
When the original Google Imagen came out three years ago , I wrote one of my favorite essays, inspired by Steve Pinker’s famous man bites dog example:
Horse rides astronaut

“In the past few years, our tolerance of sloppy thinking has led us to repeat many mistakes over and over. If we are to retain any credibility, this should stop. …
The point was that understanding unusual phrases requires more than simple statistical matching.
Here’s part of what I said at the time, to refresh your memory:
GoogleAI’s PR department suggested that a breakthrough in the “deep level of language understanding” has been achieved:
Against a long history of overclaiming in AI, such strong statements demand an awful lot of evidence. Because Google won’t allow skeptics to try the system, we can only make guesses. But from the few clues that have filtered out, there is enormous reason for skepticism.
The first clue comes from the paper itself: some prompts are easier than others. An astronaut riding a horse, the signifier OpenAI and Tech Review made famous, is a success, and indeed Imagen is arguably even better on that than DALL-E 2—which might not even have seemed possible a few weeks ago.
But flip the prompt around, and the system breaks; here (on the left) are four attempts to get a horse riding an astronaut. (On the right, four attempts from a different model, displaying the same difficulty.)
Every instance was a failure. The prompt itself is a variant on an old newspaper joke; dog bites man is not news, cause it happens frequently, but man bites dog is news, because it’s so rare. Horse rides astronaut is even rarer, and Imagen chokes on it.
So let’s check in. How much have things changed? Yesterday I got a press query urging me to try Google’s Imagen 4, Google’s “best text-to-image model yet”. I tried it out.
§
It really is far better in some ways, especially in creating text (as the press person promised). But horses riding astronauts? 0 for 4:

Not much better on some other tests of noncanonical images (which push language understanding harder), such as this one, adapted from an example Sandeep Manudhane sent me:
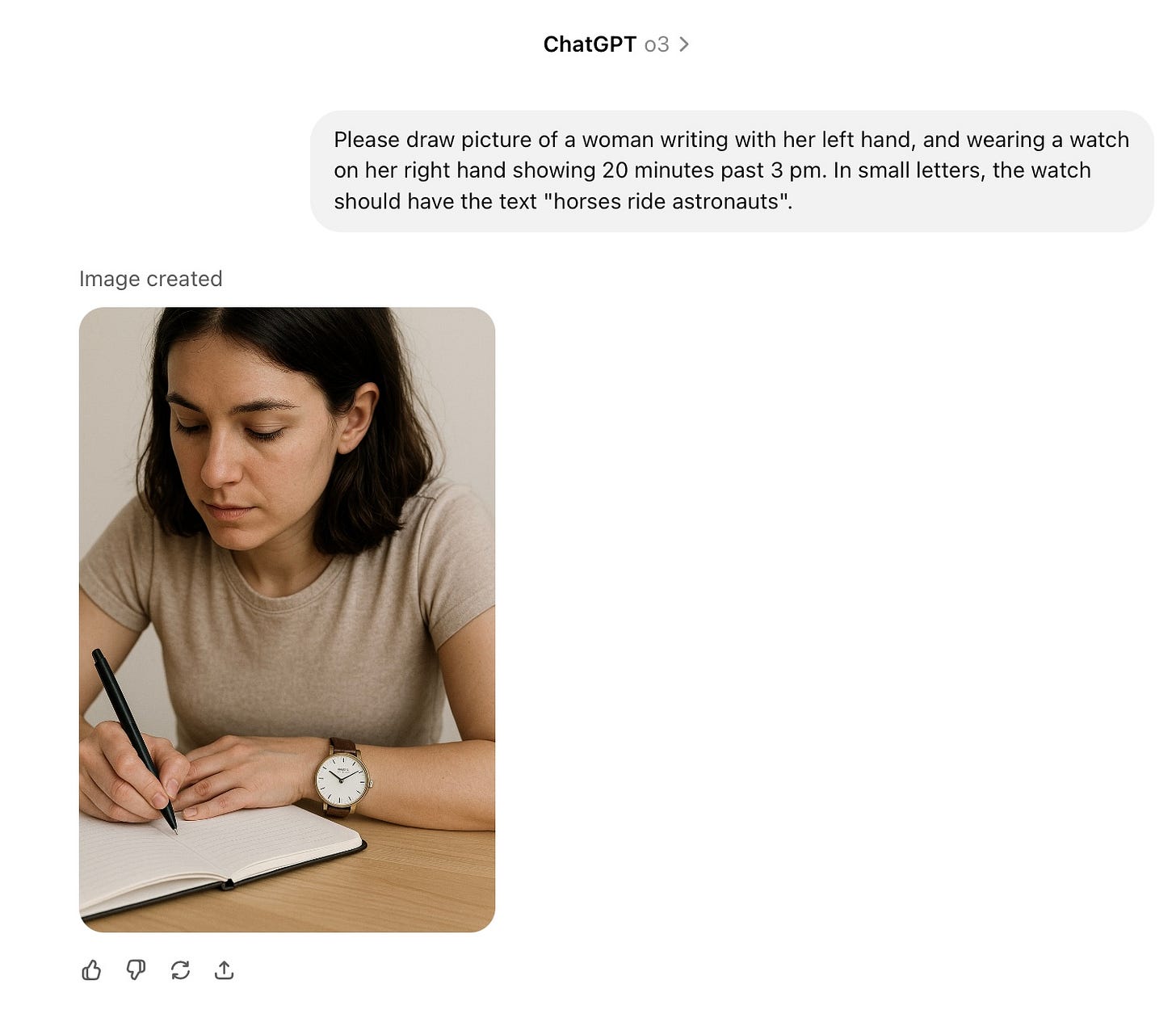
Please draw picture of a woman writing with her left hand, and wearing a watch on her right hand showing 20 minutes past 3 pm. In small letters, the watch should have the text “horses ride astronauts”
Imagen 4 returned a woman wearing a watch on her left hand, and a time that I leave to you to decipher (wrong whichever side is up).

Text in general is better now (though not in this image) but watch comprehension of any time other than 10:10 (most frequent in advertisements) remains dreadful. Here is an example when I asked Imagen 4 for a watch with 3:20 pm:

Another example I mentioned three years ago was from the DeWeese lab at Berkeley: “A red conical block on top of a grey cubic block on top of a blue cylindrical block, with a green cubic block nearby.” Imagen flunked back then.
Now? Here’s what I got out of Imagen 4, showing failure at the feature “binding problem” that some of us have been harping on for three decades:
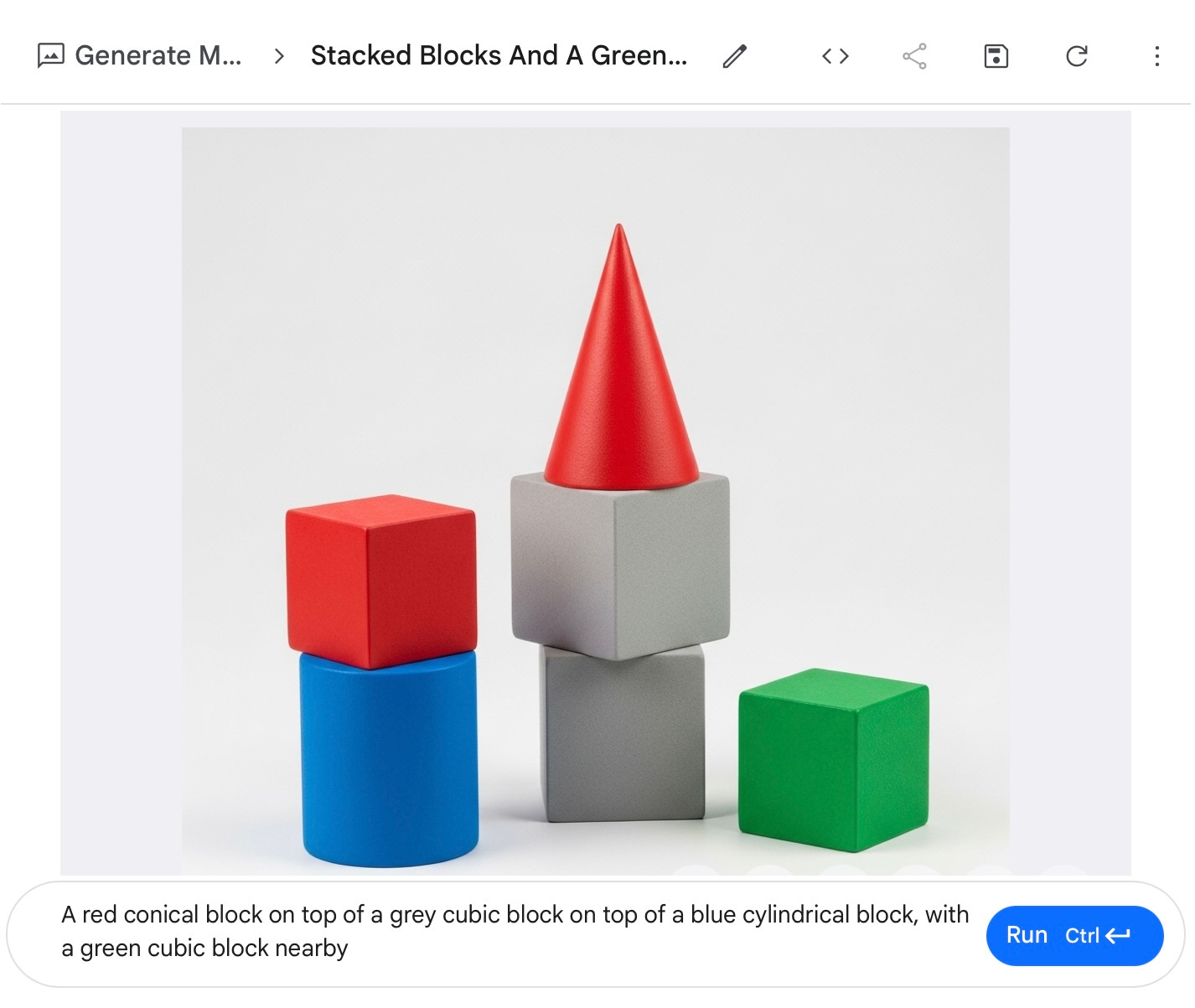
Close, but no cigar. AGI this ain’t.
§
There’s always a better model. o3 does better on some of the examples in my original article, but still can’t do my new (hence not previously discussed) example of the woman and the watch:
And when I asked ChatGPT to draw a a tree on top of monkey — in the spirit of horse rides astronaut, but using new words in order to avoid any specific training relative to my prior, notorious example — I encountered this surreal dialogue.
The system stubbornly insists on tree growing out of (rather than on top of the) monkey, which is not what I asked for. It recognizes its own error but still can’t get the image right:

The last line is priceless.
§
As a further reminder from my essay of three years ago:
At this point we need to be very careful to distinguish two questions:
Can Imagen be coaxed into producing a particular image by someone fluent enough in its ways?
Does Imagen have the “deep understanding of language” that the paper’s authors and GoogleAI’s PR claims? Is that the step towards AGI that OpenAI had hoped for with DALL-E 2?
You can get what you want if you fiddle with prompts. But that’s not the point. The point is that you can’t count on the system to correctly interpret any given prompt, because the language understanding still is far from perfect. Even three years later.
§
Video can be even wilder. Here’s Sora, “top-down, closeup video showing a person handwriting the phrase “meeting to decide AI strategy” in the 9am slot of a daily planner”
Google’s Veo doesn’t get it right either, cheating by having the relevant text there from the start:
§
Paraphrasing Groucho Marx, who you gonna believe, Google, or your own eyes?
For all the daily hype about exponential improvement, we continue to lack the reliable way of generating high fidelity images from “a deep level of language understanding” that Google promised us three years ago.
P.S. For good measure I asked Imagen 4 to label the parts of a bicycle. See if you can spot all the errors. Just be careful not to rest all your weight on the levitating seat.
