional, persistent)
REST (request/response, stateless)
High: Requires protocol bridging
Authentication Bridging
Connecting JWT validation with AWS SigV4 signing
JWT token validation
AWS SigV4 authentication
Medium: Credential transformation needed
Response Format Transformation
Adapting JSON responses into expected format
Standard JSON structure
Custom format requirements
Medium: Data structure mapping
Streaming Reconciliation
Mapping chunked responses to ServerSentEvents
Chunked HTTP responses
ServerSentEvents stream
High: Real-time data flow conversion
Parameter Standardization
Creating unified parameter space across models
Model-specific parameters
Standardized parameter interface
Medium: Parameter normalization
API evolution and the Converse API
In May 2024, Amazon Bedrock introduced the Converse API, which offered standardization benefits that significantly simplified the integration architecture:
Unified interface across diverse model providers (such as Anthropic, Meta, and Mistral)
Conversation memory with consistent handling of chat history
Streaming and non-streaming modes through a single API pattern
Multimodal support for text, images, and structured data
Parameter normalization that reduces model-specific implementation quirks
Built-in content moderation capabilities
The solution presented in this post uses the Converse API where appropriate, while also maintaining compatibility with model-specific APIs for specialized capabilities. This hybrid approach provides flexibility while taking advantage of the Converse API’s standardization benefits.
Solution overview
The wrapper API framework provides a unified interface between Poe and Amazon Bedrock models. It serves as a translation layer that normalizes the differences between models and protocols while maintaining the unique capabilities of each model.
The solution architecture follows a modular design that separates concerns and enables flexible scaling, as illustrated in the following diagram.
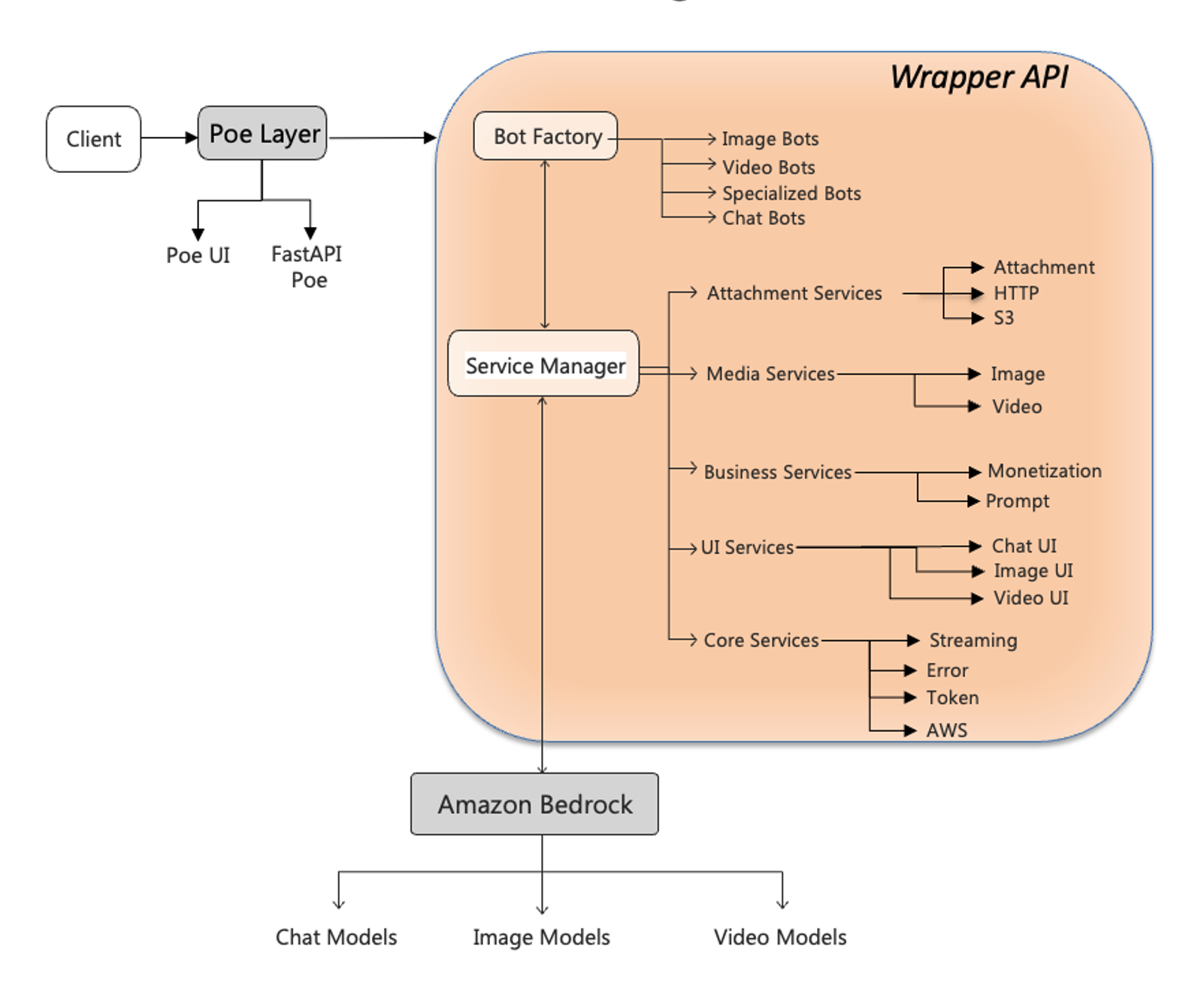
The wrapper API consists of several key components working together to provide a seamless integration experience:
Client – The entry point where users interact with AI capabilities through various interfaces.
Poe layer – Consists of the following:
Poe UI – Handles user experience, request formation, parameters controls, file uploads, and response visualization.
Poe FastAPI – Standardizes user interactions and manages the communication protocol between clients and underlying systems.
Bot Factory – Dynamically creates appropriate model handlers (bots) based on the requested model type (chat, image, or video). This factory pattern provides extensibility for new model types and variations. See the following code:
Service manager: Orchestrates the services needed to process requests effectively. It coordinates between different specialized services, including:
Token services – Managing token limits and counting.
Streaming services – Handling real-time responses.
Error services – Normalizing and handling errors.
AWS service integration – Managing API calls to Amazon Bedrock.
AWS services component – Converts responses from Amazon Bedrock format to Poe’s expected format and vice-versa, handling streaming chunks, image data, and video outputs.
Amazon Bedrock layer – Amazon’s FM service that provides the actual AI processing capabilities and model hosting, including:
Model diversity – Provides access to over 30 text models (such as Amazon Titan, Amazon Nova, Anthropic’s Claude, Meta’s Llama, Mistral, and more), image models, and video models.
API structure – Exposes both model-specific APIs and the unified Converse API.
Authentication – Requires AWS SigV4 signing for secure access to model endpoints.
Response management – Returns model outputs with standardized metadata and usage statistics.
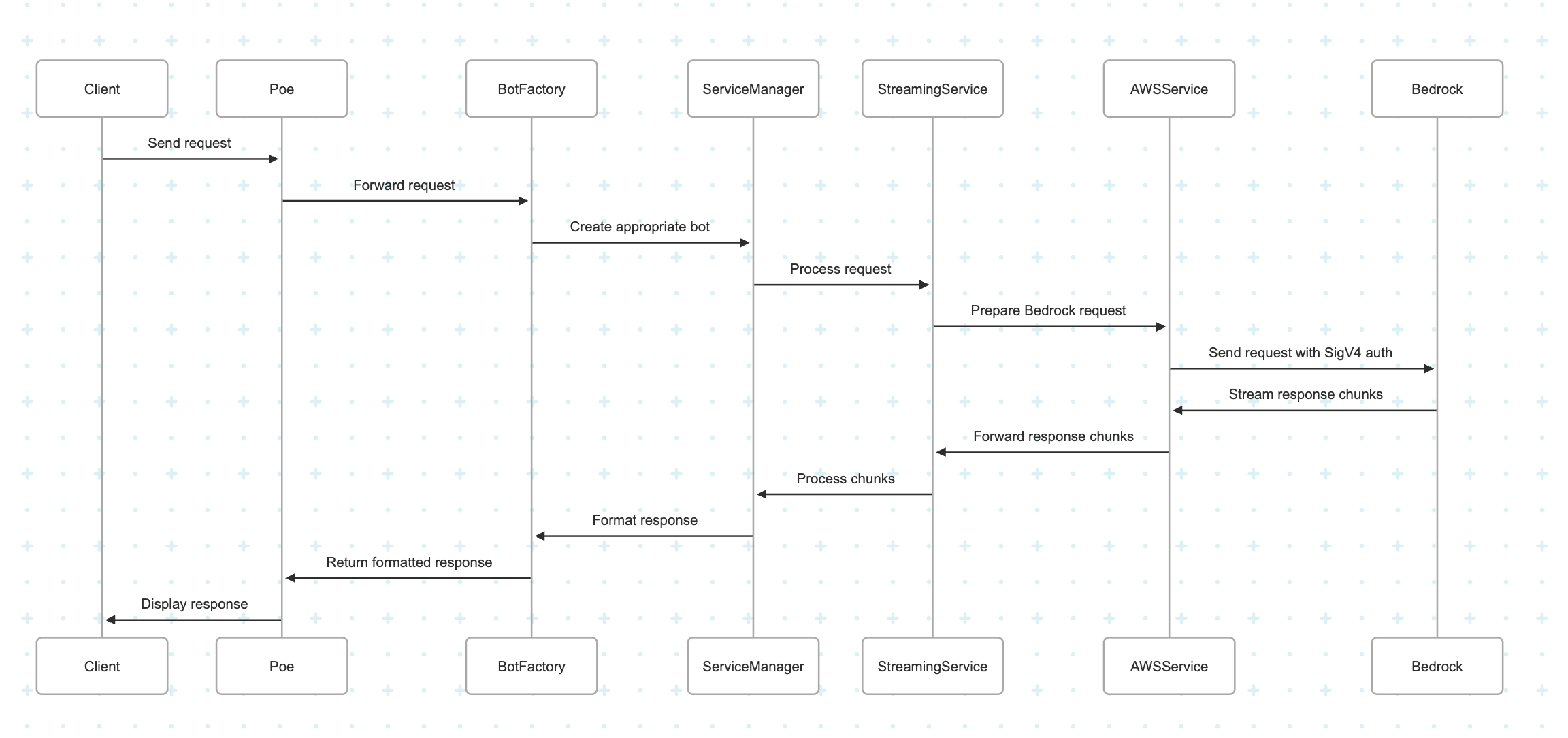
The request processing flow in this unified wrapper API shows the orchestration required when bridging Poe’s event-driven ServerSentEvents protocol with Amazon Bedrock REST-based APIs, showcasing how multiple specialized services work together to deliver a seamless user experience.
The flow begins when a client sends a request through Poe’s interface, which then forwards it to the Bot Factory component. This factory pattern dynamically creates the appropriate model handler based on the requested model type, whether for chat, image, or video generation. The service manager component then orchestrates the various specialized services needed to process the request effectively, including token services, streaming services, and error handling services.
The following sequence diagram illustrates the complete request processing flow.
Configuration template for rapid multi-bot deployment
The most powerful aspect of the wrapper API is its unified configuration template system, which supports rapid deployment and management of multiple bots with minimal code changes. This approach is central to the solution’s success in reducing deployment time.
The system uses a template-based configuration approach with shared defaults and model-specific overrides:
This configuration-driven architecture offers several significant advantages:
Rapid deployment – Adding new models requires only creating a new configuration entry rather than writing integration code. This is a key factor in the significant improvement in deployment time.
Consistent parameter management – Common parameters are defined one time in DEFAULT_CHAT_CONFIG and inherited by bots, maintaining consistency and reducing duplication.
Model-specific customization – Each model can have its own unique settings while still benefiting from the shared infrastructure.
Operational flexibility – Parameters can be adjusted without code changes, allowing for quick experimentation and optimization.
Centralized credential management – AWS credentials are managed in one place, improving security and simplifying updates.
Region-specific deployment – Models can be deployed to different Regions as needed, with Region settings controlled at the configuration level.
The BotConfig class provides a structured way to define bot configurations with type validation:
Advanced multimodal capabilities
One of the most powerful aspects of the framework is how it handles multimodal capabilities through simple configuration flags:
enable_image_comprehension – When set to True for text-only models like Amazon Nova Micro, Poe itself uses vision capabilities to analyze images and convert them into text descriptions that are sent to the Amazon Bedrock model. This enables even text-only models to classify images without having built-in vision capabilities.
expand_text_attachments – When set to True, Poe parses uploaded text files and includes their content in the conversation, enabling models to work with document content without requiring special file handling capabilities.
supports_system_messages – This parameter controls whether the model can accept system prompts, allowing for consistent behavior across models with different capabilities.
These configuration flags create a powerful abstraction layer that offers the following benefits:
Extends model capabilities – Text-only models gain pseudo-multimodal capabilities through Poe’s preprocessing
Optimizes built-in features – True multimodal models can use their built-in capabilities for optimal results
Simplifies integration – It’s controlled through simple configuration switches rather than code changes
Maintains consistency – It provides a uniform user experience regardless of the underlying model’s native capabilities
Next, we explore the technical implementation of the solution in more detail.
Protocol translation layer
The most technically challenging aspect of the solution was bridging between Poe’s API protocols and the diverse model interfaces available through Amazon Bedrock. The team accomplished this through a sophisticated protocol translation layer:
This translation layer handles subtle differences between models and makes sure that regardless of which Amazon Bedrock model is being used, the response to Poe is consistent and follows Poe’s expected format.
Error handling and normalization
A critical aspect of the implementation is comprehensive error handling and normalization. The ErrorService provides consistent error handling across different models:
This approach makes sure users receive meaningful error messages regardless of the underlying model or error condition.
Token counting and optimization
The system implements sophisticated token counting and optimization to maximize effective use of models:
This detailed token tracking enables accurate cost estimation and optimization, facilitating efficient use of model resources.
AWS authentication and security
The AwsClientService handles authentication and security for Amazon Bedrock API calls.This implementation provides secure authentication with AWS services while providing proper error handling and connection management.
Comparative analysis
The implementation of the wrapper API dramatically improved the efficiency and capabilities of deploying Amazon Bedrock models on Poe, as detailed in the following table.
Feature
Before (Direct API)
After (Wrapper API)
Deployment Time
Days per model
Minutes per model
Developer Focus
Configuration and plumbing
Innovation and features
Model Diversity
Limited by integration capacity
Extensive (across Amazon Bedrock models)
Maintenance Overhead
High (separate code for each model)
Low (configuration-based)
Error Handling
Custom per model
Standardized across models
Cost Tracking
Complex (multiple integrations)
Simplified (centralized)
Multimodal Support
Fragmented
Unified
Security
Varied implementations
Consistent best practices
This comparison highlights the significant improvements achieved through the wrapper API approach, demonstrating the value of investing in a robust abstraction layer.
Performance metrics and business impact
The wrapper API framework delivered significant and measurable business impact across multiple dimensions, including increased model diversity, deployment efficiency, and developer productivity.
Poe can rapidly expand its model offerings, integrating tens of Amazon Bedrock models across text, image, and video modalities. This expansion occurred over a period of weeks rather than the months it would have taken with the previous approach.
The following table summarizes the deployment efficiency metrics.
Metric
Before
After
Improvement
New Model Deployment
2 –3 days
15 minutes
96x faster
Code Changes Required
500+ lines
20–30 lines
95% reduction
Testing Time
8–12 hours
30–60 minutes
87% reduction
Deployment Steps
10–15 steps
3–5 steps
75% reduction
These metrics were measured through direct comparison of engineering hours required before and after implementation, tracking actual deployments of new models.
The engineering team saw a dramatic shift in focus from integration work to feature development, as detailed in the following table.
Activity
Before (% of time)
After (% of time)
Change
API Integration
65%
15%
-50%
Feature Development
20%
60%
+40%
Testing
10%
15%
+5%
Documentation
5%
10%
+5%
Scaling and performance considerations
The wrapper API is designed to handle high-volume production workloads with robust scaling capabilities.
Connection pooling
To handle multiple concurrent requests efficiently, the wrapper implements connection pooling using aiobotocore. This allows it to maintain a pool of connections to Amazon Bedrock, reducing the overhead of establishing new connections for each request:
Asynchronous processing
The entire framework uses asynchronous processing to handle concurrent requests efficiently:
Error recovery and retry logic
The system implements sophisticated error recovery and retry logic to handle transient issues:
Performance metrics
The system collects detailed performance metrics to help identify bottlenecks and optimize performance:
Security considerations
Security is a critical aspect of the wrapper implementation, with several key features to support secure operation.
JWT validation with AWS SigV4 signing
The system integrates JWT validation for Poe’s authentication with AWS SigV4 signing for Amazon Bedrock API calls:
JWT validation – Makes sure only authorized Poe requests can access the wrapper API
SigV4 signing – Makes sure the wrapper API can securely authenticate with Amazon Bedrock
Credential management – AWS credentials are securely managed and not exposed to clients
Secrets management
The system integrates with AWS Secrets Manager to securely store and retrieve sensitive credentials:
Secure connection management
The system implements secure connection management to help prevent credential leakage and facilitate proper cleanup:
Troubleshooting and debugging
The wrapper API includes comprehensive logging and debugging capabilities to help identify and resolve issues. The system implements detailed logging throughout the request processing flow. Each request is assigned a unique ID that is used throughout the processing flow to enable tracing:
Lessons learned and best practices
Through this collaboration, several important technical insights emerged that might benefit others undertaking similar projects:
Configuration-driven architecture – Using configuration files rather than code for model-specific behaviors proved enormously beneficial for maintenance and extensibility. This approach allowed new models to be added without code changes, significantly reducing the risk of introducing bugs.
Protocol translation challenges – The most complex aspect was handling the subtle differences in streaming protocols between different models. Building a robust abstraction required careful consideration of edge cases and comprehensive error handling.
Error normalization – Creating a consistent error experience across diverse models required sophisticated error handling that could translate model-specific errors into user-friendly, actionable messages. This improved both developer and end-user experiences.
Type safety – Strong typing (using Python’s type hints extensively) was crucial for maintaining code quality across a complex codebase with multiple contributors. This practice reduced bugs and improved code maintainability.
Security first – Integrating Secrets Manager from the start made sure credentials were handled securely throughout the system’s lifecycle, helping prevent potential security vulnerabilities.
Conclusion
The collaboration between the AWS Generative AI Innovation Center and Quora demonstrates how thoughtful architectural design can dramatically accelerate AI deployment and innovation. By creating a unified wrapper API for Amazon Bedrock models, the teams were able to reduce deployment time from days to minutes while expanding model diversity and improving user experience.
This approach—focusing on abstraction, configuration-driven development, and robust error handling—offers valuable lessons for organizations looking to integrate multiple AI models efficiently. The patterns and techniques demonstrated in this solution can be applied to similar challenges across a wide range of AI integration scenarios.
For technology leaders and developers working on similar challenges, this case study highlights the value of investing in flexible integration frameworks rather than point-to-point integrations. The initial investment in building a robust abstraction layer pays dividends in long-term maintenance and capability expansion.
To learn more about implementing similar solutions, explore the following resources:
The AWS Generative AI Innovation Center and Quora teams continue to collaborate on enhancements to this framework, making sure Poe users have access to the latest and most capable AI models with minimal deployment delay.
About the authors
 Dr. Gilbert V Lepadatu is a Senior Deep Learning Architect at the AWS Generative AI Innovation Center, where he helps enterprise customers design and deploy scalable, cutting-edge GenAI solutions. With a PhD in Philosophy and dual Master’s degrees, he brings a holistic and interdisciplinary approach to data science and AI.
Dr. Gilbert V Lepadatu is a Senior Deep Learning Architect at the AWS Generative AI Innovation Center, where he helps enterprise customers design and deploy scalable, cutting-edge GenAI solutions. With a PhD in Philosophy and dual Master’s degrees, he brings a holistic and interdisciplinary approach to data science and AI.
 Nick Huber is the AI Ecosystem Lead for Poe (by Quora), where he is responsible for ensuring high-quality & timely integrations of the leading AI models onto the Poe platform.
Nick Huber is the AI Ecosystem Lead for Poe (by Quora), where he is responsible for ensuring high-quality & timely integrations of the leading AI models onto the Poe platform.