
Today, we are excited to announce that Mercury and Mercury Coder foundation models (FMs) from Inception Labs are available through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, you can deploy the Mercury FMs to build, experiment, and responsibly scale your generative AI applications on AWS.
In this post, we demonstrate how to get started with Mercury models on Amazon Bedrock Marketplace and SageMaker JumpStart.
About Mercury foundation models
Mercury is the first family of commercial-scale diffusion-based language models, offering groundbreaking advancements in generation speed while maintaining high-quality outputs. Unlike traditional autoregressive models that generate text one token at a time, Mercury models use diffusion to generate multiple tokens in parallel through a coarse-to-fine approach, resulting in dramatically faster inference speeds. Mercury Coder models deliver the following key features:
Ultra-fast generation speeds of up to 1,100 tokens per second on NVIDIA H100 GPUs, up to 10 times faster than comparable models
High-quality code generation across multiple programming languages, including Python, Java, JavaScript, C++, PHP, Bash, and TypeScript
Strong performance on fill-in-the-middle tasks, making them ideal for code completion and editing workflows
Transformer-based architecture, providing compatibility with existing optimization techniques and infrastructure
Context length support of up to 32,768 tokens out of the box and up to 128,000 tokens with context extension approaches
About Amazon Bedrock Marketplace
Amazon Bedrock Marketplace plays a pivotal role in democratizing access to advanced AI capabilities through several key advantages:
Comprehensive model selection – Amazon Bedrock Marketplace offers an exceptional range of models, from proprietary to publicly available options, so organizations can find the perfect fit for their specific use cases.
Unified and secure experience – By providing a single access point for models through the Amazon Bedrock APIs, Amazon Bedrock Marketplace significantly simplifies the integration process. Organizations can use these models securely, and for models that are compatible with the Amazon Bedrock Converse API, you can use the robust toolkit of Amazon Bedrock, including Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Flows.
Scalable infrastructure – Amazon Bedrock Marketplace offers configurable scalability through managed endpoints, so organizations can select their desired number of instances, choose appropriate instance types, define custom automatic scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Deploy Mercury and Mercury Coder models in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace gives you access to over 100 popular, emerging, and specialized foundation models through Amazon Bedrock. To access the Mercury models in Amazon Bedrock, complete the following steps:
On the Amazon Bedrock console, in the navigation pane under Foundation models, choose Model catalog.
You can also use the Converse API to invoke the model with Amazon Bedrock tooling.
On the Model catalog page, filter for Inception as a provider and choose the Mercury model.
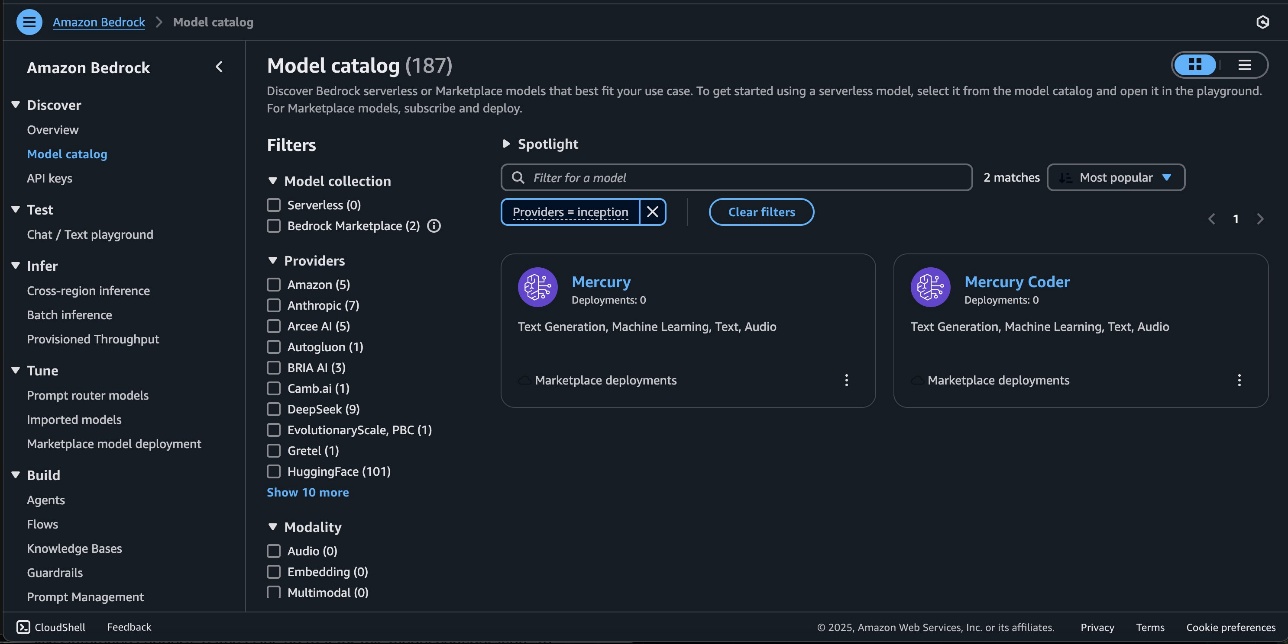
The Model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.
To begin using the Mercury model, choose Subscribe.
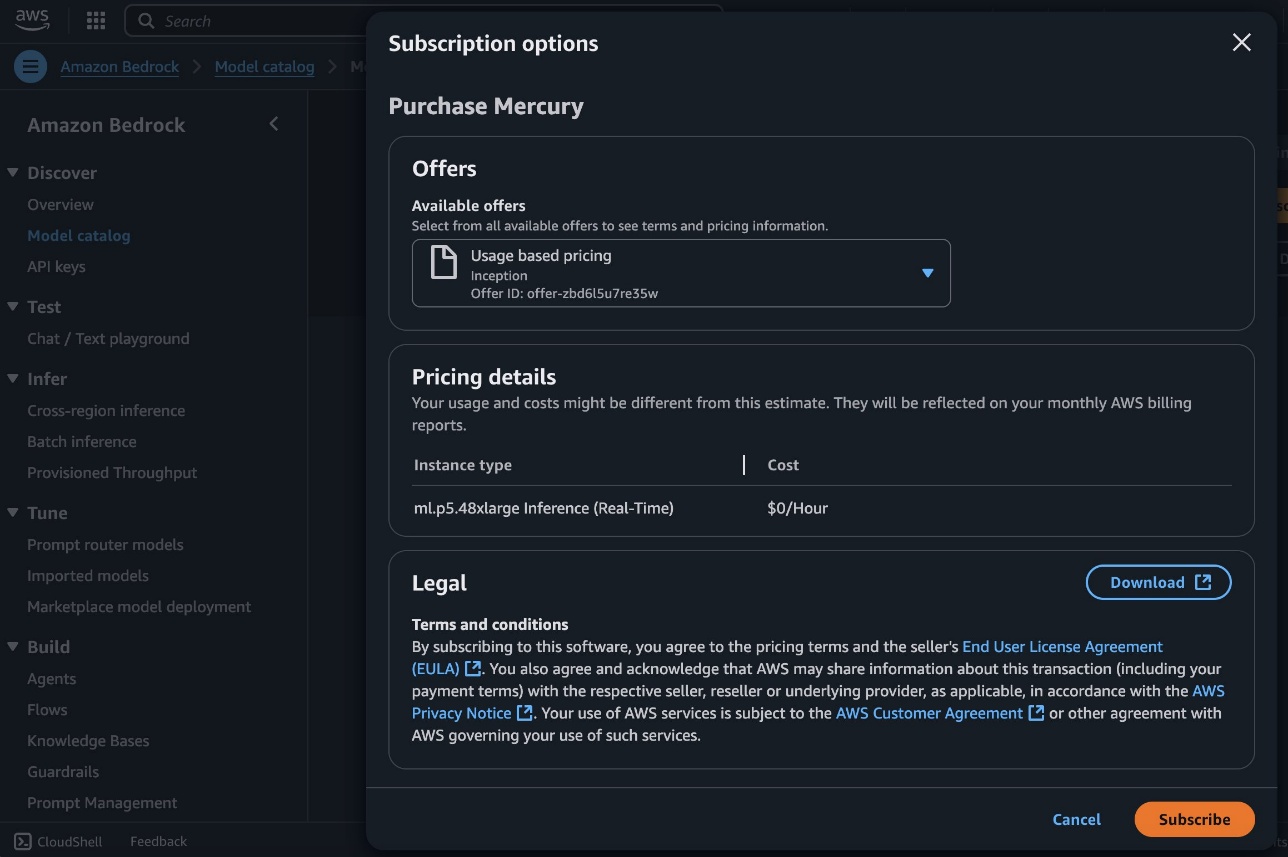
On the model detail page, choose Deploy.
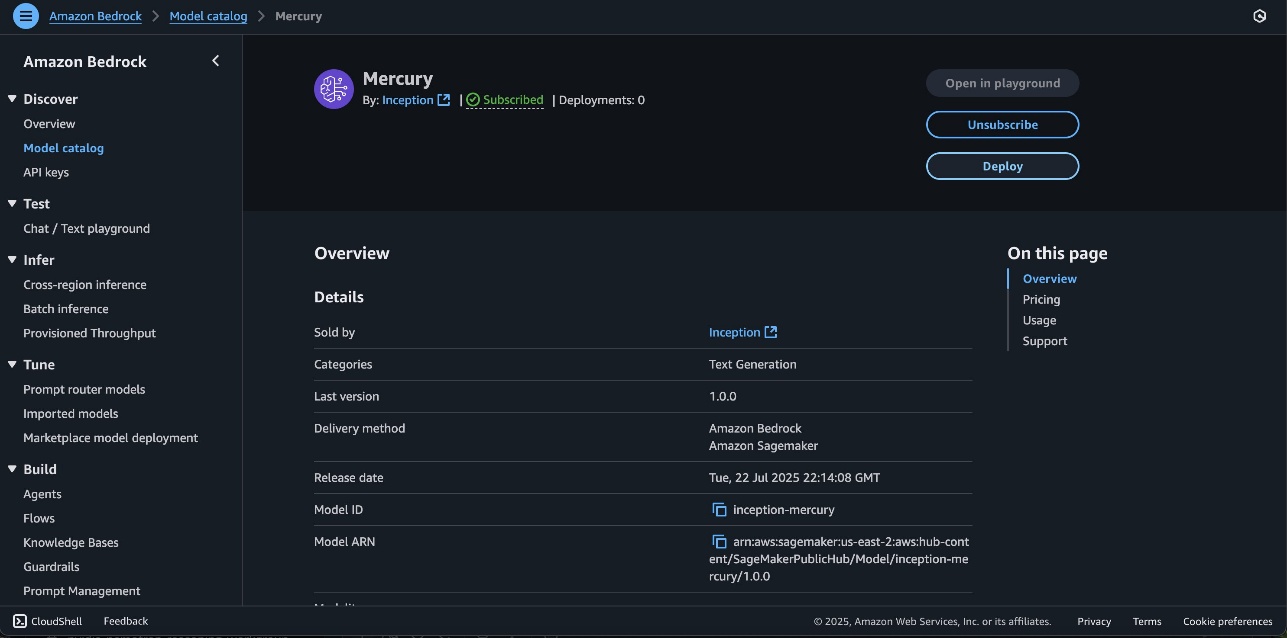
You will be prompted to configure the deployment details for the model. The model ID will be prepopulated.
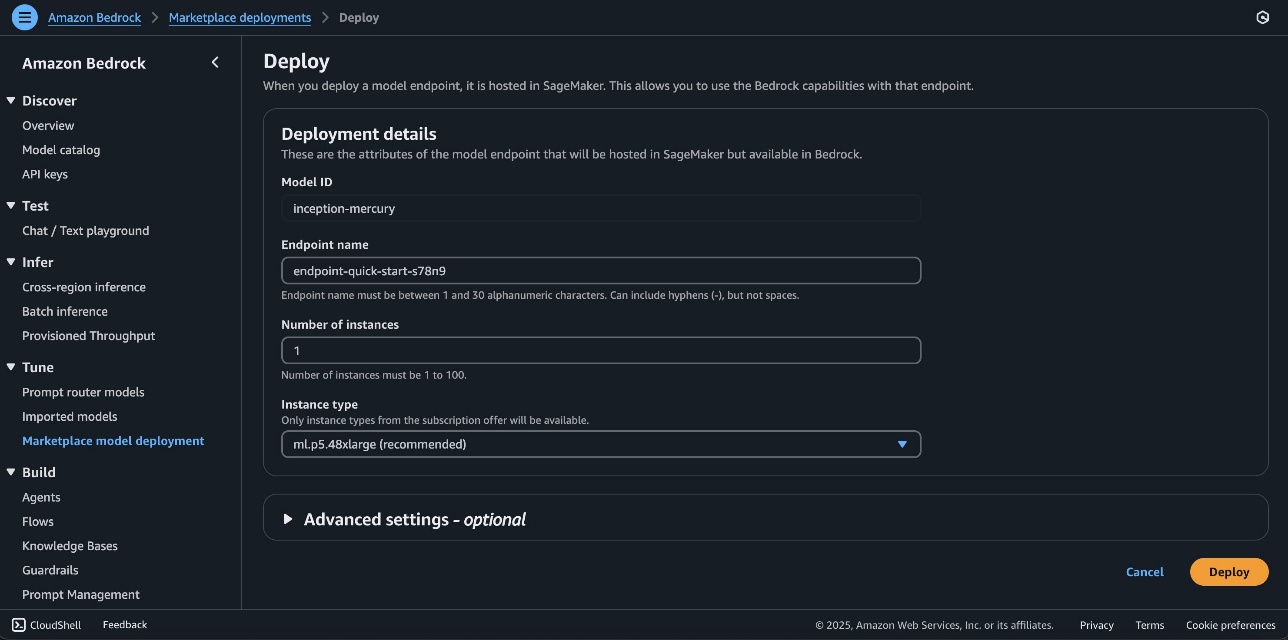
For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters).
For Number of instances, enter a number of instances (between 1–100).
For Instance type, choose your instance type. For optimal performance with Nemotron Super, a GPU-based instance type like ml.p5.48xlarge is recommended.
Optionally, you can configure advanced security and infrastructure settings, including virtual private cloud (VPC) networking, service role permissions, and encryption settings. For most use cases, the default settings will work well. However, for production deployments, you might want to review these settings to align with your organization’s security and compliance requirements.
Choose Deploy to begin using the model.
When the deployment is complete, you can test its capabilities directly in the Amazon Bedrock playground.This is an excellent way to explore the model’s reasoning and text generation abilities before integrating it into your applications. The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results. You can use these models with the Amazon Bedrock Converse API.
SageMaker JumpStart overview
SageMaker JumpStart is a fully managed service that offers state-of-the-art FMs for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
You can now discover and deploy Mercury and Mercury Coder in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, and derive model performance and MLOps controls with Amazon SageMaker AI features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in a secure AWS environment and in your VPC, helping support data security for enterprise security needs.
Prerequisites
To deploy the Mercury models, make sure you have access to the recommended instance types based on the model size. To verify you have the necessary resources, complete the following steps:
On the Service Quotas console, under AWS Services, choose Amazon SageMaker.
Check that you have sufficient quota for the required instance type for endpoint deployment.
Make sure at least one of these instance types is available in your target AWS Region.
If needed, request a quota increase and contact your AWS account team for support.
Make sure your SageMaker AWS Identity and Access Management (IAM) service role has the necessary permissions to deploy the model, including the following permissions to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptions
aws-marketplace:Unsubscribe
aws-marketplace:Subscribe
Alternatively, confirm your AWS account has a subscription to the model. If so, you can skip the following deployment instructions and start with subscribing to the model package.
Subscribe to the model package
To subscribe to the model package, complete the following steps:
Open the model package listing page and choose Mercury or Mercury Coder.
On the AWS Marketplace listing, choose Continue to subscribe.
On the Subscribe to this software page, review and choose Accept Offer if you and your organization agree with the EULA, pricing, and support terms.
Choose Continue to proceed with the configuration and then choose a Region where you have the service quota for the desired instance type.
A product Amazon Resource Name (ARN) will be displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
Deploy Mercury and Mercury Coder models on SageMaker JumpStart
For those new to SageMaker JumpStart, you can use SageMaker Studio to access the Mercury and Mercury Coder models on SageMaker JumpStart.
Deployment starts when you choose the Deploy option. You might be prompted to subscribe to this model through Amazon Bedrock Marketplace. If you are already subscribed, choose Deploy. After deployment is complete, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.
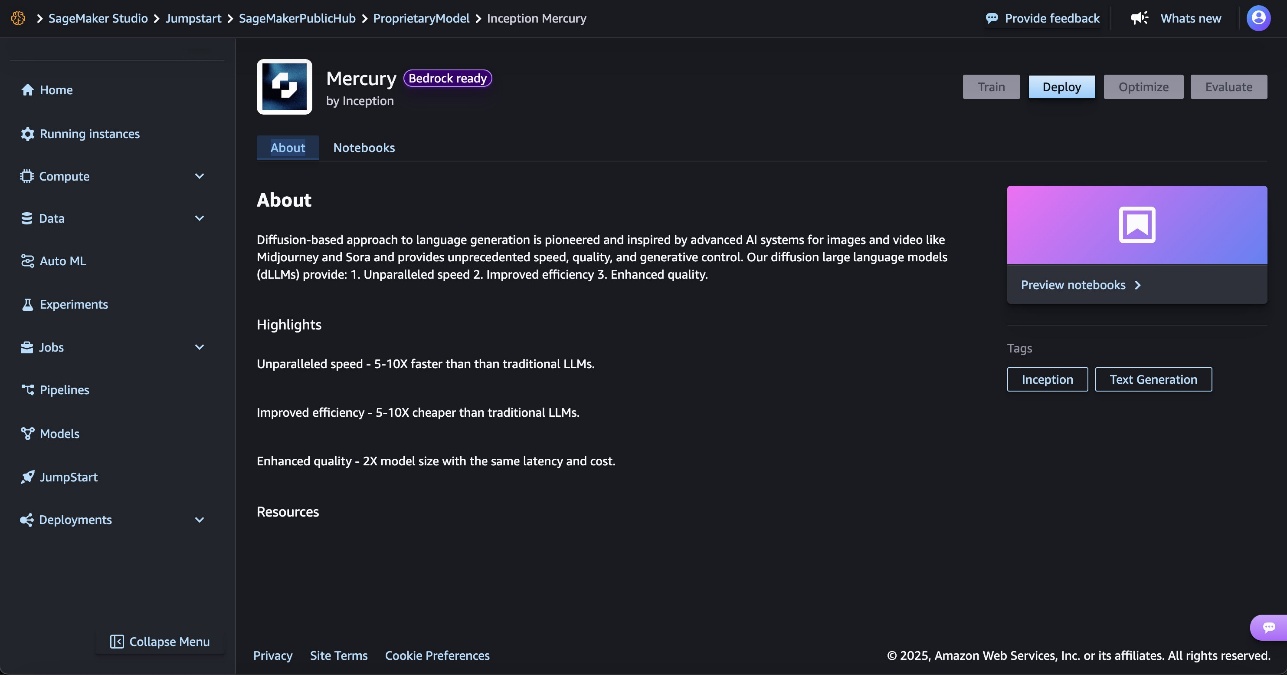
Deploy Mercury using the SageMaker SDK
In this section, we walk through deploying the Mercury model through the SageMaker SDK. You can follow a similar process for deploying the Mercury Coder model as well.
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
Deploy the model:
Use Mercury for code generation
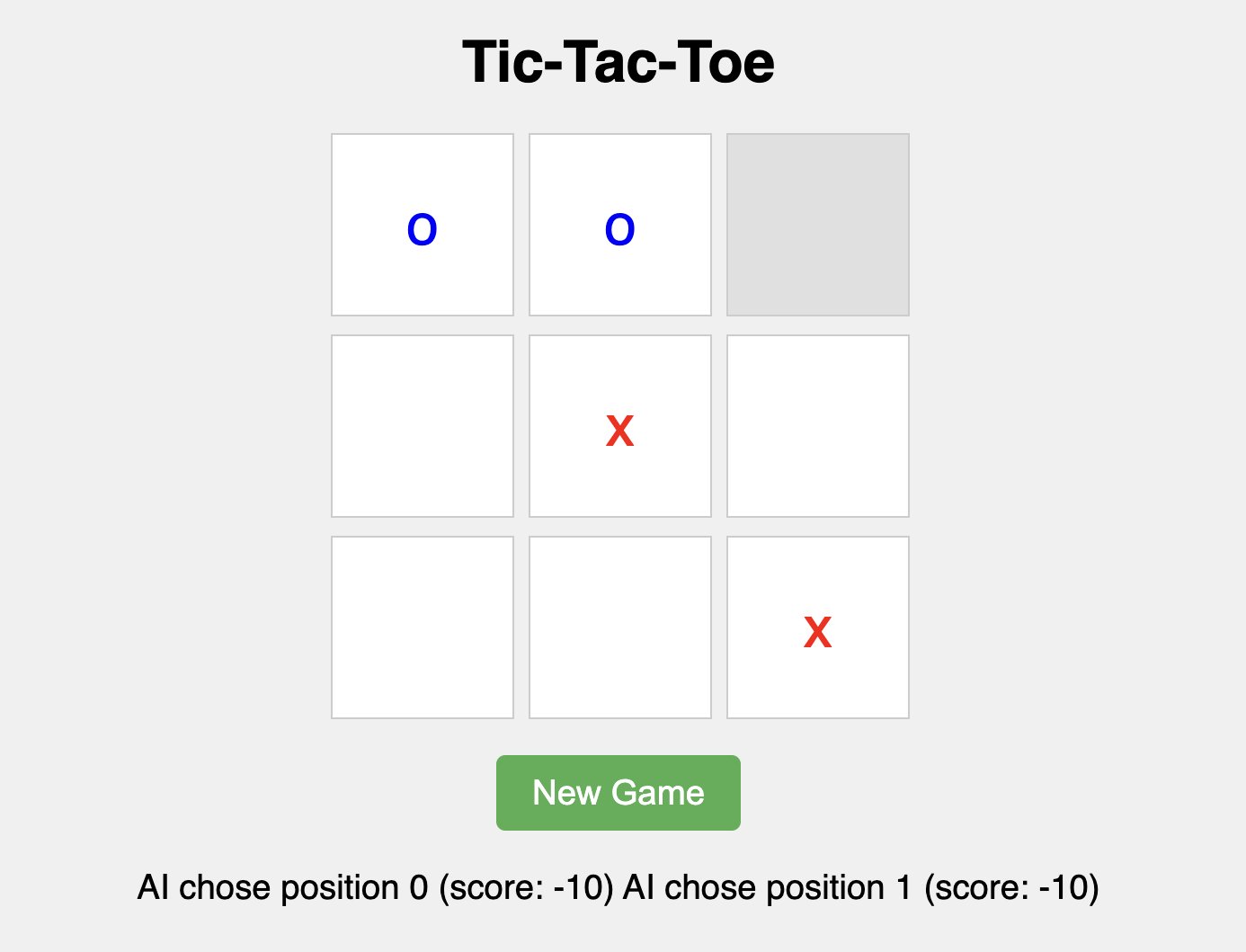
Let’s try asking the model to generate a simple tic-tac-toe game:
We get the following response:
From the preceding response, we can see that the Mercury model generated a complete, functional tic-tac-toe game with minimax AI implementation at 528 tokens per second, delivering working HTML, CSS, and JavaScript in a single response. The code includes proper game logic, an unbeatable AI algorithm, and a clean UI with the specified requirements correctly implemented. This demonstrates strong code generation capabilities with exceptional speed for a diffusion-based model.
Use Mercury for tool use and function calling
Mercury models support advanced tool use capabilities, enabling them to intelligently determine when and how to call external functions based on user queries. This makes them ideal for building AI agents and assistants that can interact with external systems, APIs, and databases.
Let’s demonstrate Mercury’s tool use capabilities by creating a travel planning assistant that can check weather and perform calculations:
Expected response:
After receiving the tool results, you can continue the conversation to get a natural language response:
Expected response:
Clean up
To avoid unwanted charges, complete the steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
On the Amazon Bedrock console, in the navigation pane, under Foundation models, choose Marketplace deployments.
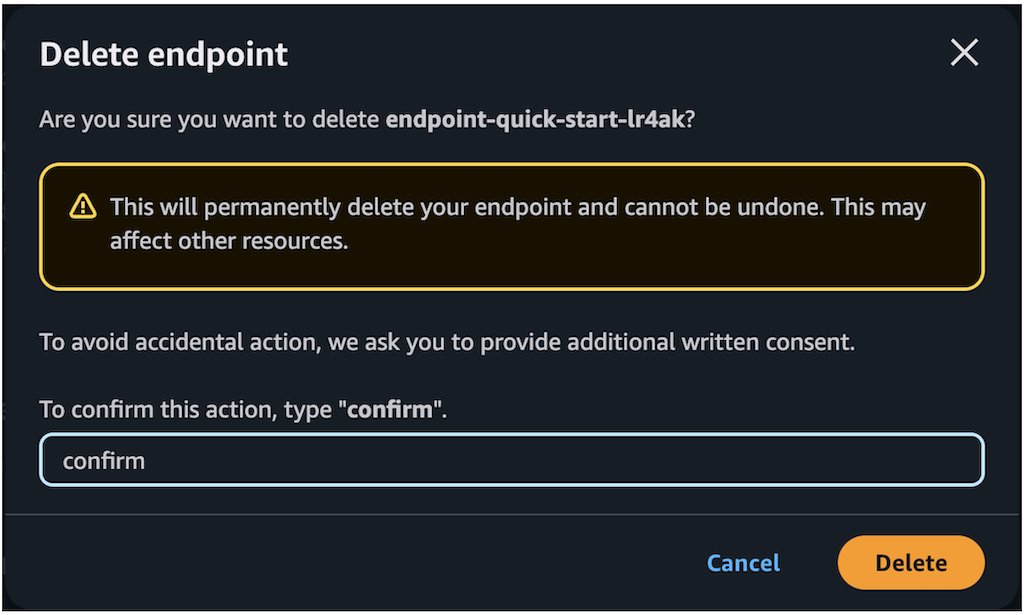
Select the endpoint you want to delete, and on the Actions menu, choose Delete.
Verify the endpoint details to make sure you’re deleting the correct deployment:
Endpoint name
Model name
Endpoint status
Choose Delete to delete the endpoint.
In the Delete endpoint confirmation dialog, review the warning message, enter confirm, and choose Delete to permanently remove the endpoint.
Delete the SageMaker JumpStart endpoint
The SageMaker JumpStart model you deployed will incur costs if you leave it running. Use the following code to delete the endpoint if you want to stop incurring charges. For more details, see Delete Endpoints and Resources.
Conclusion
In this post, we explored how you can access and deploy Mercury models using Amazon Bedrock Marketplace and SageMaker JumpStart. With support for both Mini and Small parameter sizes, you can choose the optimal model size for your specific use case. Visit SageMaker JumpStart in SageMaker Studio or Amazon Bedrock Marketplace to get started. For more information, refer to Use Amazon Bedrock tooling with Amazon SageMaker JumpStart models, Amazon SageMaker JumpStart Foundation Models, Getting started with Amazon SageMaker JumpStart, Amazon Bedrock Marketplace, and SageMaker JumpStart pretrained models.
The Mercury family of diffusion-based large language models offers exceptional speed and performance, making it a powerful choice for your generative AI workloads with latency-sensitive requirements.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
 John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
 Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption for first- and third-party models. Breanne is also Vice President of the Women at Amazon board with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from the University of Illinois Urbana-Champaign.
Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption for first- and third-party models. Breanne is also Vice President of the Women at Amazon board with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from the University of Illinois Urbana-Champaign.