
What started as a gold rush in AI-powered coding may be turning into a money pit, offering a preview of challenges awaiting other AI agent categories.
Companies that hit $100M+ ARR in months, like Anysphere (maker of Cursor) and Lovable, now face LLM inference costs growing up to 20x, forcing rate limits and price hikes, and putting reverse acqui-hires (hiring founders and licensing the tech) on the table as some founders seek exits.
Using CB Insights’ data on company momentum, exit probabilities, and customer sentiment, we analyzed how the coding AI market is adapting to this economic shock and what other AI agent companies (and their backers) can learn:
Reasoning models spark vibe coding’s explosive growth
Reasoning token shock pushes adoption of new pricing models
Margin pressure drives consolidation of talent in the coding AI agents market
Open models and usage-based pricing offer solutions to the market’s current challenges
Reasoning models spark vibe coding’s explosive growth
The coding AI agents and copilots market has been on a roll, generating an estimated $1.1B in revenue in 2024 and minting unicorns in as little as 6 months, which is 4x faster than the AI industry average.
Anthropic’s release of Claude 3.5 Sonnet in June 2024 has primarily driven this early momentum. This technology helped developers transition from autocomplete to partial delegation of coding tasks with a model that could reliably call tools and handle multi-file edits.
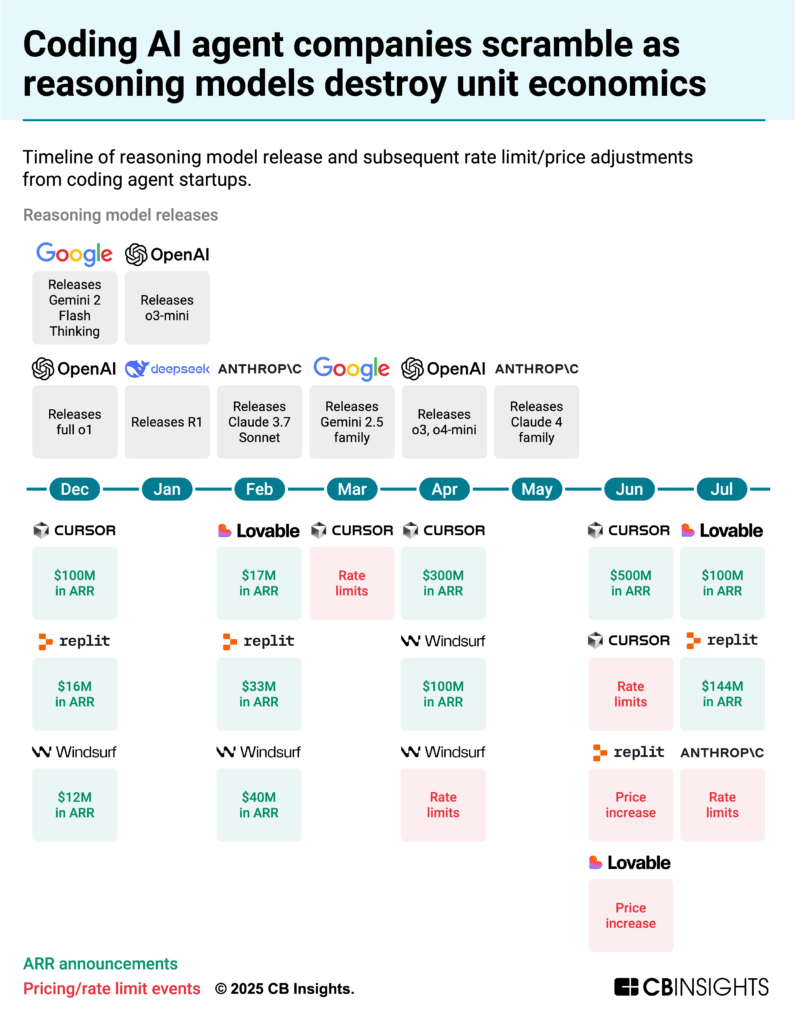
But it is the emergence of reasoning models, and specifically Anthropic’s Claude 3.7 Sonnet’s reasoning mode in February 2025, that made vibe coding possible — giving a high‑level goal and delegating multi‑step implementation to the AI. Developers could now set goals like “make this component responsive” or “add error handling throughout” and let the AI plan and execute the changes, sparking explosive growth in the space:
Anysphere’s ARR grew 5x in 6 months, from $100M in December 2024 to $500M in June 2025.
Replit’s ARR increased from $10M at the end of 2024 to $144M in July 2025.
Lovable became one of the fastest-growing software startups, reaching $100M in ARR just 8 months after launching.
![]() See all coding AI agent companies ranked by revenue
See all coding AI agent companies ranked by revenue
Reasoning token shock pushes adoption of new pricing models
As revenue surged on the back of reasoning, costs rose even faster.
Reasoning models inflate output‑token volume roughly 20x, according to Artificial Analysis. Because inference is billed per token — and output tokens are typically priced higher than input — that surge translates directly into higher compute cost. Anthropic’s May 2025 step‑ups on Sonnet 4 and Opus 4 (priced at roughly 5x prior models) added further pressure just as adoption was accelerating.
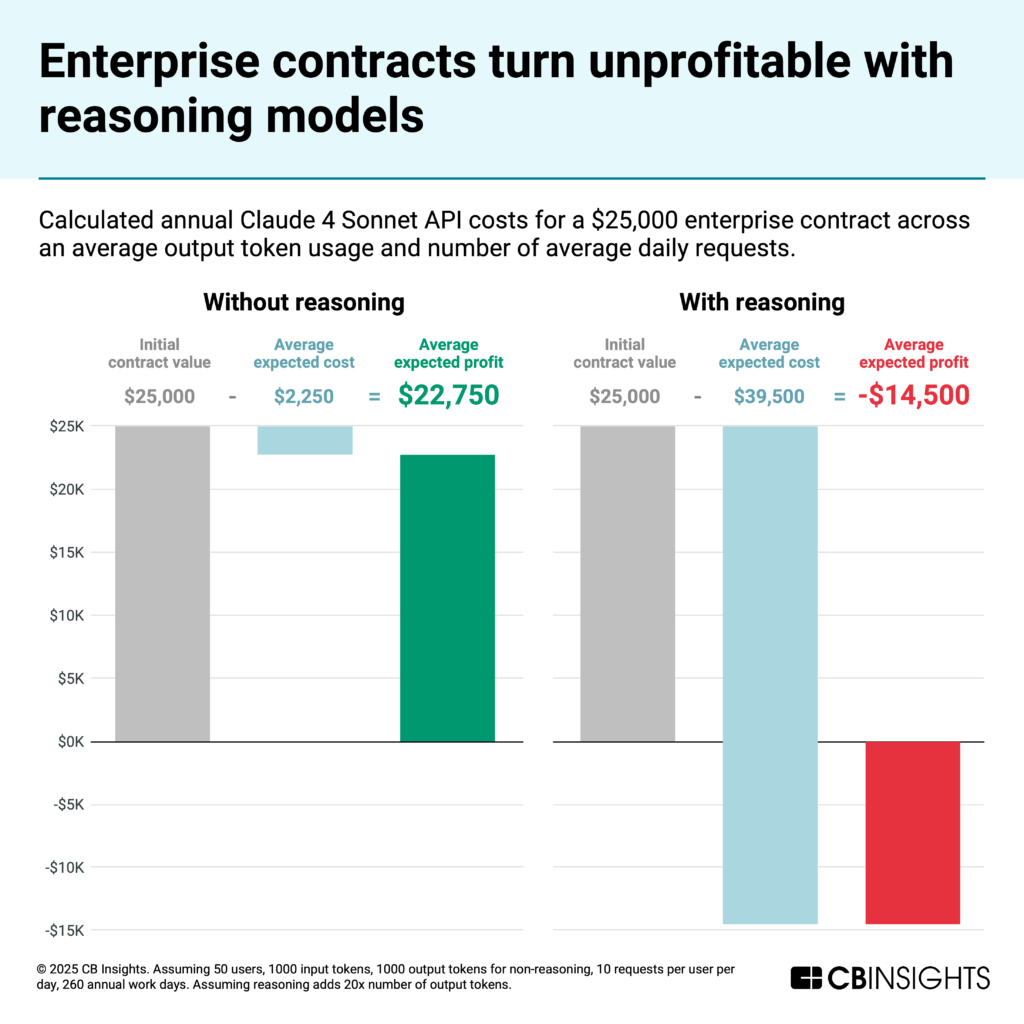
This is particularly impacting enterprise deals, which businesses often negotiate on an annual, per‑seat basis. That structure leaves vendors carrying the risk of uncapped compute costs while revenue stays fixed.
Using CB Insights Customer Sentiment data, we find most contracts fall between roughly $6K and $100K a year, with a median around $25K for a 50‑developer team. While margins once sat at 80%-90% on these contracts, compute costs from reasoning models can flip margins deeply negative.
The strain showed up quickly. Cursor tightened rate limits and introduced overage charges despite crossing $500M in ARR, prompting backlash and refunds. Anthropic throttled Claude Code after individual users exceeded $10K in monthly compute on $200 plans.
Vendors are shifting to pass‑through and usage‑based pricing to align revenue with compute cost. Companies employing usage‑based approaches show stronger momentum in our Mosaic data (median Momentum Mosaic of 683 vs. 671 for the broader market), but enterprise buyers are pushing back on variable bills and month‑to‑month swings.
Expect coding AI agent vendors to adapt pricing and GTM: moving to seat‑plus‑usage hybrids, stricter per‑seat compute guardrails, and model tiering that reserves reasoning for high‑impact work. ARR growth will moderate as flat‑fee expansion gives way to usage‑aligned pricing.
Margin pressure drives consolidation of talent in the coding AI agents market
Reasoning-driven margin compression is forcing consolidation in a category that has seen dozens of new entrants over the past 12 months.
Traditional acquisitions aren’t off the table, but acqui‑hires and reverse acqui‑hires have become the most active exit structures recently — albeit with trade‑offs.
OpenAI and Anthropic have logged 3 acqui‑hires since early 2025. Across AI, recent moves (e.g., Microsoft–Inflection AI, Amazon–Adept, and Meta–Scale) signal a tilt to talent‑plus‑license amid potential antitrust scrutiny. In coding AI agents, Windsurf’s failed sale and Google’s follow‑on reverse acqui-hire underscore the pattern of buyers taking teams and leaving products behind.
In these deals, acquirers hire the team and license the tech, leaving customer contracts and infrastructure — and the associated compute liabilities — outside the transaction. What they’re buying isn’t raw model IP; they’re buying proven operators with successful track records.
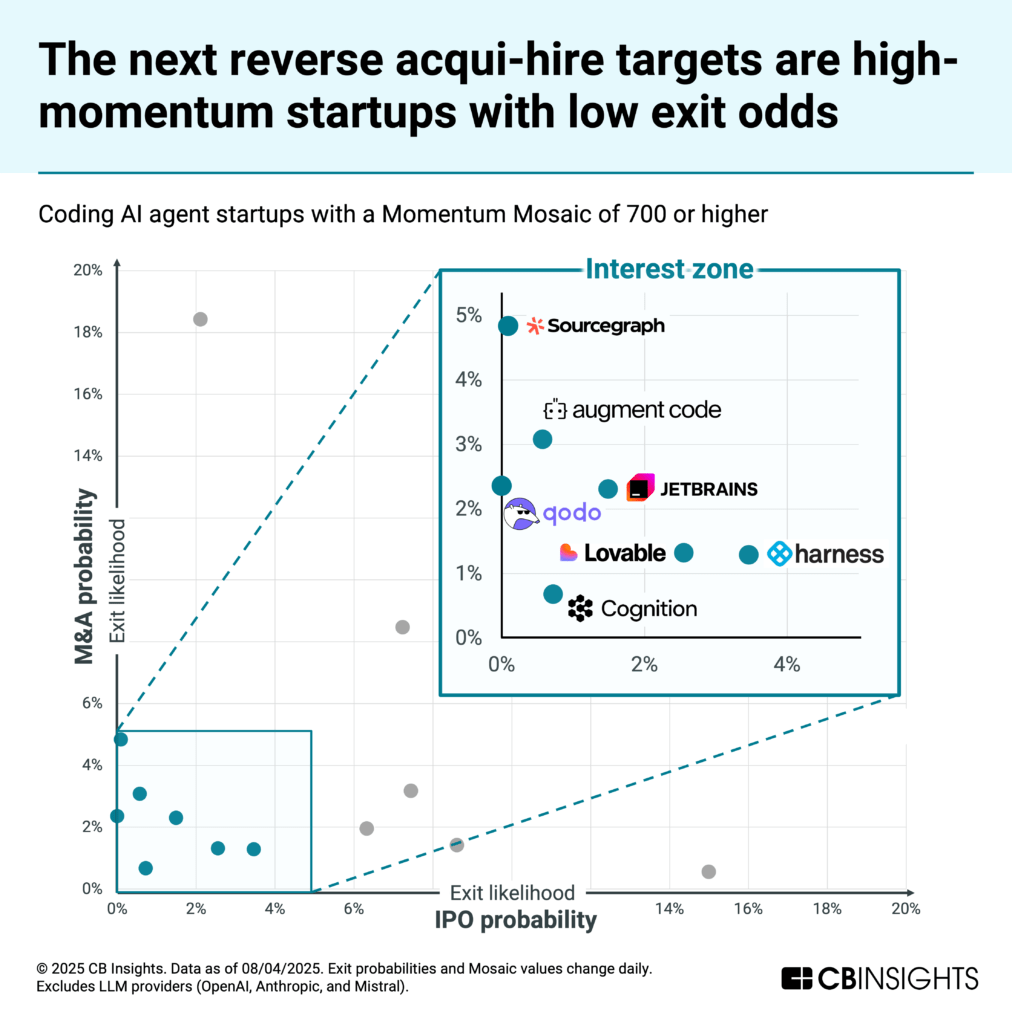
CB Insights’ exit probability analysis points to the next likely targets: companies with high Momentum Mosaic scores but lower probabilities of traditional exits.
The likely cause: private‑market valuations have outrun what strategics or public investors will pay given reasoning‑driven margin pressure, product overlap, and antitrust scrutiny — making full‑company M&A or near‑term IPOs harder to underwrite.
Seven stand out as potential targets: Sourcegraph, Augment Code, JetBrains, Qodo, Lovable, Cognition, and Harness.
Expect more reverse acqui-hire deals over the next few quarters as big tech continues to push for talent while coding AI agent companies struggle under margin pressures.
Open models and usage-based pricing offer solutions to the market’s current challenges
Against that backdrop, two levers dominate today: open models and usage‑aligned pricing. Here’s how each is playing out — and where it falls short.
Open models cut costs, but enterprise requirements slow adoption
Moonshot AI’s Kimi K2, Alibaba’s Qwen-Coder, and Z.ai’s GLM-4.5 approach Claude on coding tasks at a fraction of the cost, and OpenAI’s gpt‑oss goes a step further by offering a model that can run on consumer hardware.
Yet users need to access these models either through self-hosting or a third party. For enterprises, that means fresh security reviews, stringent uptime service level agreements (SLAs), multi-hour agent-run testing, and new infrastructure to manage.
The result is slower adoption, especially for six‑figure contracts that expect Claude‑level reliability.
Usage-based pricing fixes vendor margins, but most enterprises resist variable bills
Buyers tell us that token-metered pricing is difficult to budget, and expectations around costs for these tools are already set. CFOs want to anchor budgets and avoid month-to-month swings tied to release cycles, while usage-based pricing is the exact opposite.

In the near term, expect a shift from per‑message metering to effort‑based task pricing: agents quote a fixed rate for a defined outcome (e.g., “add error handling across this service” or “convert this component to TypeScript”), bundling planning, tool calls, and verification into a single charge with a visible pre‑estimate. Tasks are tiered (S/M/L) with caps on reasoning usage and admin‑approved overages, giving CFOs predictable bills while keeping compute under control.
This dynamic won’t be limited to coding
Other agent categories with surging usage are likely to rework pricing and contracts as reasoning costs mount.
Customer service is already operating on usage/outcome models. For example, in May 2025, Salesforce’s Agentforce shifted prices from $2 per conversation to a hybrid-usage Flex Credits system, tying credits to necessary actions for an outcome. Zendesk did a similar shift in pricing strategy in November 2024. Yet reasoning‑heavy workloads still create margin risk when the compute to achieve a resolution outstrips the value captured.
Beyond customer service, expect similar recalibrations across legal, healthcare, and sales agents. Outcome‑ or usage‑based models don’t fully eliminate compute risk. Explosive top‑line growth can mask deteriorating unit economics as reasoning workloads scale, and recent mega‑rounds may not be enough to foot the bill. Many players will reprice, add stricter usage guardrails, or raise additional capital to stay in the game.
If you are a coding AI agent startup and want to submit your company’s revenue data, please reach out to researchanalyst@cbinsights.com.
RELATED RESOURCES FROM CB INSIGHTS:
For information on reprint rights or other inquiries, please contact reprints@cbinsights.com.
If you aren’t already a client, sign up for a free trial to learn more about our platform.