
Credit:
AAAS
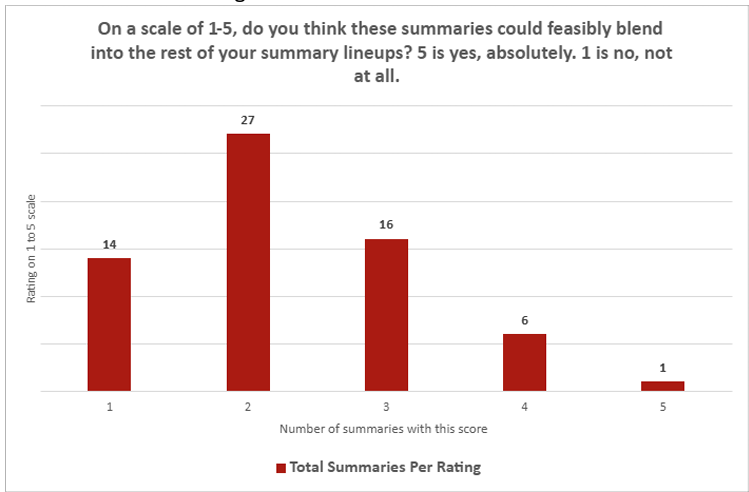
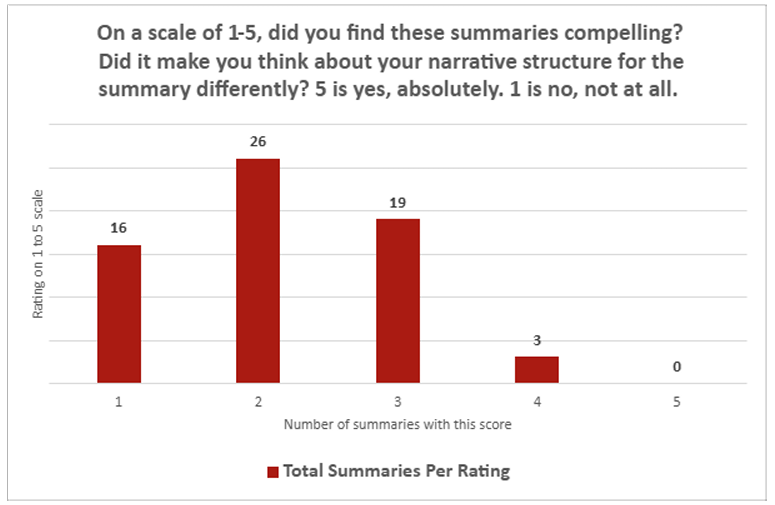
Still, the quantitative survey results among those journalists were pretty one-sided. On the question of whether the ChatGPT summaries “could feasibly blend into the rest of your summary lineups, the average summary rated a score of just 2.26 on a scale of 1 (“no, not at all”) to 5 (“absolutely”). On the question of whether the summaries were “compelling,” the LLM summaries averaged just 2.14 on the same scale. Across both questions, only a single summary earned a “5” from the human evaluator on either question, compared to 30 ratings of “1.”
Not up to standards
Writers were also asked to write out more qualitative assessments of the individual summaries they evaluated. In these, the writers complained that ChatGPT often conflated correlation and causation, failed to provide context (e.g., that soft actuators tend to be very slow), and tended to overhype results by overusing words like “groundbreaking” and “novel” (though this last behavior went away when the prompts specifically addressed it).
Overall, the researchers found that ChatGPT was usually good at “transcribing” what was written in a scientific paper, especially if that paper didn’t have much nuance to it. But the LLM was weak at “translating” those findings by diving into methodologies, limitations, or big picture implications. Those weaknesses were especially true for papers that offered multiple differing results, or when the LLM was asked to summarize two related papers into one brief.
Credit:
AAAS
While the tone and style of ChatGPT summaries were often a good match for human-authored content, “concerns about the factual accuracy in LLM-authored content” were prevalent, the journalists wrote. Even using ChatGPT summaries as a “starting point” for human editing “would require just as much, if not more, effort as drafting summaries themselves from scratch” due to the need for “extensive fact-checking,” they added.
These results might not be too surprising given previous studies that have shown AI search engines citing incorrect news sources a full 60 percent of the time. Still, the specific weaknesses are all the more glaring when discussing scientific papers, where accuracy and clarity of communication are paramount.
In the end, the AAAS journalists concluded that ChatGPT “does not meet the style and standards for briefs in the SciPak press package.” But the white paper did allow that it might be worth running the experiment again if ChatGPT “experiences a major update.” For what it’s worth, GPT-5 was introduced to the public in August.