

Imagine an AI system capable of guiding a robot to manipulate physical objects as effortlessly as it navigates software menus. Such seamless integration of digital and physical tasks has long been the stuff of science fiction.
Today, Microsoft researchers are bringing that vision closer to reality with Magma (opens in new tab), a multimodal AI foundation model designed to process information and generate action proposals across both digital and physical environments. It is designed to enable AI agents to interpret user interfaces and suggest actions like button clicks, while also orchestrating robotic movements and interactions in the physical world.
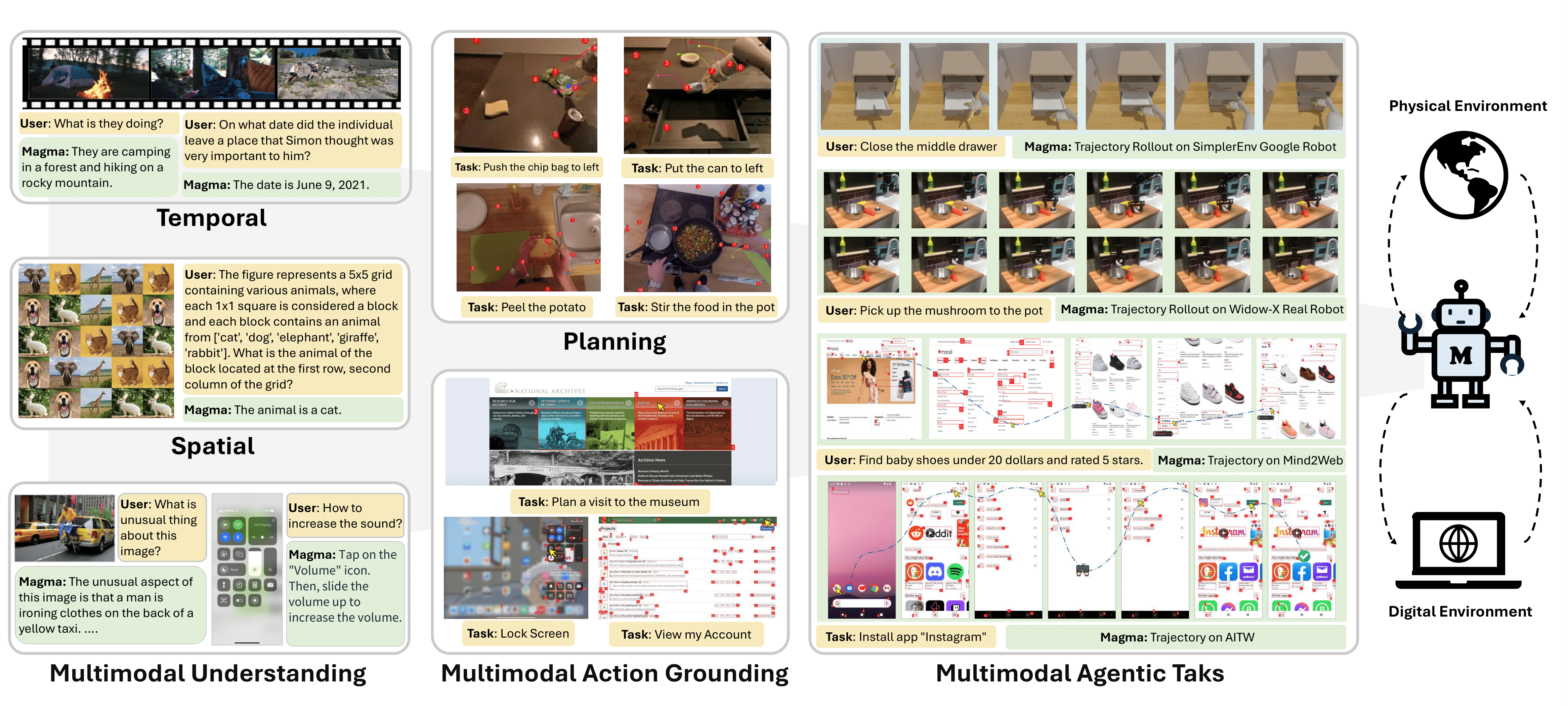
Built on the foundation model paradigm, Magma is pretrained on an expansive and diverse dataset, allowing it to generalize better across tasks and environments than smaller, task-specific models. As illustrated in Figure 1, Magma synthesizes visual and textual inputs to generate meaningful actions—whether executing a command in software or grabbing a tool in the physical world. This new model represents a significant step toward AI agents that can serve as versatile, general-purpose assistants.
Microsoft research podcast
What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
Vision-Language-Action (VLA) models integrate visual perception, language comprehension, and action reasoning to enable AI systems to interpret images, process textual instructions, and propose actions. These models bridge the gap between multimodal understanding and real-world interaction. Typically pretrained on large numbers of VLA datasets, they acquire the ability to understand visual content, process language, and perceive and interact with the spatial world, allowing them to perform a wide range of tasks. However, due to the dramatic difference among various digital and physical environments, separate VLA models are trained and used for different environments. As a result, these models struggle to generalize to new tasks and environments outside of their training data. Moreover, most of these models do not leverage pretrained vision-language (VL) models or diverse VL datasets, which hampers their understanding of VL relations and generalizability.
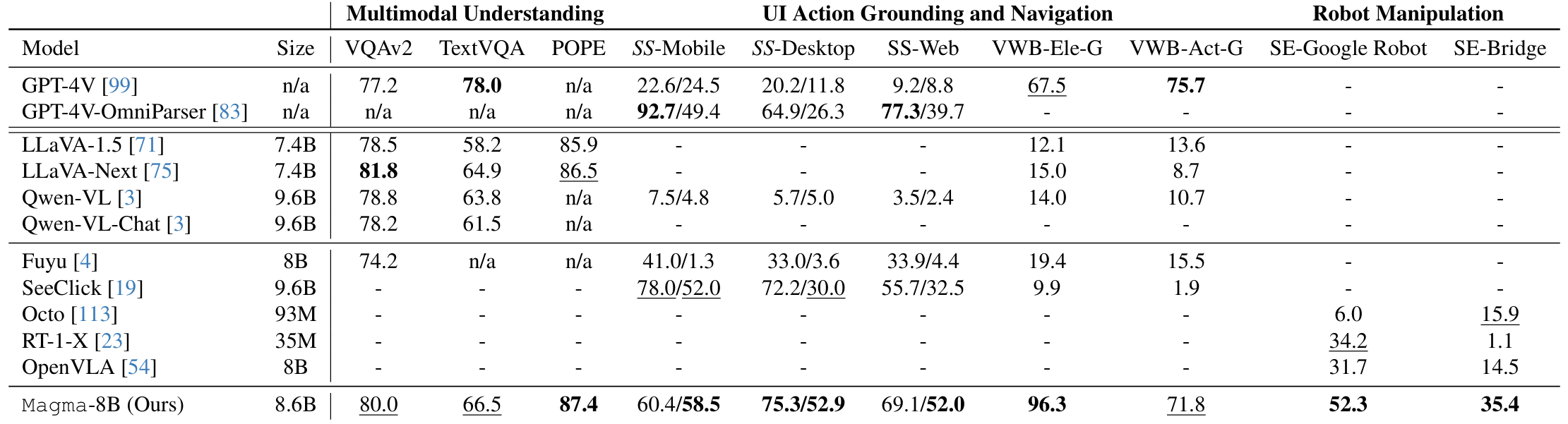
Magma, to the best of our knowledge, is one of the first VLA foundation model that can adapt to new tasks in both digital and physical environments, which helps AI-powered assistants or robots understand their surroundings and suggest appropriate actions. For example, it could enable a home assistant robot to learn how to organize a new type of object it has never encountered or help a virtual assistant generate step-by-step user interface navigation instructions for an unfamiliar task. Through Magma, we demonstrate the advantages of pretraining a single VLA model for AI agents across multiple environments while still achieving state-of-the-art results on user interface navigation and robotic manipulation tasks, outperforming previous models that are tailored to these specific domains. On VL tasks, Magma also compares favorably to popular VL models that are trained on much larger datasets.
Building a foundation model that spans such different modalities has required us to rethink how we train and supervise AI agents. Magma introduces a novel training paradigm centered on two key innovations: Set-of-Mark (SoM) and Trace-of-Mark (ToM) annotations. These techniques developed by Microsoft Research, imbue the model with a structured understanding of tasks in both user interface navigation and robotic manipulation domains.
Set-of-Mark (SoM): SoM is an annotated set of key objects, or interface elements that are relevant to achieving a given goal. For example, if the task is to navigate a web page, the SoM includes all the bounding boxes for clickable user interface elements. In a physical task like setting a table, the SoM could include the plate, the cup, and the position of each item on the table. By providing SoM, we give Magma a high-level hint of “what needs attention”—the essential elements of the task—without yet specifying the order or method.

Trace-of-Mark (ToM): In ToM we extend the strategy of “overlaying marks” from static images to dynamic videos, by incorporating tracing lines following object movements over time. While SoM highlights key objects or interface elements relevant to a task, ToM captures how these elements change or move throughout an interaction. For example, in a physical task like moving an object on a table, ToM might illustrate the motion of a hand placing the object and adjusting its position. By providing these temporal traces, ToM offers Magma a richer understanding of how actions unfold, complementing SoM’s focus on what needs attention.

Performance and evaluation
Zero-shot agentic intelligence
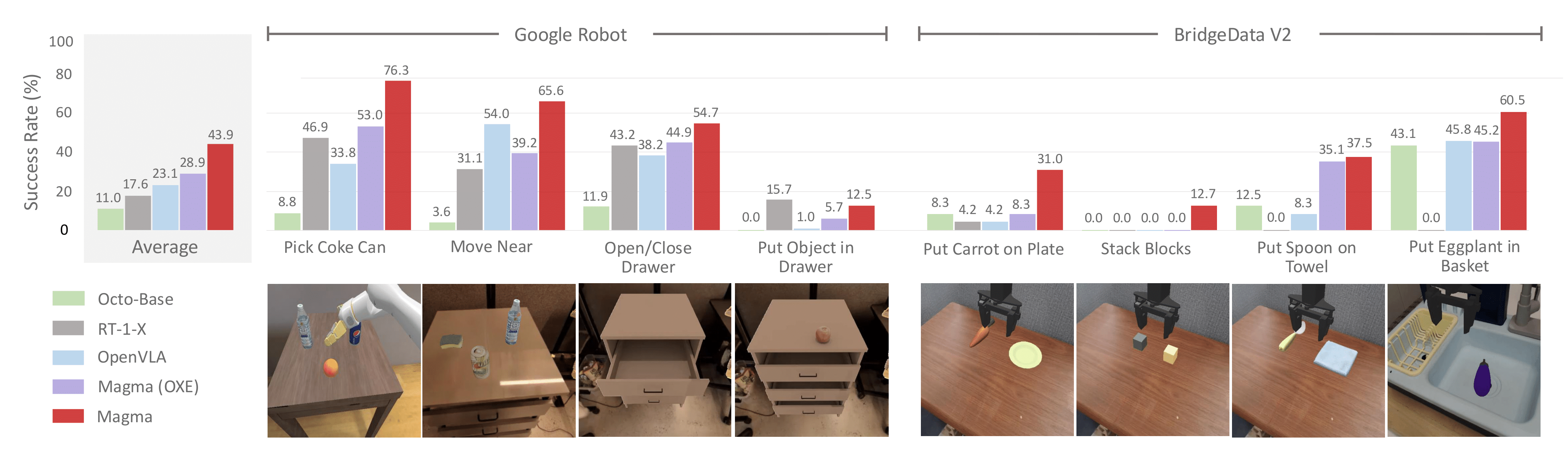
Efficient finetuning
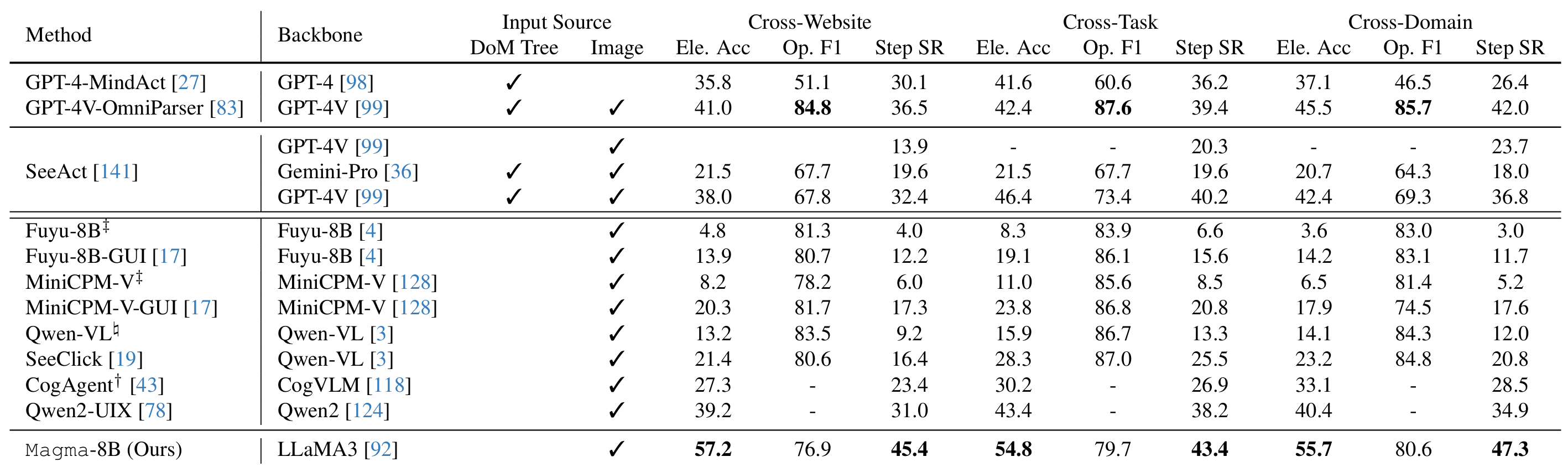
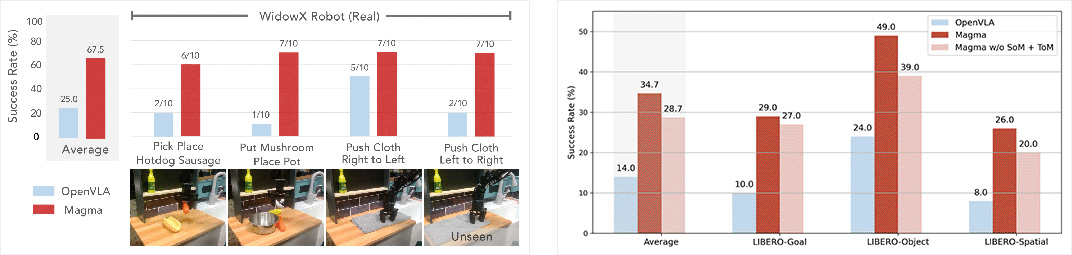
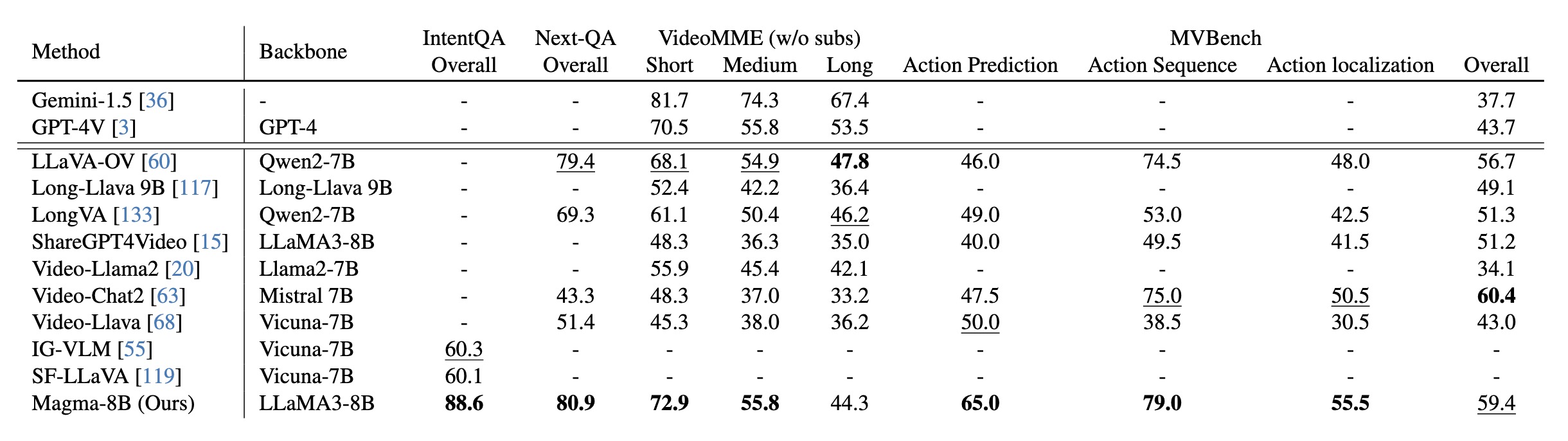
Relation to broader research
Magma is one component of a much larger vision within Microsoft Research for the future of agentic AI systems. Across various teams and projects at Microsoft, we are collectively exploring how AI systems can detect, analyze, and respond in the world to amplify human capabilities.
Earlier this month, we announced AutoGen v0.4, a fully reimagined open-source library for building advanced agentic AI systems. While AutoGen focuses on the structure and management of AI agents, Magma enhances those agents by empowering them with a new level of capability. Developers can already use AutoGen to set up an AI assistant that leverages an LLM for planning and dialogue using conventional LLMs. Now with MAGMA, if developers want to build agents that execute both physical or user interface/browser tasks, that same assistant would call upon Magma to understand the environment, perform reasoning, and take a sequence of actions to complete the task.
The reasoning ability of Magma can be further developed by incorporating test-time search and reinforcement learning, as described in ExACT. ExACT shows an approach for teaching AI agents to explore more effectively, enabling them to intelligently navigate their environments, gather valuable information, evaluate options, and identify optimal decision-making and planning strategies.
At the application level, we are also exploring new user experience (UX) powered by foundation models for the next generation of agentic AI systems. Data Formulator is a prime example. Announced late last year, Data Formulator, is an AI-driven visualization tool developed by Microsoft Research that translates high-level analytical intents into rich visual representations by handling complex data transformations behind the scenes.
Looking ahead, the integration of reasoning, exploration and action capabilities will pave the way for highly capable, robust agentic AI systems.
Magma is available on Azure AI Foundry Labs (opens in new tab) as well as on HuggingFace (opens in new tab) with an MIT license. Please refer to the Magma project page (opens in new tab) for more technical details. We invite you to test and explore these cutting-edge agentic model innovations from Microsoft Research.