
In July 2025, Mistral AI unveiled Voxtral, a powerful new entry in the world of AI audio models. Unlike most competitors, Voxtral is fully open source and designed for deeper audio understanding, interaction, and automation. Positioned as a direct alternative to OpenAI’s Whisper and other proprietary tools, Voxtral blends performance with developer freedom.
Here’s a breakdown of what Voxtral is, what makes it different, and why it matters.
Also read: Le Chat: A faster European alternative to American AI
What Is Voxtral?
Voxtral is an open-source family of AI models built to handle speech recognition, transcription, audio comprehension, and even voice-triggered automation. It’s part of Mistral AI’s broader push to make top-tier generative AI tools more accessible, transparent, and cost-effective. Released under the Apache 2.0 license, Voxtral can be used freely in both commercial and private deployments.
There are two versions of the model:
Voxtral Small (24 billion parameters): Designed for production-grade applications, such as enterprise voice assistants or transcription services.
Voxtral Mini (3 billion parameters): Optimized for running on local devices such as mobile phones or offline systems.
Key features of Voxtral
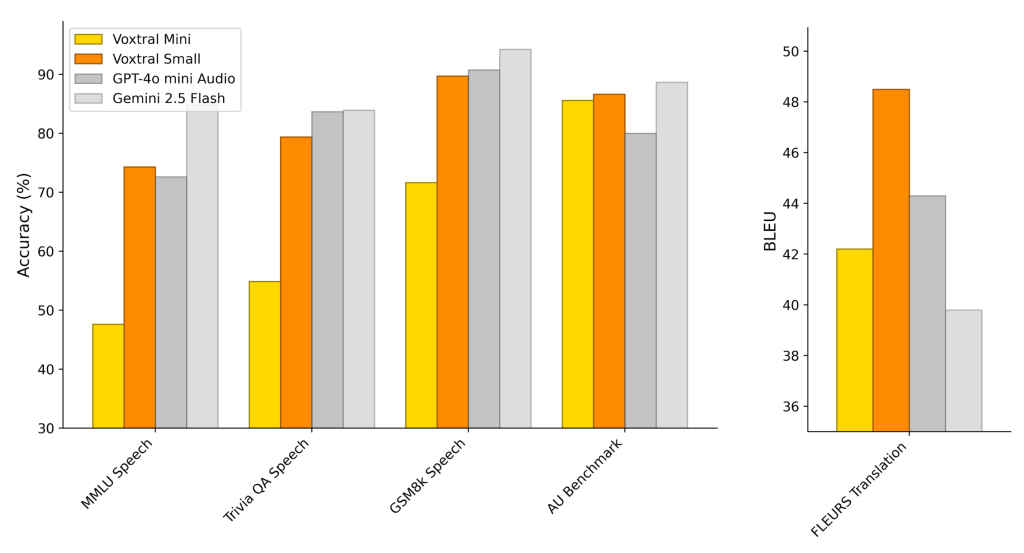
Voxtral isn’t just another automatic speech recognition (ASR) tool, it goes beyond transcription. It’s capable of understanding audio content, summarizing what was said, answering questions about the conversation, and extracting key data points, all directly from voice input.
Also read: Grok 4 is full of controversies: A list of xAI’s misconduct
For example, if you ask, “What was the refund request mentioned in the call?”, Voxtral can give you an exact answer with timestamps, without needing a separate language model.
Unlike traditional models that struggle with longer clips, Voxtral can process up to 30–40 minutes of audio per pass, thanks to its 32,000-token context window. This makes it ideal for meetings, interviews, lectures, and podcasts.Voxtral can automatically detect and transcribe speech in multiple languages, including English, Spanish, French, Hindi, German, Portuguese, Dutch, and Italian. There’s no need to manually set the language, it just works.
One of Voxtral’s standout features is its ability to interpret voice commands and trigger backend actions. For instance, if a user says, “Check the order and send a confirmation email,” Voxtral can process the request and pass it to your API, eliminating the need for custom grammar or intent layers. Users can interact with audio files like they would with a chatbot. You can ask questions about a recorded call, generate a summary, or extract decisions made in a meeting. all without manual tagging or transcripts. Voxtral is cheaper and faster than many closed models.
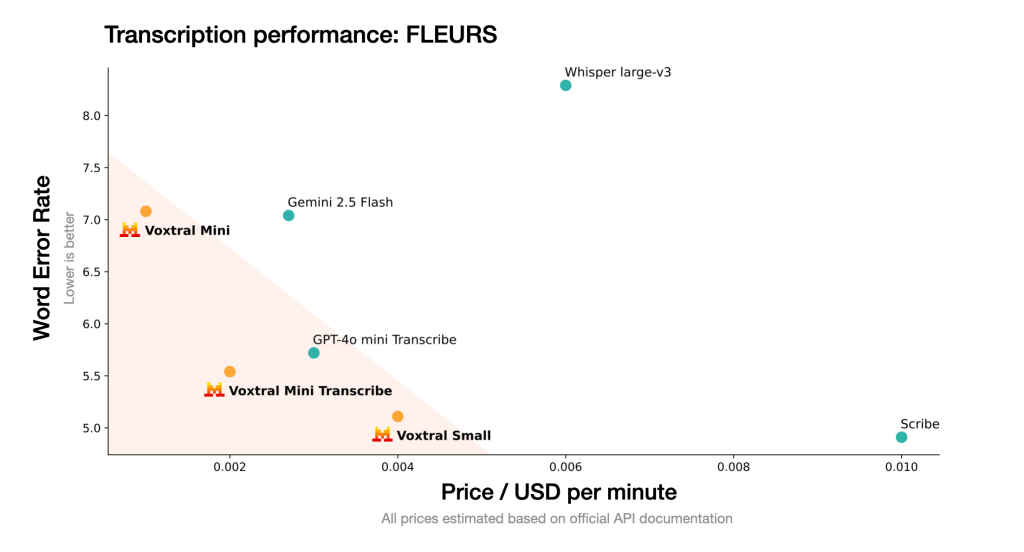
It outperforms OpenAI Whisper large-v3 in several transcription and comprehension benchmarks, while costing just $0.001–$0.004 per audio minute, depending on deployment. That’s nearly half the price of Whisper or other commercial tools. Beyond audio, Voxtral can handle textual tasks like code completion, summarization, and reasoning, making it a versatile tool for developers who need a unified model across modalities.
Why Voxtral matters
Voxtral’s arrival is a major moment for the AI developer community. It offers capabilities typically locked behind proprietary APIs but in a completely open format. Enterprises get privacy and control, startups get flexibility and cost savings, and developers get to build without constraints.
Whether you’re building a voice assistant, summarizing customer calls, or deploying multilingual transcription on mobile, Voxtral brings powerful AI audio tools into the open, without cutting corners on performance.
Also read: How to run offline AI LLM model on Android using MLC Chat
Vyom Ramani
A journalist with a soft spot for tech, games, and things that go beep. While waiting for a delayed metro or rebooting his brain, you’ll find him solving Rubik’s Cubes, bingeing F1, or hunting for the next great snack. View Full Profile