
On September 10, Smart Things reported that this morning, the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) in Abu Dhabi, in collaboration with AI startup G42, launched the new low-cost inference model K2 Think. The related paper has been published on the arXiv preprint platform, and the model was open-sourced on Hugging Face and GitHub yesterday afternoon.
K2 Think has 32 billion parameters and is built on Alibaba’s open-source model Qwen 2.5, performing better than flagship inference models from OpenAI and DeepSeek that have 20 times the parameter scale.
In the complex mathematical task benchmark tests, researchers calculated K2 Think’s average scores in AIME24, AIME25, HMMT25, and OMNI-Math-HARD, surpassing many open-source models including GPT-OSS, DeepSeek V3.1, and Qwen3 235B-A22B.
In the technical report, researchers mentioned that K2 Think is backed by six major technological innovations. They enhanced the foundational model’s reasoning capabilities through supervised fine-tuning, improved inference performance using Verifiable Reward Reinforcement Learning (RLVR), employed reasoning time technologyto enhance the model, and implemented two speed optimizations during K2-Think’s deployment, including speculative decodingand Cerebras wafer-scale chips, while training with publicly available open-source datasets.
Notably, researchers deployed K2-Think on the Cerebras wafer-scale chip WSE system, which can deliver about 2000 tokens per second, compared to the nominal 200 tokens per second observed in conventional deployment environments like NVIDIA H100/H200 GPUs, representing a tenfold performance improvement.

K2-Think is supported by two powerful backers: the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), an institution focused on AI research established by the UAE, and G42, a tech group backed by Abu Dhabi, which secured a $1.5 billion investment from Microsoft in 2024 and is constructing AI infrastructure called “Interstellar Gateway” in the UAE, jointly funded by companies like OpenAI and SoftBank.
The model’s weights, training data, deployment code, and testing optimization code have all been open-sourced on Hugging Face and GitHub.
Hugging Face link:
GitHub link:
K2 Think homepage:
Technical report:
https://arxiv.org/abs/2509.07604
1. Mathematical Performance Surpasses OpenAI and DeepSeek’s Open Models, Aiming to Provide Specialized Services for Mathematics and Science
Eric Xing, President and Chief AI Researcher at MBZUAI, revealed in an interview with WIRED that K2 Think was developed using thousands of GPUs, with the final training process involving 200 to 300 chips.
K2 Think is not a complete large language model; it is specifically designed for inference, capable of answering complex questions through simulated reasoning rather than quickly synthesizing information for output. Xing mentioned that they plan to integrate K2 Think into a complete large model in the coming months.
In the field of complex mathematics, K2 Think achieved an average score of 67.99 in four benchmark tests: AIME 2024, AIME 2025, HMMT 2025, and Omni-MATH-HARD, surpassing larger-scale models like DeepSeek V3.1 671B and GPT-OSS 120B.
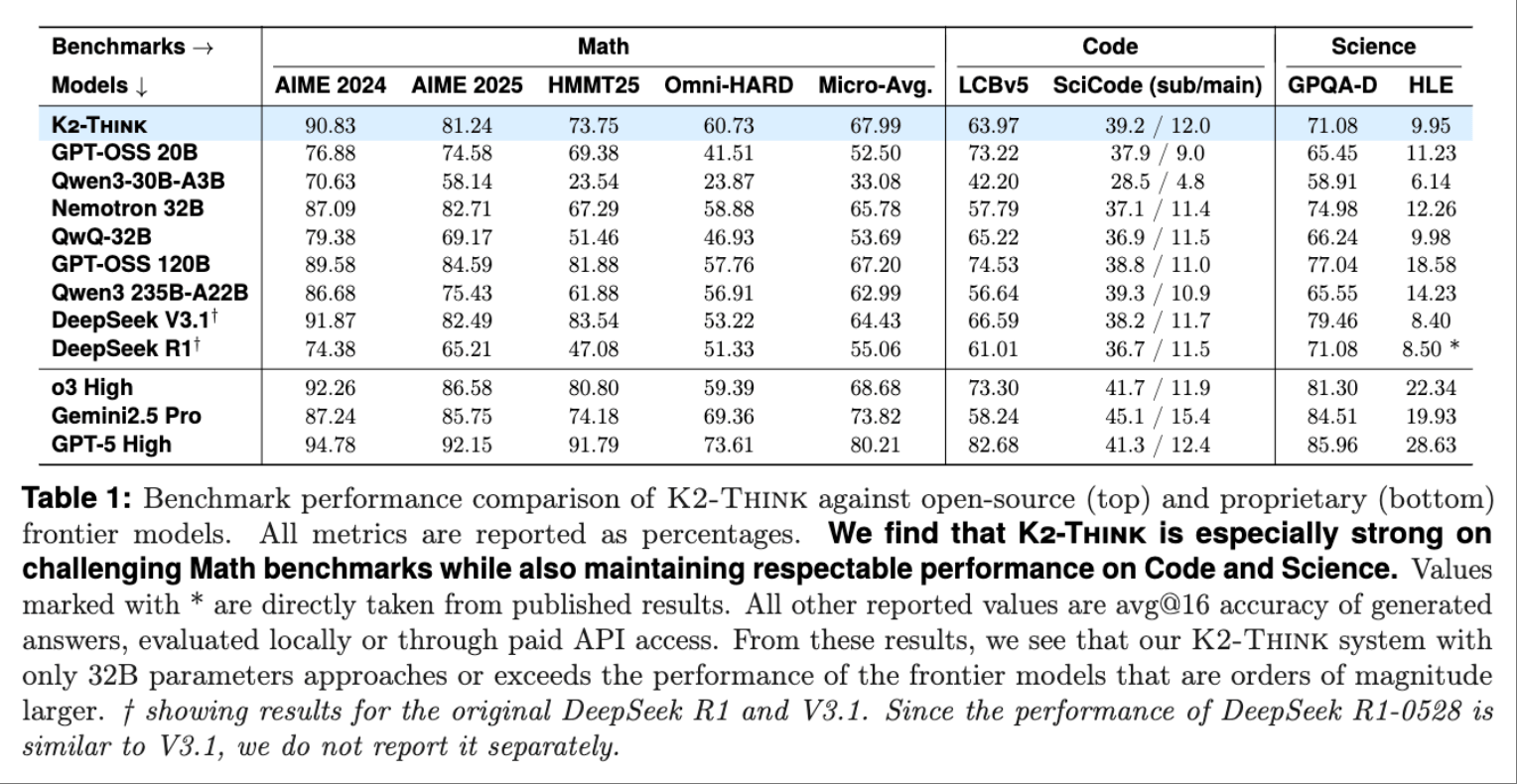
In terms of programming capabilities, K2-Think scored 63.97 on the open-source code capability benchmark LiveCodeBench, outperforming similarly sized models like GPT-OSS 20B and Qwen3-30B-A3B.
In the SciCode benchmark test, which assesses a large model’s ability to convert complex scientific problems into executable code, K2-Think achieved a score of 39.2, ranking second, just 0.1 points behind the first place model Qwen3 235BA22B.
In terms of scientific reasoning, the model scored 71.08 in the GPQA-Diamond benchmark test, outperforming most open-source models except for OpenReasoning-Nemotron-32B and GPT-OSS 120B.
Hector Liu, Director of the Basic Model Research Institute at MBZUAI, noted that K2-Think’s uniqueness lies in their viewing it as a system; their goal is not to build a chatbot similar to ChatGPT but to provide services for specific applications in fields like mathematics and science.
2. Six System-Level Innovations, Entire Training Process Using Open-Source Datasets
The technical report for K2-Think indicates six major technological innovations, including thinking chain supervised fine-tuning, verifiable reward reinforcement learning (RLVR), agent planning before reasoning, testing time expansion, speculative decoding, and reasoning-optimized hardware, all trained using publicly available open-source datasets.
Based on this systematic technological innovation, K2-Think enhanced logical depth through long-chain thinking supervised fine-tuning, improved accuracy in solving difficult problems through verifiable reward reinforcement learning, enabled the model to decompose complex challenges before reasoning through agent-style planning, and further enhanced the model’s adaptability through testing time expansion technology, ultimately achieving performance comparable to models with larger parameter scales. This enables the model to provide powerful thinking chain reasoning capabilities and near-instantaneous response times.
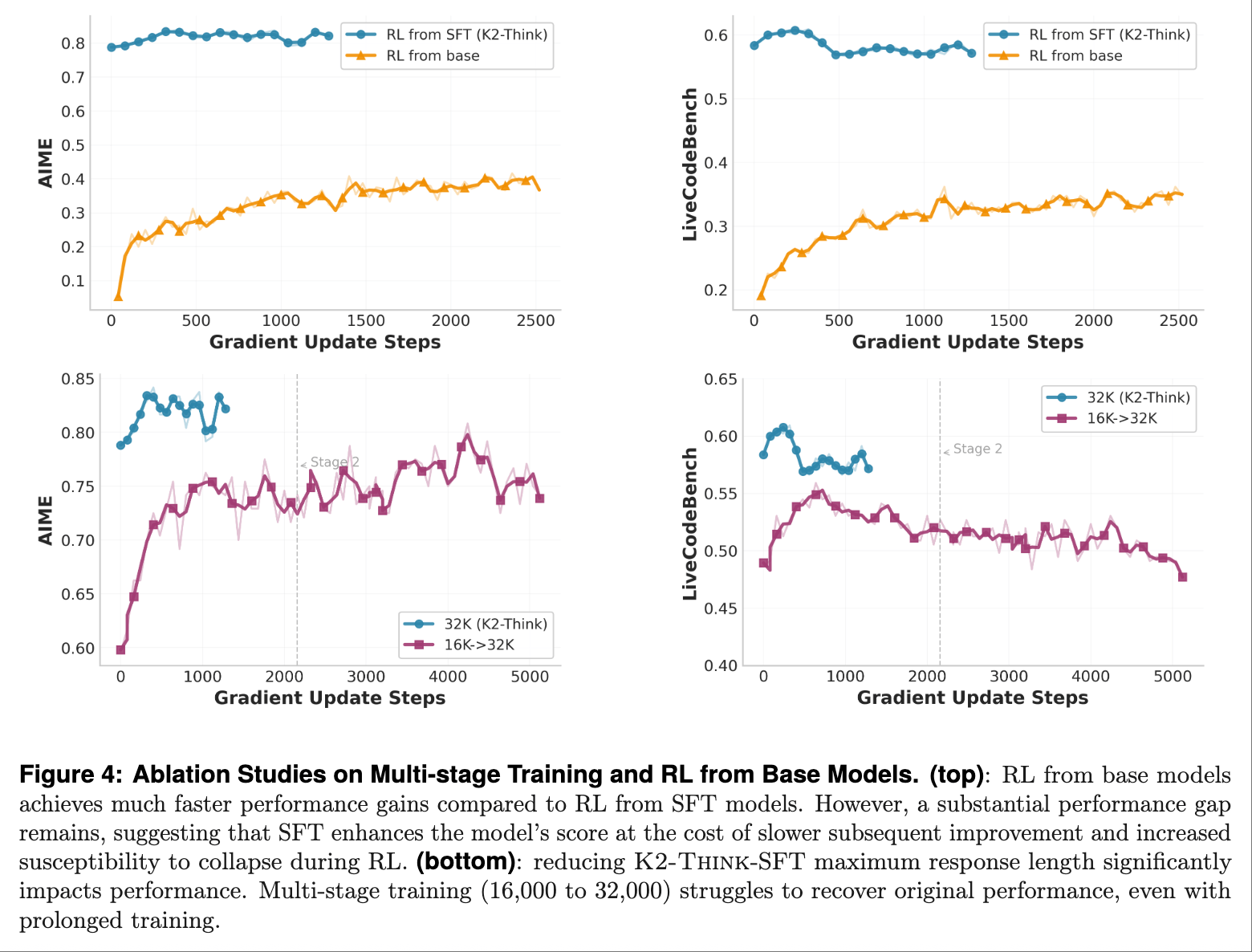
During the supervised fine-tuningphase, K2-Think used thinking chains to supervise fine-tune the foundational model. Researchers utilized the existing AM-Thinking-v1-Distilled dataset, which consists of CoT reasoning traces and instruction/response pairs, with prompts from tasks including mathematical reasoning, code generation, scientific reasoning, instruction following, and general chatting. They found that the SFT model outperformed the foundational model across various sampling budgets.
In the verifiable reward reinforcement learning phase, RLVR directly optimizes the correctness of the model’s outputs, reducing the complexity and cost associated with human feedback reinforcement learning (RLHF) based on preference alignment. Therefore, researchers used the Guru dataset, which includes tasks from six domains: mathematics, programming, science, logic, simulation, and tables, with nearly 92,000 verifiable questions.
In the testing time improvement phase, to further enhance model performance, researchers developed a testing time framework that provides structured input for the post-training reasoning model, including agent planning before reasoning, or “plan first, think later,” as well as testing time expansion using Best-of-N sampling.
▲ Information flow from input to final response
From input to final response, the model reconstructs prompts to outline the overall plan and highlight relevant concepts. This enhanced prompt is then used by the K2-Think model to generate multiple responses, which are finally compared pairwise to select the best generated result as the final output of the reasoning system.
The fourth phase is deployment. In challenging mathematical proofs or multi-step coding problems, a typical complex reasoning task usually generates a response of 32,000 tokens. On NVIDIA H100, this can be completed in less than 3 minutes, while on WSE, the same 32,000 token generation task only takes 16 seconds.
This is because GPUs must continuously transfer weights from high-bandwidth memory to GPU cores with each token generation, whereas WSE stores all model weights in massive chip memory, fully utilizing an on-chip memory bandwidth of 25PB per second, over 3000 times higher than the 0.008PB/s provided by the latest NVIDIA B200 GPUs.
Conclusion: Small Parameter Models Can Match Larger Parameter Models After Fine-Tuning
The performance of the K2-Think model demonstrates that a model with 32 billion parameters, after fine-tuning, can generate longer reasoning chains and, with relatively less testing time, can achieve capabilities comparable to models with significantly larger parameter counts.
Richard Morton, General Manager of the Basic Model Research Institute at MBZUAI, believes that the fundamental reasoning of the human brain is the basis of all thought processes. The application of K2-Think can shorten the time researchers take to think through specific tasks and conduct clinical trials, thereby expanding advanced AI technology to regions where AI infrastructure is scarce.返回搜狐,查看更多