
Today, we are excited to announce a new capability of Amazon SageMaker HyperPod task governance to help you optimize training efficiency and network latency of your AI workloads. SageMaker HyperPod task governance streamlines resource allocation and facilitates efficient compute resource utilization across teams and projects on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Administrators can govern accelerated compute allocation and enforce task priority policies, improving resource utilization. This helps organizations focus on accelerating generative AI innovation and reducing time to market, rather than coordinating resource allocation and replanning tasks. Refer to Best practices for Amazon SageMaker HyperPod task governance for more information.
Generative AI workloads typically demand extensive network communication across Amazon Elastic Compute Cloud (Amazon EC2) instances, where network bandwidth impacts both workload runtime and processing latency. The network latency of these communications depends on the physical placement of instances within a data center’s hierarchical infrastructure. Data centers can be organized into nested organizational units such as network nodes and node sets, with multiple instances per network node and multiple network nodes per node set. For example, instances within the same organizational unit experience faster processing time compared to those across different units. This means fewer network hops between instances results in lower communication.
To optimize the placement of your generative AI workloads in your SageMaker HyperPod clusters by considering the physical and logical arrangement of resources, you can use EC2 network topology information during your job submissions. An EC2 instance’s topology is described by a set of nodes, with one node in each layer of the network. Refer to How Amazon EC2 instance topology works for details on how EC2 topology is arranged. Network topology labels offer the following key benefits:
Reduced latency by minimizing network hops and routing traffic to nearby instances
Improved training efficiency by optimizing workload placement across network resources
With topology-aware scheduling for SageMaker HyperPod task governance, you can use topology network labels to schedule your jobs with optimized network communication, thereby improving task efficiency and resource utilization for your AI workloads.
In this post, we introduce topology-aware scheduling with SageMaker HyperPod task governance by submitting jobs that represent hierarchical network information. We provide details about how to use SageMaker HyperPod task governance to optimize your job efficiency.
Solution overview
Data scientists interact with SageMaker HyperPod clusters. Data scientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. It’s important to make sure data scientists have the necessary capacity and permissions when interacting with clusters of GPUs.
To implement topology-aware scheduling, you first confirm the topology information for all nodes in your cluster, then run a script that tells you which instances are on the same network nodes, and finally schedule a topology-aware training task on your cluster. This workflow facilitates higher visibility and control over the placement of your training instances.
In this post, we walk through viewing node topology information and submitting topology-aware tasks to your cluster. For reference, NetworkNodes describes the network node set of an instance. In each network node set, three layers comprise the hierarchical view of the topology for each instance. Instances that are closest to each other will share the same layer 3 network node. If there are no common network nodes in the bottom layer (layer 3), then see if there is commonality at layer 2.
Prerequisites
To get started with topology-aware scheduling, you must have the following prerequisites:
An EKS cluster
A SageMaker HyperPod cluster with instances enabled for topology information
The SageMaker HyperPod task governance add-on installed (version 1.2.2 or later)
Kubectl installed
(Optional) The SageMaker HyperPod CLI installed
Get node topology information
Run the following command to show node labels in your cluster. This command provides network topology information for each instance.
Instances with the same network node layer 3 are as close as possible, following EC2 topology hierarchy. You should see a list of node labels that look like the following:topology.k8s.aws/network-node-layer-3: nn-33333exampleRun the following script to show the nodes in your cluster that are on the same layers 1, 2, and 3 network nodes:
The output of this script will print a flow chart that you can use in a flow diagram editor such as Mermaid.js.org to visualize the node topology of your cluster. The following figure is an example of the cluster topology for a seven-instance cluster.
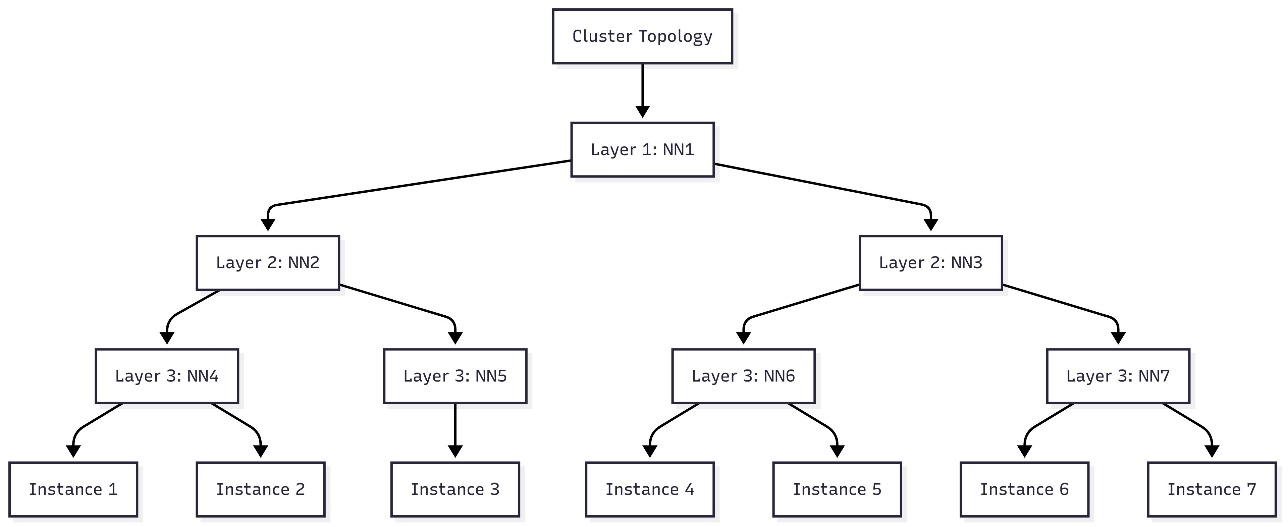
Submit tasks
SageMaker HyperPod task governance offers two ways to submit tasks using topology awareness. In this section, we discuss these two options and a third alternative option to task governance.
Modify your Kubernetes manifest file
First, you can modify your existing Kubernetes manifest file to include one of two annotation options:
kueue.x-k8s.io/podset-required-topology – Use this option if you must have all pods scheduled on nodes on the same network node layer in order to begin the job
kueue.x-k8s.io/podset-preferred-topology – Use this option if you ideally want all pods scheduled on nodes in the same network node layer, but you have flexibility
The following code is an example of a sample job that uses the kueue.x-k8s.io/podset-required-topology setting to schedule pods that share the same layer 3 network node:
To verify which nodes your pods are running on, use the following command to view node IDs per pod:kubectl get pods -n hyperpod-ns-team-a -o wide
Use the SageMaker HyperPod CLI
The second way to submit a job is through the SageMaker HyperPod CLI. Be sure to install the latest version (version pending) to use topology-aware scheduling. To use topology-aware scheduling with the SageMaker HyperPod CLI, you can include either the –preferred-topology parameter or the –required-topology parameter in your create job command.
The following code is an example command to start a topology-aware mnist training job using the SageMaker HyperPod CLI, replace XXXXXXXXXXXX with your AWS account ID:
Clean up
If you deployed new resources while following this post, refer to the Clean Up section in the SageMaker HyperPod EKS workshop to make sure you don’t accrue unwanted charges.
Conclusion
During large language model (LLM) training, pod-to-pod communication distributes the model across multiple instances, requiring frequent data exchange between these instances. In this post, we discussed how SageMaker HyperPod task governance helps schedule workloads to enable job efficiency by optimizing throughput and latency. We also walked through how to schedule jobs using SageMaker HyperPod topology network information to optimize network communication latency for your AI tasks.
We encourage you to try out this solution and share your feedback in the comments section.
About the authors
 Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
Zican Li is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for Task Governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
 Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.