
Tencent’s Hunyuan World Model has been updated, achieving a top position in the WorldScore rankings with its comprehensive capabilities. HunyuanWorld-Voyager (abbreviated as Hunyuan Voyager)is open source upon release. This comes just two weeks after the release of HunyuanWorld 1.0 Lite version.
The official introduction states that this is the industry’s first super-long roaming world model supporting native 3D reconstruction, capable of generating long-distance, globally consistentroaming scenes, and supports directly exporting videos into 3D formats.
Or pixel games:
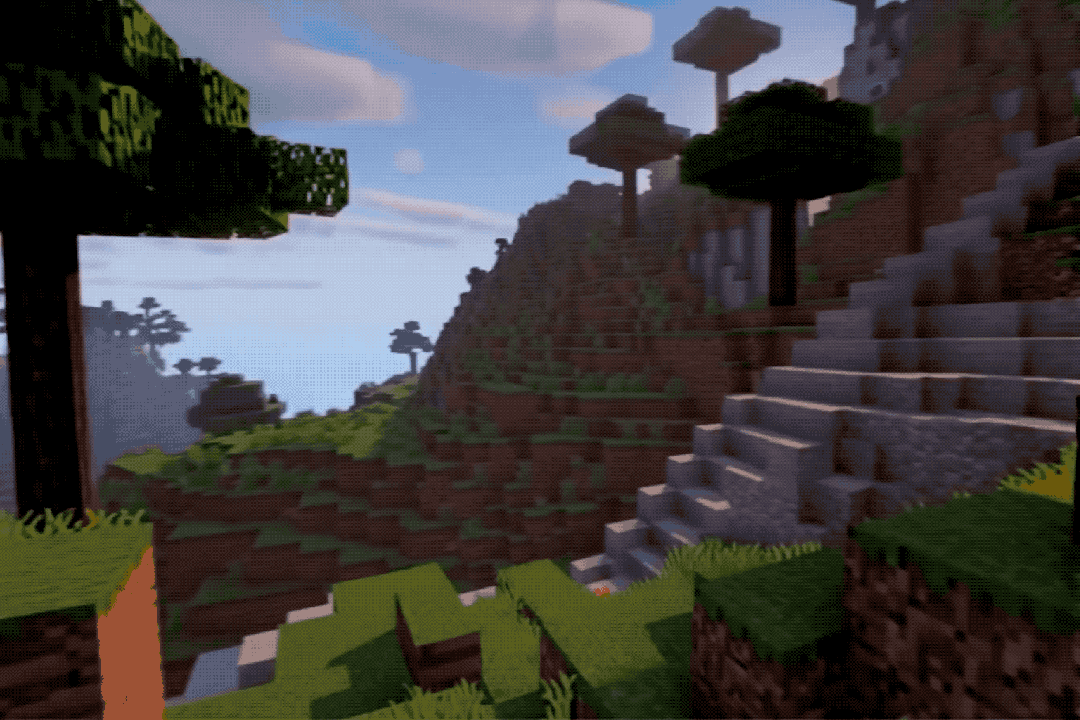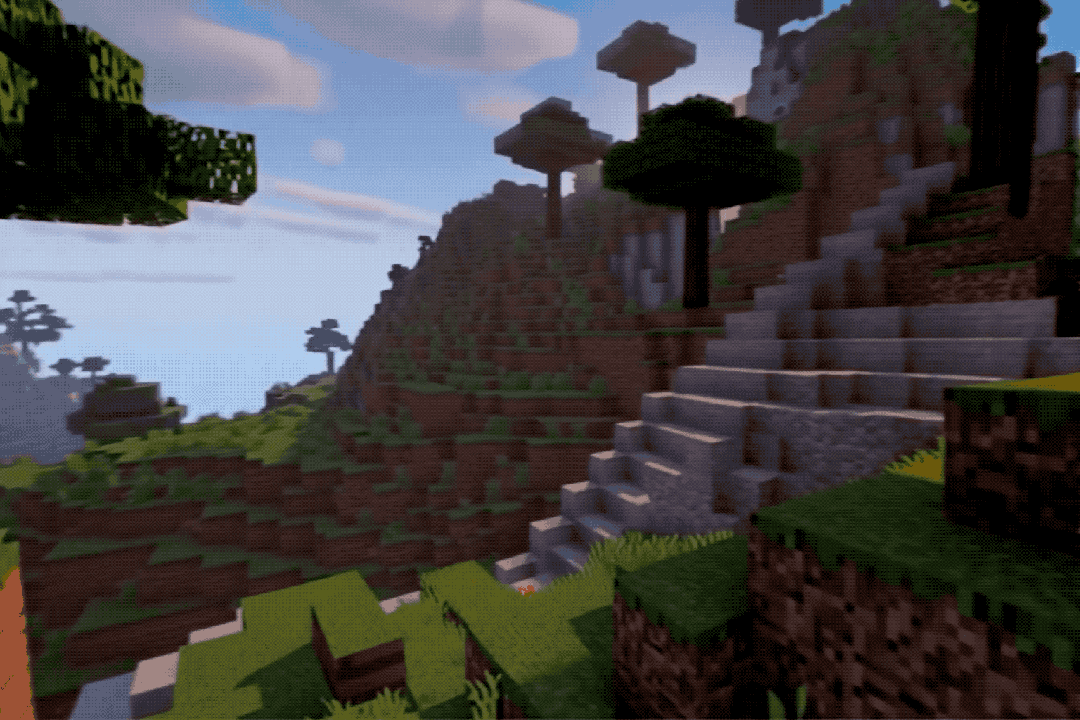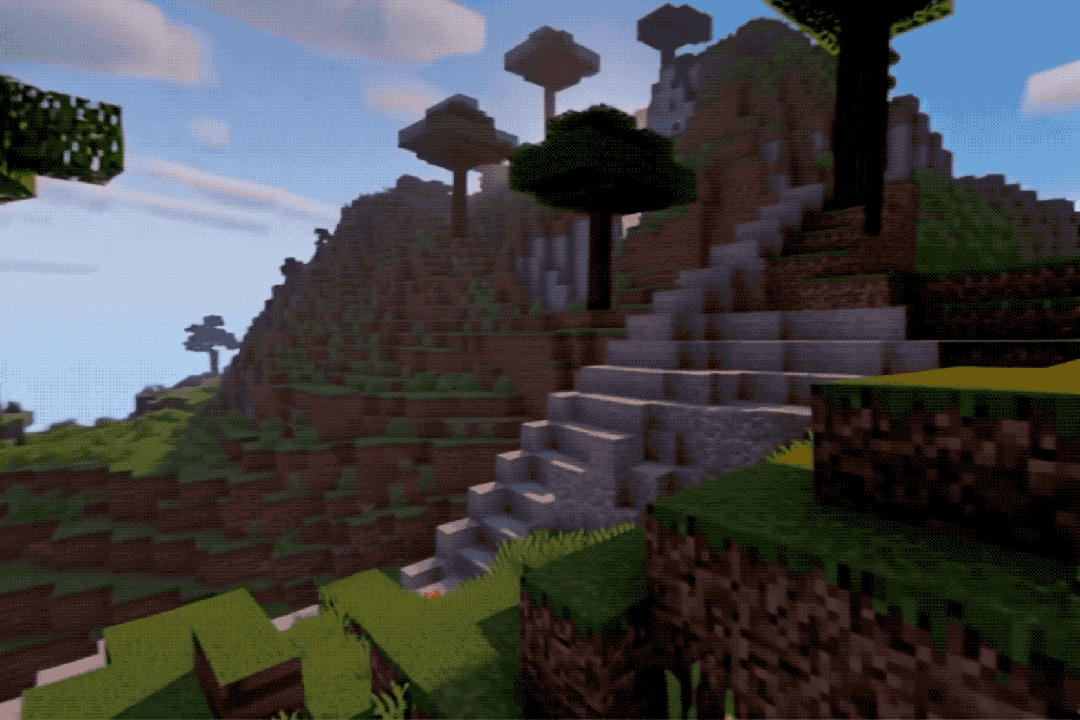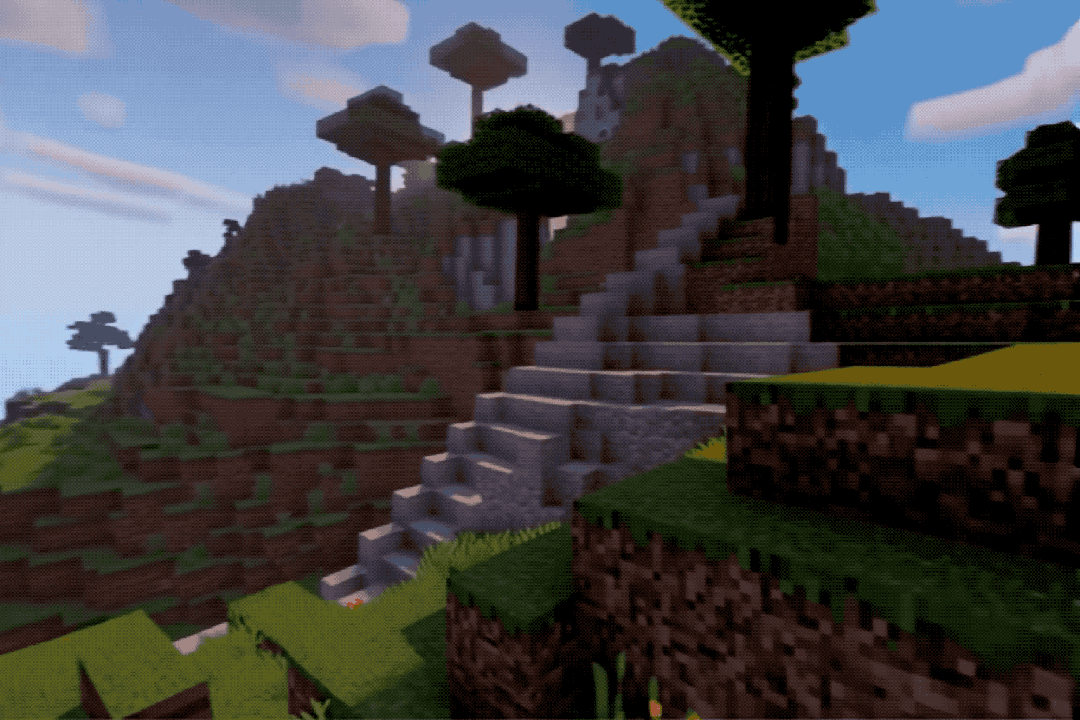
The effects are quite impressive; one might mistake them for real footage or screen recordings.
How does it differ from previous models? Let’s take a look.
One sentence, one image, one scene
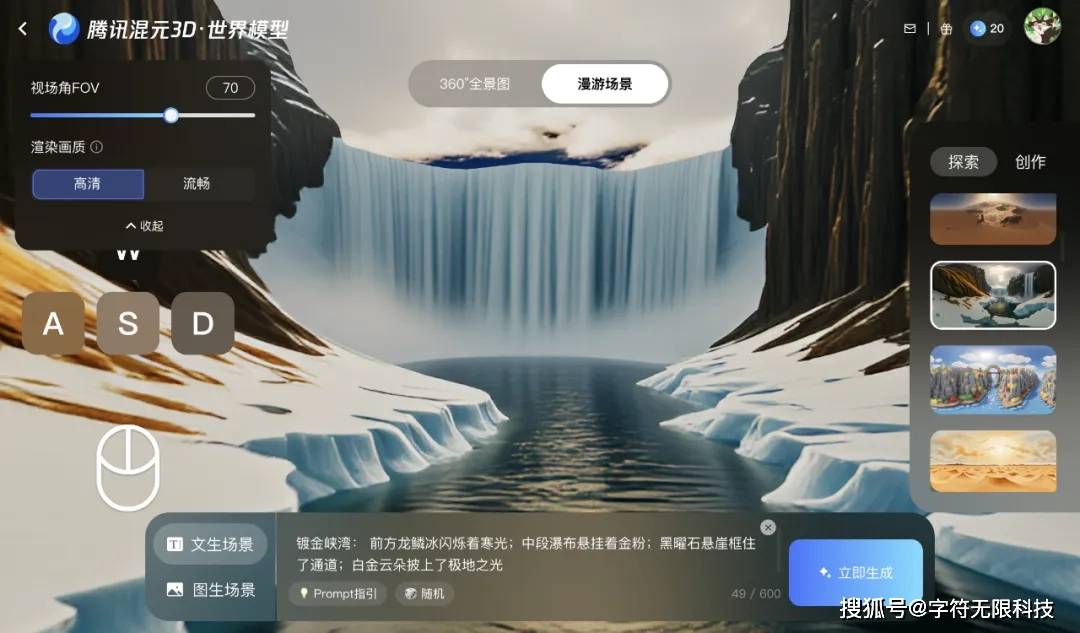
Upon reviewing the introduction of Hunyuan Voyager, the intuitive performance added this time is actually a feature for “roaming scenes”.
It offers stronger interactivity than 360° panoramic images, allowing users to navigate within the scene using the mouse and keyboard, providing a better experience to explore the world.

The left side allows adjustments for rendering quality and field of view:

Recording GIFs compress the quality, but the actual experience is quite clear.
Moreover, such scenes can be generated with just a sentence or an image.
The Hunyuan team also provided prompt guidelines:
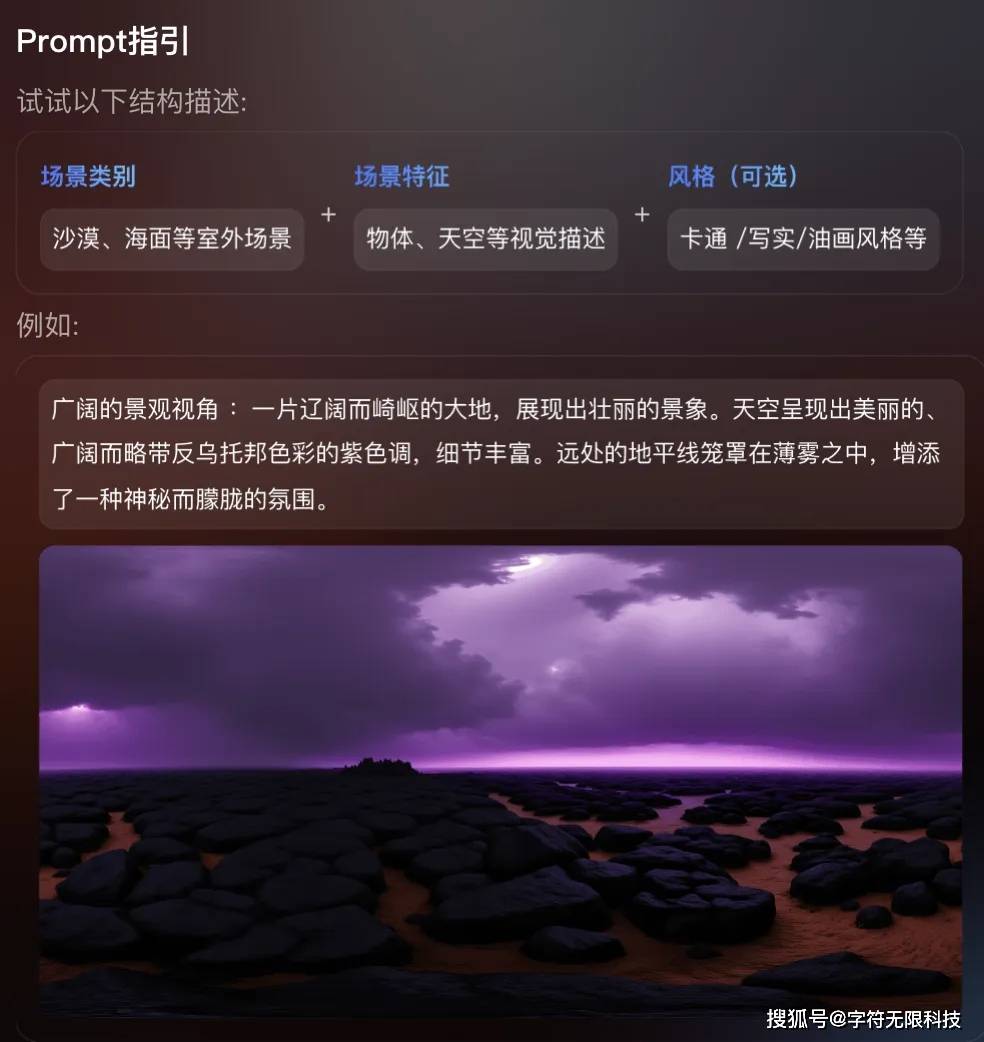
The example effects provided are also quite impressive, offering a great experience, making one even want to try it with VR glasses.

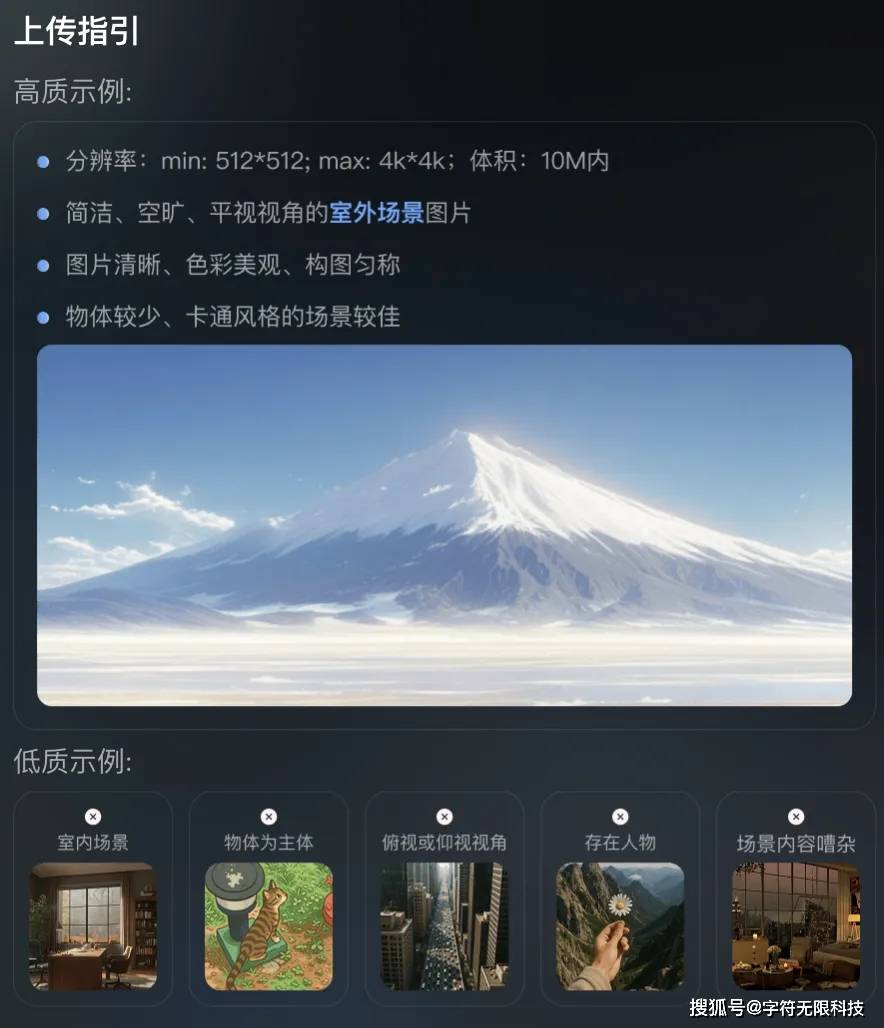
Due to file size limitations, it has been compressed multiple times; here’s a screenshot showing the original quality:
By the way, there are resolution requirements for images used to generate scenes; if they are too large or too small, an error will occur.


Specific requirements have also been clearly outlined:
Additionally, the Hunyuan Voyager’s 3D input – 3D outputfeature is highly compatible with the previously open-sourced Hunyuan World Model 1.0, allowing for further expansion of the roaming range of the 1.0 model, enhancing the generation quality of complex scenes, and enabling stylized control and editing of the generated scenes.

At the same time, Hunyuan Voyager supports various applications in 3D understanding and generation, including video scene reconstruction, 3D object texture generation, customized video style generation, and video depth estimation, showcasing the potential of spatial intelligence.

Introducing scene depth prediction into the video generation process
Why can Hunyuan Voyager achieve one-click generation of immersive roaming scenes? This question relates to its model framework.

Hunyuan Voyager innovatively integrates scene depth prediction into the video generation process, supporting native 3D memory and scene reconstruction for the first time through a combination of spatial and feature methods, avoiding the delays and accuracy losses caused by traditional post-processing.
Additionally, adding 3D conditions at the input end ensures accurate viewing angles, while directly generating 3D point clouds at the output end, adapting to various application scenarios. The extra depth information can also support functions like video scene reconstruction, 3D object texture generation, stylized editing, and depth estimation.
In simpler terms, video generation + 3D modeling — based on camera-controllable video generation technology, synthesizes RGB-D videos that can be freely controlled in perspective and spatial coherence from the initial scene view and user-specified camera trajectory.
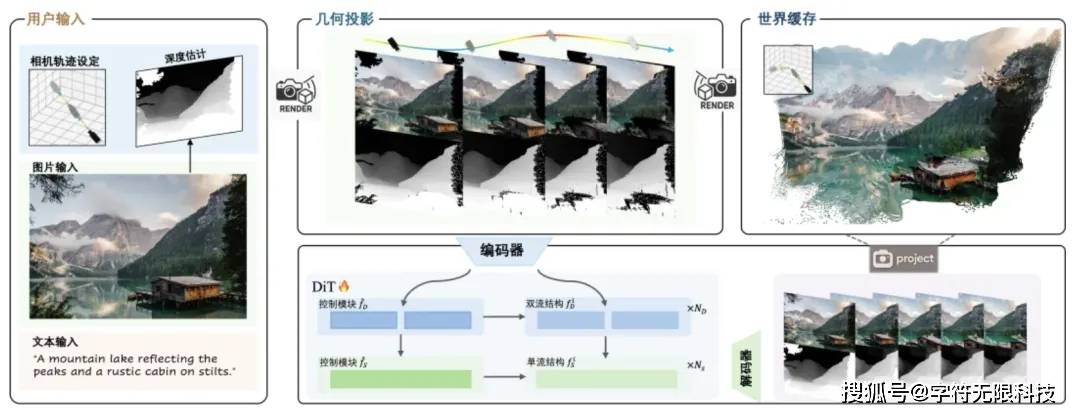
Hunyuan Voyager consists of two key components:
(1) World-consistent video diffusion:proposes a unified architecture that can generate precisely aligned RGB video and depth video sequences based on existing world observations, ensuring global scene consistency.
(2) Long-distance world exploration:proposes an efficient world caching mechanism that integrates point cloud pruning with autoregressive inference capabilities, supporting iterative scene expansion and achieving smooth video sampling through context-aware consistency techniques.
To train the Hunyuan Voyager model, the Tencent Hunyuan team has also built a scalable data construction engine— an automated video reconstruction pipeline that can automatically estimate camera poses and measure depth for any input video, allowing for large-scale, diverse training data construction without relying on manual labeling.
Based on this pipeline, Hunyuan Voyager integrates video resources collected from the real world and rendered from the Unreal Engine, constructing a large-scale dataset containing over 100,000video clips.
The initial 3D point cloud cache generated from the 1.0 model is projected onto the target camera view to guide the diffusion model.
Moreover, the generated video frames will also update the cache in real-time, forming a closed-loop system that supports any camera trajectory while maintaining geometric consistency. This not only expands the roaming range but also supplements the 1.0 model with new perspective content, enhancing overall generation quality.
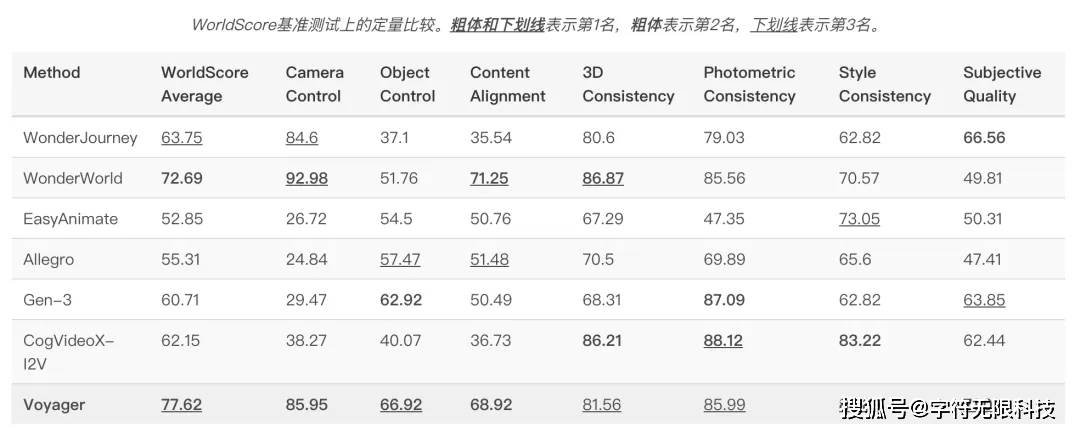
The Hunyuan Voyager model ranks first in comprehensive capabilitieson the WorldScore benchmark test released by Stanford University’s Fei-Fei Li team, surpassing existing open-source methods.
This result indicates that, compared to 3D-based methods, Hunyuan Voyager demonstrates superior competitiveness in camera motion control and spatial consistency.
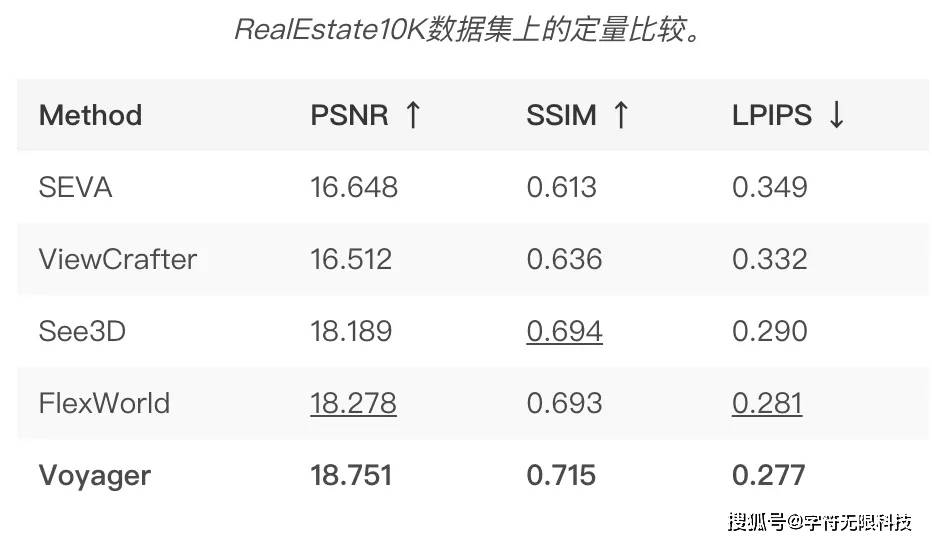

In terms of video generation quality, qualitative and quantitative results show that Hunyuan Voyager possesses exceptional video generation quality, capable of producing highly realistic video sequences.
Especially in the last set of qualitative comparisons, only Hunyuan Voyager effectively retained the detailed features of the products in the input images. In contrast, other methods tend to produce obvious artifacts.

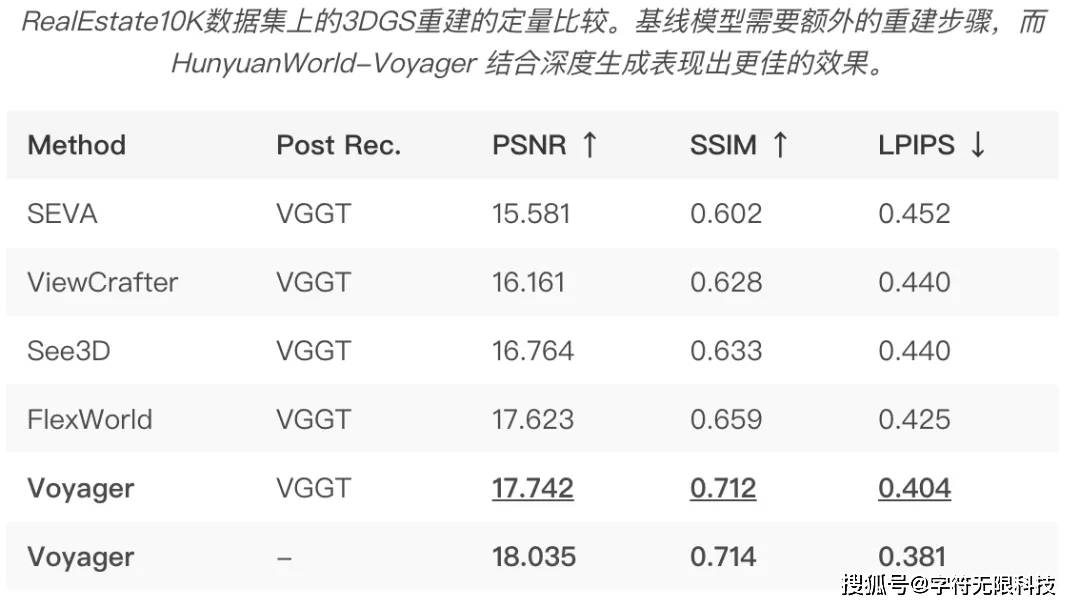
In terms of scene reconstruction,under the condition of post-processing with VGGT, the reconstruction results of Hunyuan Voyager outperform all baseline models, indicating that its generated videos demonstrate superior geometric consistency.
Additionally, if the generated depth information is further used to initialize the point cloud, the reconstruction effect improves, further proving the effectiveness of the proposed depth generation module for scene reconstruction tasks.
The qualitative results in the images above also corroborate this conclusion. In the last set of examples, Hunyuan Voyager can effectively retain the detailed features of the chandelier, while other methods struggle to reconstruct the basic shapes.
Moreover, in subjective quality evaluations, Hunyuan Voyager received the highest ratings, further validating that the generated videos possess exceptional visual authenticity.
Furthermore, Hunyuan Voyager is fully open source, with related technical reports publicly available, and the source code is freely accessible on GitHub and Hugging Face.
The requirements for model deployment are as follows:

One More Thing
Tencent Hunyuan is continually accelerating its open-source progress. In addition to the Hunyuan Voyager, the Hunyuan world model series also includes representative models like Hunyuan Large with MoE architecture, the hybrid reasoning model Hunyuan-A13B, and several small-size models aimed at edge scenarios, with the smallest having only 0.5B parameters.
Recently, they also open-sourced the translation model Hunyuan-MT-7Band the translation integrated model Hunyuan-MT-Chimera-7B, the latter having secured 30 first-place awards in international machine translation competitions.

Other domestic giants besides Tencent are also rapidly open-sourcing.
Alibaba’s Qwen goes without saying, and recently, Alibaba also open-sourced the video generation model Wan2.2-S2V.
Meituan’s first open-source large model Longcat-Flash-Chatwas also recently released; I wonder if everyone has been paying attention.返回搜狐,查看更多