
GenerativeAI had a truly bad week. The late and underwhelming arrival of GPT-5 wasn’t even the worst part. But before we get to the worst part (spoiler alert: a new research paper that I will discuss towards the end), let’s review GPT-5’s shambolic debut.
This was supposed to be the week when OpenAI finally cemented its dominance. The long rumored GPT-5 was about to arrive. Sam Altman was so cocky that in advance of the livestream debut he posted a screen grab from a Star War film, Rogue One:
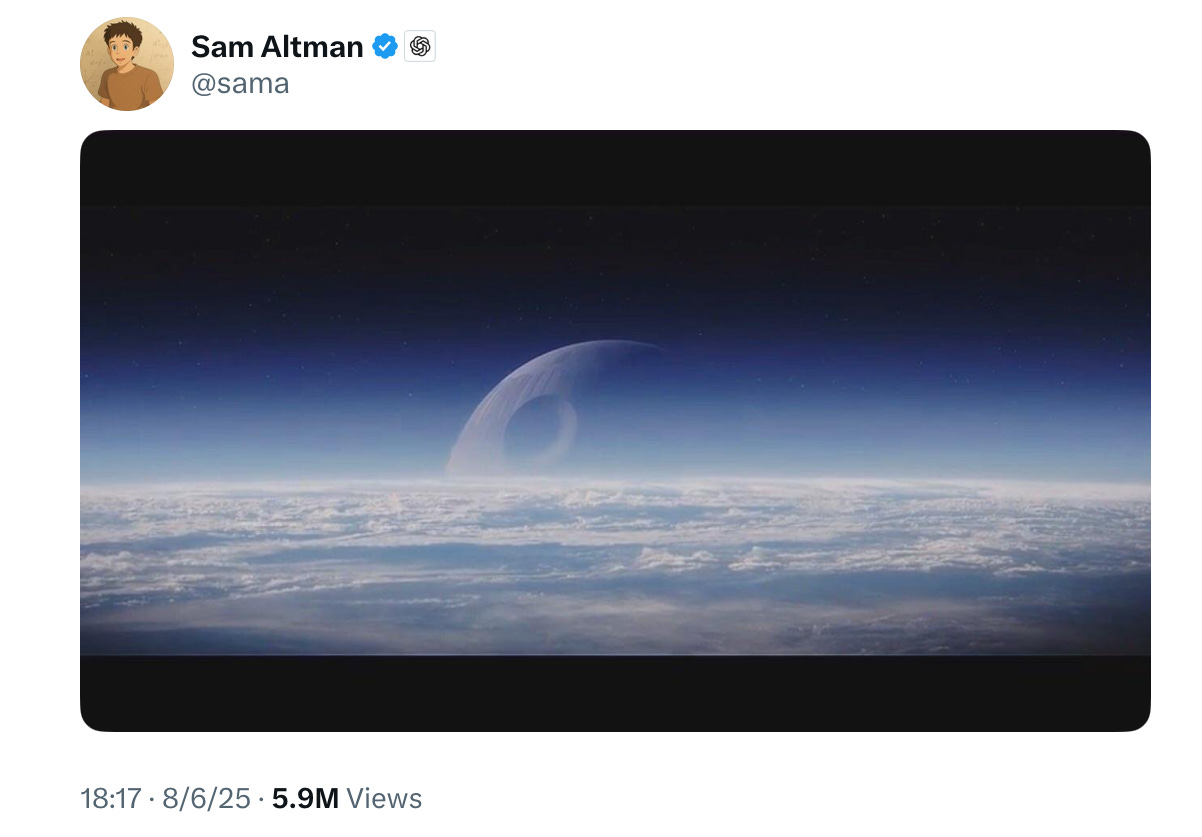
People ate it up. It got almost six million views.
The cockiness continued at the opening of the livestream. Altman, ever the showman, claimed
We think you will love using GPT-5 much more than any previous Al. It is useful it is smart it is fast [and[ intuitive. GPT-3 was sort of like talking to a high school student.
There were flashes of brilliance lots of annoyance but people started to use it and get some value out of it. GPT-4o maybe it was like talking to a college student…. With GPT-5 now it’s like talking to an expert —- a legitimate PhD level expert in anything any area you need on demand they can help you with whatever your goals are.
What the mainstream media mostly hasn’t told you yet is that a few days later, hardly anybody is buying Altman’s story.
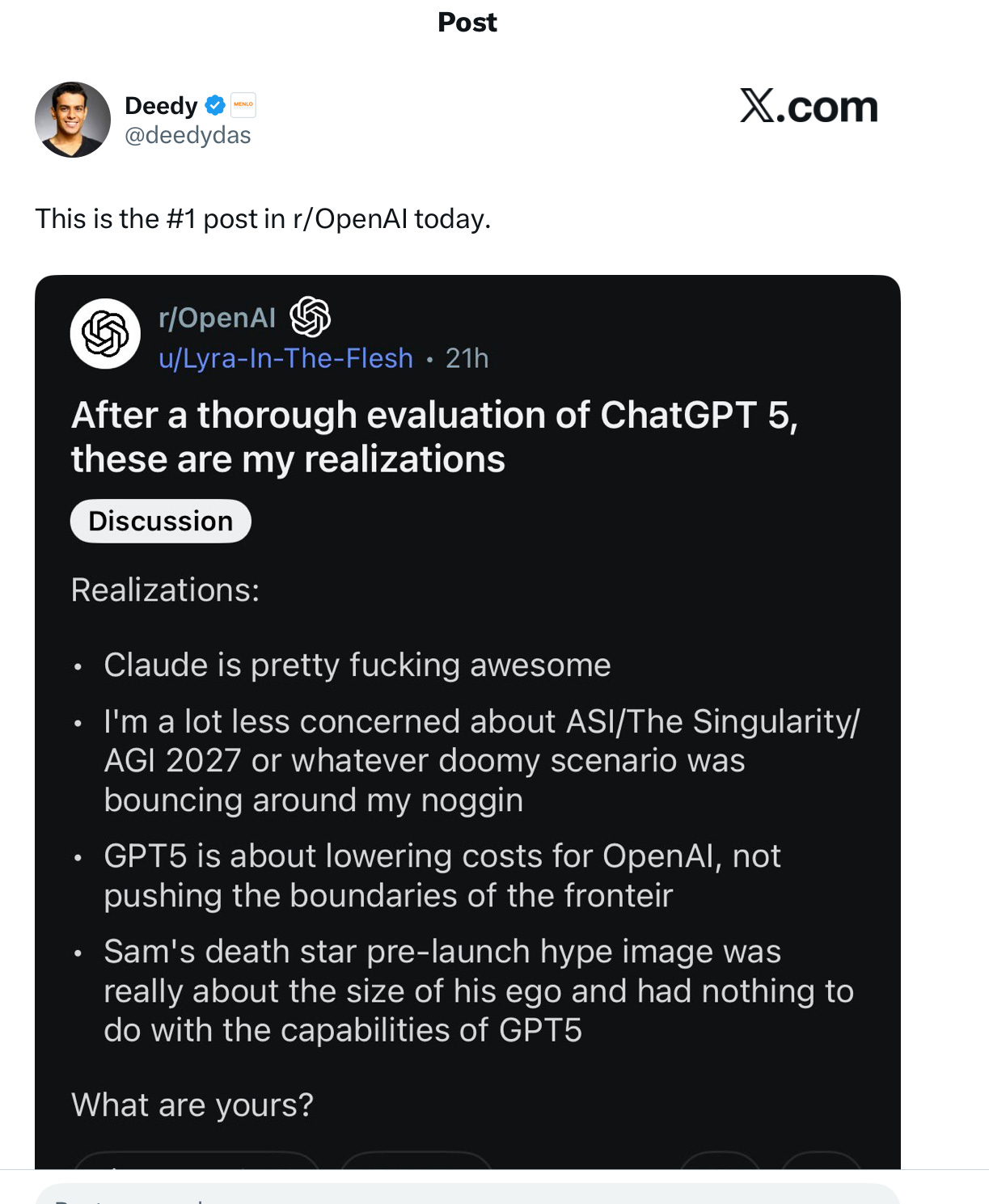
3,000 people hated GPT-5 so much they petitioned — successfully — to get one of the older models back. At OpenAI reddit, usually quite pro OpenAI, the lead post was this:
As they say on Twitter, Altman’s Death Star tweet didn’t age well.
Meanwhile, as for that Star Wars movie, more than a few people end up wondering if Altman has ever watched the film. For those unfamilar, what happens next is… the Rebel Alliance blows up the Death Star.
§
OpenAI basically blew itself up – and not in a good way. Aside from a few influencers who praise every new model, the dominant reaction was major disappointment.
A system that could have gone a week without the community finding boatloads of ridiculous errors and hallucinations would have genuinely impressed me.
Instead, within hours, people were posting the usual ridiculous errors. A Hacker News thread brutally dissected the live, vibe-coded demo of the Bernoulli effect. Multiple posts identified benchmarks where performance was subpar. (Not just the ARC-AGI-2 I had noted in my hot take a few days ago, either). Still others found the new automatic “routing” mechanism to be a mess. It was essentially the same experience as with every earlier model. Big promises, stupid errors.
But this time, the reaction was different. Because expectations were through the roof, a huge number of people viewed GPT 5 as a major letdown. By the end of the night, OpenAI’s street cred had dramatically fallen. On the question of “which company [will have] the best AI model at the end of August”, a Polymarket poll charted OpenAI dropping from 75% to 14% in the space of an hour.
Typical was a comment from Andres Franco, on X “GPT 5 has been a huge letdown, way more than I expected”. Another reader, previously an OpenAI fan, told me “o3 was a shit good model, [whereas GPT-5] was an utter disappointment, especially given the kind of hype towards its release.” An NBA President DM’d me to say “chatgpt 5 still failed my two fav problems to give LLMs”.
Loads of people seemed to sincerely expect GPT-5 was going to be AGI. It doesn’t take decades of training to see that GPT-4 was not that.
Even my anti-fan club (“Gary haters” in modern parlance) were forced to give me props. Tweets like “The saddest thing in my day is that @garymarcus is right” became trendy.
With a more positive framing, freelance journalist Bryan McMahon wrote to me, “We all saw GPT-5’s reveal fall flat yesterday—so flat, in fact, that many online dubbed it “Gary Marcus Day” for proving your consistent criticism about the structural flaws of large language models correct.”
§
And, indeed, much as I anticipated here two weeks ago, the problems I have been pointing out over the last quarter century still lingered. Consider for example the critique I gave re: chess and world models at the end of June. My go-to source on this, Mathieu Acher, quickly confirmed that GPT-5 still struggles with following the rules. A Tufts professor sent me a further example, in which GPT-5 becomes completely lost in the course of discussing a simple chess problem.
Or take visual comprehension:

The challenge of parts and wholes in generative images that Ernest Davis and I discussed here in December fared no better. (Some argued that this is because GPT-5 is still using an older models for generating images, but given that the new thing was supposed to be tantamount to AGI and “fully multimodal” that hardly seems like a compelling excuse.)
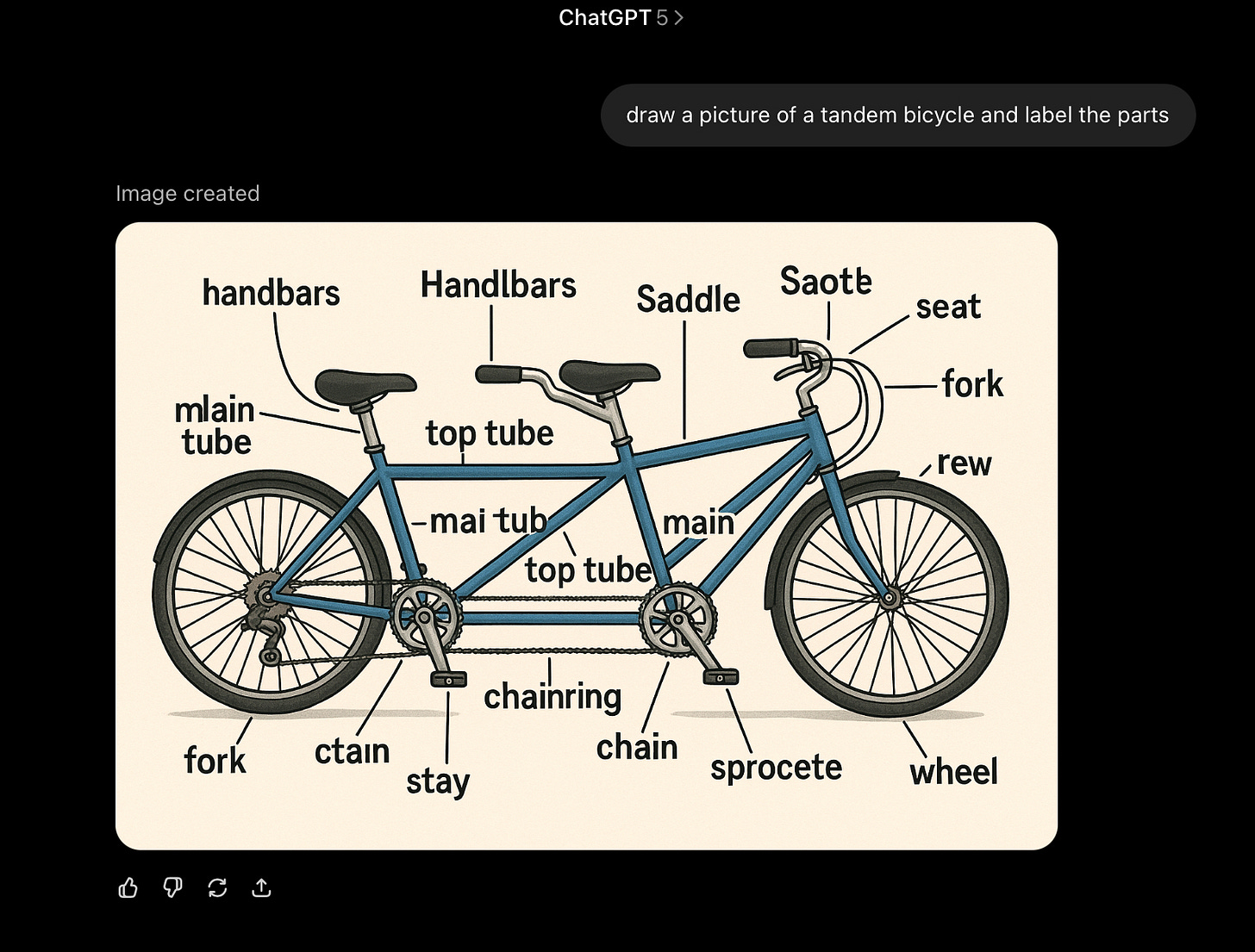
I am pretty sure most, if not all, PhDs in mechanical engineering could do better. So could anybody working in a bike shop, and for that matter maybe your kid brother or sister, too.
Émile Torres has a good round-up of many more immediately-uncovered blunders. Cameron Williams found examples in basic reading and summarization.
§
For all that, GPT-5 is not a terrible model. I played with it for about an hour, and it actually got several of my initial queries right (some initial problems with counting “r’s in blueberries had already been corrected, for example). It only fell apart altogether when I experimented with images.
But the reality is that GPT-5 just not that different from anything that came before. And that’s the point. GPT-4 was widely seen as a radical advance over GPT-3; GPT-3 was widely seen as a radical advance over GPT-2. GPT-5 is barely better than last month’s flavor of the month (Grok 4); on some metrics (ARC-AGI-2) it’s actually worse.
People had grown to expect miracles, but GPT-5 is just the latest incremental advance. And it felt rushed at that, as one meme showed.
The one prediction I got most deeply wrong was in thinking that with so much at stake OpenAI would save the name GPT-5 for something truly remarkable. I honestly didn’t think OpenAI would burn the brand name on something so mid.
I was wrong.
§
For a year or two I have been speculating that OpenAI might take a serious hit if GPT-5 was disappointing. We may finally soon find out.
Certainly, in a rational world, their valuation would take a hit.
They no longer have anything like a clear technical lead.
GPT-5 is unlikely to be ahead of the pack for more than a couple months. (And Grok 4 Heavy is already better on the ARC-AGI-2 measure)
Many of their best people have left.
Many of those people left to start competitors.
Elon is moving faster. Anthropic and Google and many others are nipping at their heels. Their relationship with Microsoft has frayed.
OpenAI still isn’t making profit.
Instead they are being forced to cut prices.
People are wising up that LLMs are not in fact AGI-adjacent.
People are becoming more skeptical about the company and its CEO.
OpenAI has the name brand recognition, and good UX. Will that be enough to sustain a $300-500B valuation? Hard to know.
§
By rights, Altman’s reputation should by now be completely burned. This is a man who joked in September 2023 that “AGI has been achieved internally”, told us in January of this year in his blog that “We are now confident we know how to build AGI as we have traditionally understood it”. Just two days ago he hold us that as quoted above) interacting with GPT-5 we “like talking to … legitimate PhD level expert in anything”.
In hindsight, that was all bullshit.
And the worst part? Altman brought it all on himself. Had he not kept hinting at the moon, people might have been fine with just another incremental update.
§
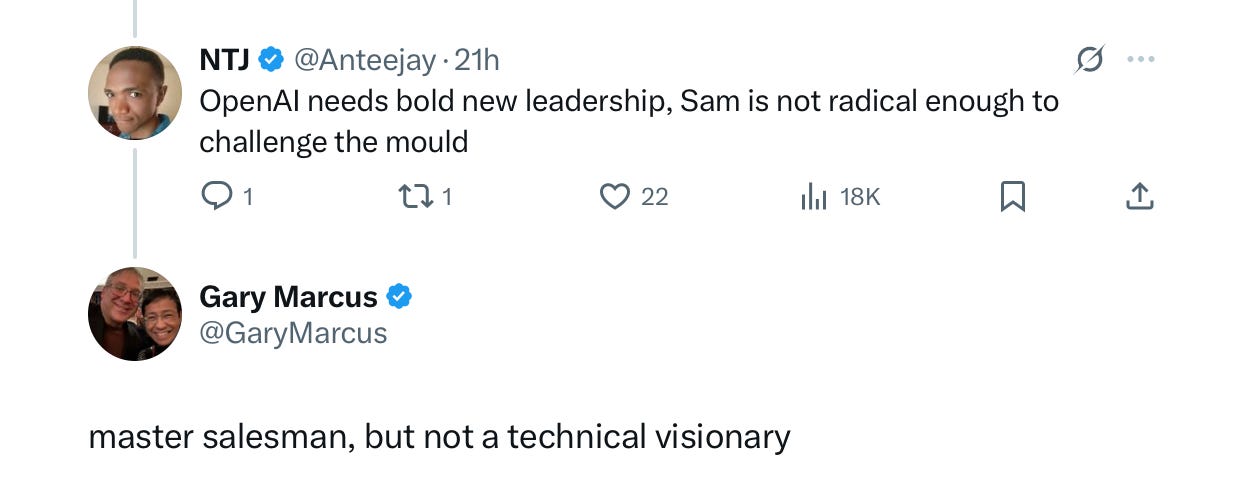
He may not even be the right CEO for OpenAI anymore:
§
So ok, all this is obviously no bueno for OpenAI. But what of the field of generative AI as a whole? It’s not like other systems are faring much better. The psychologist Jonathan Shedler was absolutely brutal in a takedown of Grok, writing in part about Grok’s summary of one of his own papers:
I’m the author of the paper @grok describes here. It’s among the most read and cited articles on psychotherapy outcome-required reading in grad programs around the world
Grok gets literally everything wrong
The paper shows psychodynamic therapy is as or more effective than
CBT. Grok says the exact opposite
The title of the paper is literally, “The efficacy of psychodynamic psychotherapy.”
The effect size for psychodynamic therapy for the major study in the paper was .97. Grok says it’s 33. The number .33 does not appear anywhere in the paper.
Al seems to know everything—until it’s a topic where you have firsthand knowledge
How is AI going to invent new science when it can’t even accurately report existing science?
§
But I have kept you in suspense long enough. At the beginning, and in the subtitle, I hinted that there was even worse news.
The real news is a breaking study from Arizona State University that fully vindicates what I have told you for nearly 30 years—and more recently what Apple told you—about the core weakness of LLMs: their inability to generalize broadly.
The physicist Steve Hsu wrote a great summary on X; in every way it vindicates both the unfairly-maligned but significant Apple reasoning paper and the core ideas that I have been pushing about distribution shift for the last three decades:

Reading the abstract (Chain of Thought reasoning is “a brittle mirage that vanishes when it is pushed beyond training distributions”) practically gave me deja vu. In 1998 I wrote that “universals are pervasive in language and reasoning” but showed experimentally that neural networks of that era could not reliably “extend universals outside [a] training space of examples”.
The ASU team showed that exactly the same thing was true even in the latest, greatest models. Throw in every gadget invented since 1998, and the Achilles’ Heel I identified then still remains. That’s startling. Even I didn’t expect that.
And, crucially, the failure to generalize adequately outside distribution tells us why all the dozens of shots on goal at building “GPT-5 level models” keep missing their target. It’s not an accident. That failing is principled.
§
We have been fed a steady diet of bullshit for the last several years.
• General purpose agents that turn out to suck so badly people struggle to find real-world use cases for them. (Any one remember Facebook M, a decade ago?)
• Allegedly godlike models that turn out to be incremental advances.
• Claims like “We now know how to build AGI” that never turn out to be true.
• Promises for world-changing science that rarely materialize.
• Driverless cars that still are only available in couple percent of the world’s cities.
• Promises to Congress (AI to filter our fake news! Regulation for AI) that quickly turn to be bogus.
• Fantasies about timelines, what Ilya saw, and endless influencer hype.
• Cherry-picked studies, benchmark-gaming, and now even vibe-coded graphs, with zero transparency about how systems work or how they have been trained; public science is in the rear view mirror.
I love AI. (Or at least what I optimistically imagine it could be.)
But I hate this bullshit.
What’s changed is that a lot of other people are tiring of it, too. In Zeynep Tufekci‘s words, the term AGI has become “a tool of obfuscation directed [at] investors and the public.”
§
In many ways, my work here, in the context of publicly explaining the limits of the pure scaling approach—which is literally how this very Substack began in May 2022, nearly three and half years ago—is done. Nobody with intellectual integrity should still believe that pure scaling will get us to AGI. You could say the same about my by now 27-year-old mission to get the field to recognize the centrality of the distribution shift problem. Even some of the tech bros are waking up to the reality that “AGI in 2027” was marketing, not reality.
GPT-5 may be a moderate quantitative improvement (and it may be cheaper) but it still fails in all the same qualitative ways as its predecessors, on chess, on reasoning, in vision; even sometimes on counting] and basic math.. Hallucinations linger. Dozens of shots on goal (Grok, Claude, Gemini) etc have invariably faced the same problems. Distribution shift has never been solved.
That’s exactly what it means to hit a wall, and exactly the particular set of obstacles I described in my most notorious (and prescient) paper, in 2022. Real progress on some dimensions, but stuck in place on others.
Ultimately, the idea that scaling alone might get us to AGI is a hypothesis.
No hypothesis has ever been given more benefit of the doubt, nor more funding. After half a trillion dollars in that direction, it is obviously time to move on. The disappointing performance of GPT-5 should make that enormously clear.
Pure scaling simply isn’t the path to AGI. It turns out that attention, the key component in LLMs, and the focus of the justly famous Transformer paper, is not fact “all you need”.
All I am saying is give neurosymbolic AI with explicit world models a chance. Only once we have systems that can reason about enduring representations of the world, including but not to limited to abstract symbolic ones, will we have a genuine shot at AGI.

PS For expository purposes, I told a little white lie above, and pretended that there was only one truly devastating new scientific finding about LLMs this week. But the aforementioned “mirage” is not the only problem. There’s actually another—an entirely different can of worms—that I will be talking about in the not too distant future. Stay tuned. And stay to the end for a final postscript.
PPS Bonus content, sound up, for my personal favorite meme of the week, sent to me (and created by) a retired VFX editor who has taken an interest in AI: