

This year we’ve seen remarkable advances in agentic AI, including systems that conduct deep research, operate computers, complete substantial software engineering tasks, and tackle a range of other complex, multi-step goals. In each case, the industry relied on careful vertical integration: tools and agents were co-designed, co-trained, and tested together for peak performance. For example, OpenAI’s recent models presume the availability of web search and document retrieval tools (opens in new tab). Likewise, the prompts and actions of Magentic-One are set up to make hand-offs easy—for example, allowing the WebSurfer agent to pass downloaded files to the Coder agent. But as agents proliferate, we anticipate strategies relying heavily on vertical integration will not age well. Agents from different developers or companies will increasingly encounter each other and must work together to complete tasks, in what we refer to as a society of agents. These systems can vary in how coordinated they are, how aligned their goals are, and how much information they share. Can heterogenous agents and tools cooperate in this setting, or will they hinder one another and slow progress?
Early clues have emerged from an unexpected source: namely, Model Context Protocol (opens in new tab) (MCP). Since January 2025, MCP has grown from a promising spec to a thriving market of tool servers. As an example, Zapier boasts a catalog of 30,000 tools (opens in new tab) across 7,000 services. Composio provide over 100 managed MCP servers (opens in new tab), surfacing hundreds of tools. Hugging Face is now serving many Spaces apps over MCP (opens in new tab), and Shopify has enabled MCP for millions of storefronts (opens in new tab). A society of tools is already here, and it promises to extend agent capabilities through cross-provider horizontal integration.
So, what does MCP have to say about horizontal integration? As catalogs grow, we expect some new failure modes to surface. This blog post introduces these as tool-space interference, and sketches both early observations and some pragmatic interventions to keep the society we’re building from stepping on its own feet.
Tool-space interference describes situations where otherwise reasonable tools or agents, when co-present, reduce end-to-end effectiveness. This can look like longer action sequences, higher token cost, brittle recovery from errors, or, in some cases, task failure.
A framing example
Consider MCP as a means for extending Magentic-One, a generalist multi-agent system we released last year, to cover more software engineering tasks. Magentic-One ships with agents to write code, interact with the computer terminal, browse the web, and access local files. To help Magentic-One navigate version control, find issues to solve, and make pull requests, we could add an agent equipped with the GitHub MCP Server. However, now each time the team encounters a task involving GitHub, it must choose whether to visit github.com in the browser, execute a git command at the command line, or engage the GitHub MCP server. As the task progresses, agent understanding of state can also diverge: changing the branch in the browser won’t change the branch in the terminal, and an authorized MCP tool does not imply authorization in the browser. Thus, while any single agent might complete the task efficiently, the larger set of agents might misunderstand or interfere with one another, leading to additional rounds of debugging, or even complete task failure.

To better understand the potential interference patterns and the current state of the MCP ecosystem, we conducted a survey of MCP servers listed on two registries: smithery.ai (opens in new tab) and Docker MCP Hub (opens in new tab). Smithery is an MCP Server registry with over 7,000 first-party and community-contributed servers, which we sampled from the Smithery API. Likewise, Docker MCP Hub is a registry that distributes MCP servers as Docker images, and we manually collected popular entries. We then launched each server for inspection. After excluding servers that were empty or failed to launch, and deduplicating servers with identical features, 1,470 servers remained in our catalog.
To automate the inspection of running MCP servers, we developed an MCP Interviewer tool. The MCP Interviewer begins by cataloging the server’s tools, prompts, resources, resource templates, and capabilities. From this catalog we can compute descriptive statistics such as the number of tools, or the depth of the parameter schemas. Then, given the list of available tools, the interviewer uses an LLM (in our case, OpenAI’s GPT-4.1) to construct a functional testing plan that calls each tool at least once, collecting outputs, errors, and statistics along the way. Finally, the interviewer can also grade more qualitative criteria by using an LLM to apply purpose-built rubrics to tool schemas and tool call outputs. We are excited to release the MCP Interviewer as an open-source CLI tool (opens in new tab), so server developers can automatically evaluate their MCP servers with agent usability in mind, and users can validate new servers.
While our survey provides informative initial results, it also faces significant limitations, the most obvious of which is authorization: many of the most popular MCP servers provide access to services that require authorization to use, hindering automated analysis. We are often still able to collect static features from these servers but are limited in the functional testing that can be done.
One-size fits all (but some more than others)
So, what does our survey of MCP servers tell us about the MCP ecosystem? We will get into the numbers in a moment, but as we contemplate the statistics, there is one overarching theme to keep in mind: MCP servers do not know which clients or models they are working with, and present one common set of tools, prompts, and resources to everyone. However, some models handle long contexts and large tool spaces better than others (with diverging hard limits), and respond quite differently to common prompting patterns. For example, OpenAI’s guide on function calling (opens in new tab) advises developers to:
“Include examples and edge cases, especially to rectify any recurring failures. (Note: Adding examples may hurt performance for reasoning models).”
So already, this places MCP at a disadvantage over vertical integrations that optimize to the operating environment. And with that, let’s dive into more numbers.
Tool count
While models generally vary in their proficiency for tool calling, the general trend has been that performance drops as the number of tools increases. For example, OpenAI limits developers to 128 tools, but recommends (opens in new tab) that developers:
“Keep the number of functions small for higher accuracy. Evaluate your performance with different numbers of functions. Aim for fewer than 20 functions at any one time, though this is just a soft suggestion.”
While we expect this to improve with each new model generation, at present, large tool spaces can lower performance by up to 85% for some models (opens in new tab). Thankfully, the majority of servers in our survey contain four or fewer tools. But there are outliers: the largest MCP server we cataloged adds 256 distinct tools, while the 10 next-largest servers add more than 100 tools each. Further down the list we find popular servers like Playwright-MCP (opens in new tab) (29 tools, at the time of this writing), and GitHub MCP (91 tools, with subsets available at alternative endpoint URLs), which might be too large for some models.

Response length
Tools are generally called in agentic loops, where the output is then fed back into the model as input context. Models have hard limits on input context, but even within these limits, large contexts can drive costs up and performance down, so practical limits can be much lower (opens in new tab). MCP offers no guidance on how many tokens a tool call can produce, and the size of some responses can come as a surprise. In our analysis, we consider the 2,443 tool calls across 1,312 unique tools that the MCP Interviewer was able to call successfully during the active testing phase of server inspection. While a majority of tools produced 98 or fewer tokens (opens in new tab), some tools are extraordinarily heavyweight: the top tool returned an average of 557,766 tokens, which is enough to swamp the context windows of many popular models like GPT-5. Further down the list, we find that 16 tools produce more than 128,000 tokens, swamping GPT-4o and other popular models. Even when responses fit into the context window length, overly long responses can significantly degrade performance (up to 91% in one study (opens in new tab)), and limit the number of future calls that can be made. Of course, agents are free to implement their own context management strategies, but this behavior is left undefined in the MCP specification and server developers cannot count on any particular client behavior or strategy.

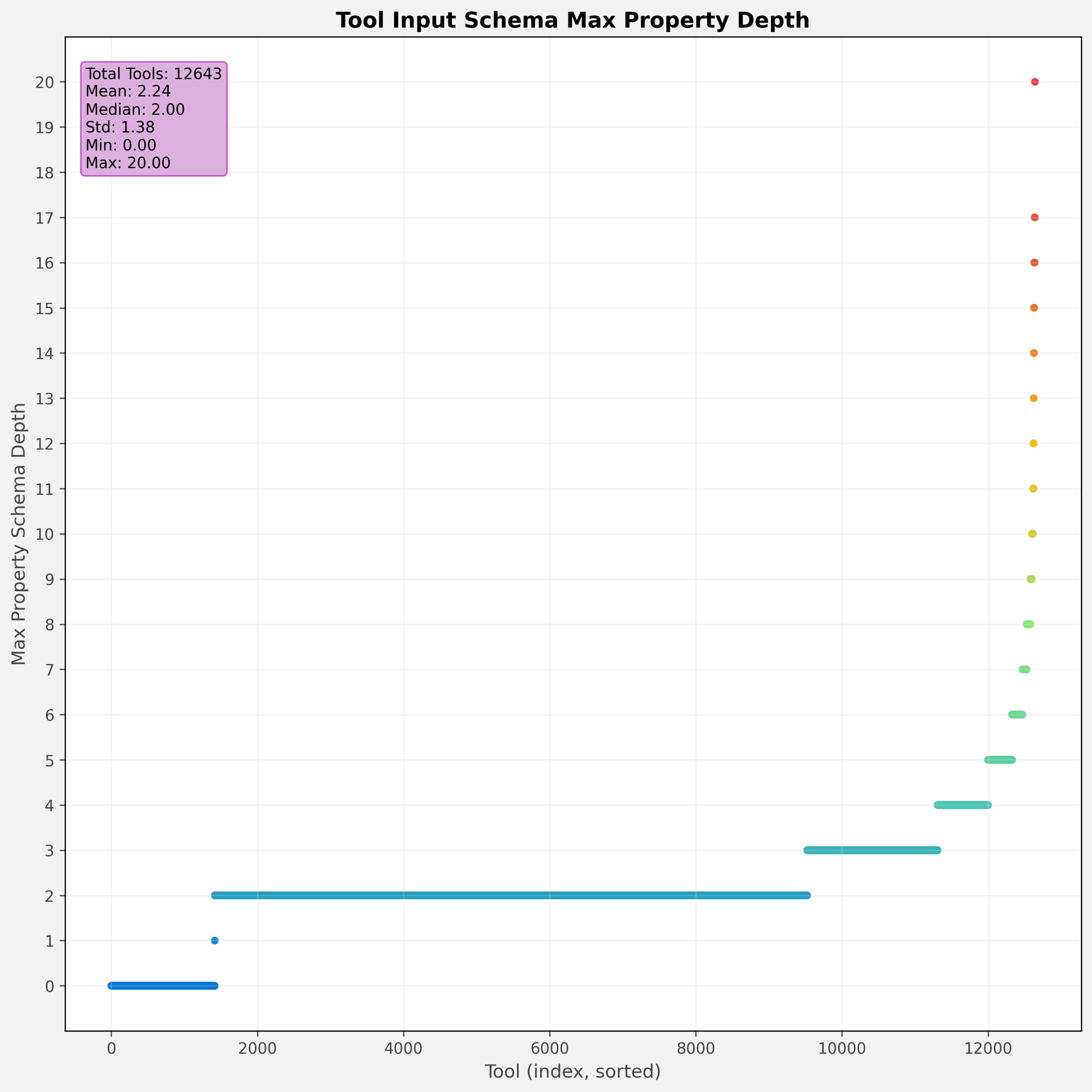
Tool parameter complexity
Mirroring the challenges from increasing the number of tools, increasing the complexity of a tool’s parameter space can also lead to degradation. For example, while MCP tools can take complex object types and structures as parameters, composio (opens in new tab) found that flattening the parameter space could improve tool-calling performance by 47% compared to baseline performance. In our analysis, we find numerous examples of deeply nested structure—in one case, going 20 levels deep.
Namespacing issues and naming ambiguity
Another often-cited issue with the current MCP specification is the lack of a formal namespace mechanism (opens in new tab). If two servers are registered to the same agent or application, and the servers have tool names in common, then disambiguation becomes impossible. Libraries like the OpenAI Agents SDK raise an error (opens in new tab) under this circumstance. Clients, like Claude Code, prefix tool names with unique identifiers to work around this issue. In our analysis of MCP servers, we found name collisions between 775 tools. The most common collision was “search”, which appears across 32 distinct MCP servers. The following table lists the top 10 collisions.
Even when names are unique, they can be semantically similar. If these tools behave similarly, then the redundancy may not be immediately problematic, but if you are expecting to call a particular tool then the name similarities raise the potential for confusion. The following table lists some examples of semantically similar tool names relating to web search:
Errors and error messages
Like all software libraries, MCP will occasionally encounter error conditions. In these cases, it is important to provide sufficient information for the agent to handle the error and plan next steps. In our analysis, we found this was not always the case. While MCP provides an “IsError” flag to signal errors, we found that it was common for servers to handle errors by returning strings while leaving this flag set to false, signaling a normal exit. Out of 5,983 tool call results with no error flag, GPT-4.1 judged that 3,536 indicated errors in their content. More worrisome: the error messages were often of low quality. For instance, one tool providing web search capabilities failed with the string “error: job,” while another tool providing academic search returned “Please retry with 0 or fewer IDs.”
Resource sharing conventions
Finally, in addition to tools, MCP allows servers to share resources and resource templates with clients. In our survey, only 112 (7.6%) servers reported any resources, while 74 (5%) provided templates. One potential reason for low adoption is that the current MCP specification provides limited guidance for when resources are retrieved, or how they are incorporated into context. One clearcut situation where a client might retrieve a resource is in response to a tool returning a resource_link (opens in new tab) as a result — but only 4 tools exhibited this behavior in our survey (arguably, this would be the ideal behavior for tools that return very long, document-like responses, as outlined earlier).
Conversely, a whole different set of issues arises when there is a need to share resources from the client to the server. Consider for example a tool that provides some analysis of a local PDF file. In the case of a local MCP server utilizing STDIO transport, a local file path can be provided as an argument to the tool, but no similar conventions exist for delivering a local file to a remote MCP server. These issues are challenging enough when implementing a single server. When multiple tools or servers need to interact within the same system, the risk of interoperability errors compounds.
Recommendations
On balance, along any given dimension, the average MCP server is quite reasonable—but, as we have seen, outliers and diverging assumptions can introduce trouble. While we expect many of these challenges to improve with time, we are comfortable making small recommendations that we feel are evergreen. We organize them below by audience.
Protocol developers
We recognize the advantages of keeping MCP relatively lightweight, avoiding being overly prescriptive in an environment where AI models and use cases are rapidly changing. However, a few small recommendations are warranted. First, we believe MCP should be extended to include a specification for client-provided resources so that tools on remote servers have a mechanism for operating on specified local files or documents. This would more effectively position MCP as a clearinghouse for resources passed between steps of agentic workflows. The MCP specification would also benefit from taking a more opinionated stance on when resources are retrieved and used overall.
Likewise, we believe MCP should quickly move to provide formal namespaces to eliminate tool name collisions. If namespaces are hierarchical, then this also provides a way of organizing large catalogs of functions into thematically related tool sets. Tool sets, as an organizing principle, are already showing some promise in GitHub MCP Server’s dynamic tool discovery, (opens in new tab) and VS Code’s tool grouping (with virtual tools) (opens in new tab), where agents or users can enable and disable tools as needed. In the future, a standardized mechanism for grouping tools would allow clients to engage in hierarchical tool-calling, where they first select a category, then select a tool, without needing to keep all possible tools in context.
Server developers
While our MCP Interviewer tool can catalog many outward-facing properties of MCP servers, developers are often in a much better position to characterize the nature of their tools. To this end, we believe developers should publish an MCP Server card alongside their servers or services, clearly outlining the runtime characteristics of the tools (e.g., the expected number of tokens generated, or expected latency of a tool call). Ideally developers should also indicate which models, agents and clients the server was tested with, how the tools were tested (e.g., provide sample tasks), list any known incompatibilities, and be mindful of limitations of various models throughout development.
Client developers
Client developers have the opportunity to experiment with various mitigations or optimizations that might help the average MCP server work better for a given system or environment. For example, clients could cache tool schemas, serving them as targets for prompt optimizations, or as an index for RAG-like tool selection approaches. To this end, Anthropic recently reported using a tool testing agent (opens in new tab) to rewrite the prompts of defective MCP servers, improving task completion time by 40%. Likewise, rather than waiting for the protocol to evolve, clients could take proactive steps to resolve name collisions— for example, generating namespaces from server names—and could reduce token outputs by summarizing or paginating long tool results.
Market developers
Finally, we see an opportunity for marketplaces to codify best-practices, spot compatibility issues at a global level, and perhaps centralize the generation and serving of model or agent-specific optimizations. Mirroring how a market like PyPI distributes Python wheels matched to a developer’s operating system or processor (opens in new tab), an MCP marketplace could serve tool schemas optimized for a developer’s chosen LLM, agent or client library. We are already seeing small steps in this direction, with registries like Smithery providing customized launch configurations to match users’ clients.
Conclusion
In summary, the MCP ecosystem offers significant value for AI agent development, despite some early growing pains. Grounded in insights from the MCP Interviewer (opens in new tab) and our survey of live servers, the evidence is clear: horizontal integration is expanding capability, yet it also exposes forms of toolspace interference that can erode end to end effectiveness. Anticipating rapid advances in model capability and growing architectural diversity, the recommendations provided here aim to ensure that protocol, server, client, and marketplace developers are well positioned to adapt and thrive. Key steps include implementing formal namespaces to eliminate collisions, enhancing protocol support for client provided resources, and encouraging transparent server documentation to foster interoperability and robust development practices across the ecosystem.
By embracing these evergreen recommendations and proactively addressing compatibility, usability, and optimization issues, the AI agent community can create a more reliable, scalable, and efficient infrastructure that benefits both developers and end users. The future of MCP is bright, with ample opportunities for experimentation, standardization, and collective progress.