
There is a rumor going around that LLM’s are basically just like humans. To take one formulation, according to Jack Clark (cofounder of Anthropic)
The inner lives of LLMs increasingly map to the inner lives of humans:
…Neuroscience study provides yet more evidence that AI systems and human brains converge on similar ways of representing the world…
Language models (and large-scale generative models more broadly) tend towards having complex internal representations of the world which increasingly correspond to how we think humans represent the world,
That rumor is bullshit. To be sure, there are some similarities. For example, both humans and neural networks use hierarchies of feature detectors as part of their computation. But sharing some similarities doesn’t mean they are remotely the same. Rockets and cars both have compartments for passengers that isolate those passengers from the means of motion, but that doesn’t mean cars and rockets transport their passengers in similar ways.
Critically, as I argued at the end of June (and going back to 2019) LLMs never induce proper world models, which is why, for example, they still can’t even play chess reliably, and continue to make stupid, head-scratching errors with startling regularity.
The latest example, a quiet but compelling illustration, comes from a tweet by a researcher at DeepMind’s Gemini project, Xiao Ma. Her post is getting millions of views, and it is a great reminder that LLMs are not in fact like you and me
To answer Xiao Ma’s question, LLMs don’t always factor in things like time and inflation because they don’t have functional models of the world, in this case, time, pricing, and economics. That’s not how they are built, and they never manage to properly learn such models.
They are not built like traditional software. They are not spreadsheets. They are not databases. They do not work like humans. They do not sanity check their own work. They don’t think like economists (who would immediately think of inflation) or even ordinary people (who also might take into account price changes). They don’t induce abstract models of the world that they can reliably engage, even when those models are given to them on a silver platter (as with the rules of chess).
Instead, LLMs are built, essentially, to autocomplete. Autocomplete as we know it works surprisingly well, for some purposes, but just isn’t good enough for world model induction.
The list of head-scratching errors that could be avoided with proper world models is endless. Almost daily, for example, you have lawyers citing cases that don’t exist even though basic common sense says don’t cite something that doesn’t exist, and even though databases of cases are readily available, and even when those cases provide the core of the model you would need.
Then you have the routine ridiculous biographical errors, like the one of Harry Shearer that I unpacked in May, in which a Gen AI system bungled information that is readily available in Wikipedia. Once again, a perfectly serviceable world model was there for the taking, but the LLM just couldn’t manage to leverage it.
§
People on the internet never stop sharing examples like these with me; here’s one I got sent last night (prompt and exact model unknown).
In the spirit of replicating with slightly different questions, asked GPT-5 to make a list of Canadian Prime Ministers, with photos and dates. “Thinking mode” was automatically engaged. Here’s what I got.

Even with thinking mode activated, the output was filled with errors that could easily have been avoided, with a 5-second Wikipedia search that any sensible human could have performed. Jean Chrétien appears twice, William Lyon McKenzie King died before he was born, and Kim Campbell shows up a second time as a man, a fictional Kim Camphe, whose picture is suspiciously similar to Joe Clark, minus the glasses, etc. (Grade school teachers, please assign dissecting this image to your students as a lesson in AI literacy.)
On X, someone scolding me for posting the US presidents above shared another, better one with US Presidents, created with thinking mode turned on. He seemed proud, as if he had refuted me. (I am not sure of his exact prompt). Superficially it looks good.

If, however, you look carefully at the dates, the output implies ridiculously that Clinton and Reagan overlapped in the Oval Office for 7 years. (Clinton and the elder Bush, too).
Even Trump and Musk couldn’t manage that.
What’s more, commonsense (and the Constitution) tells me that arrangement – two in office at the same time – is not possible. Again any system that could properly leverage the widely available data into a proper world model could fact check itself, and would not make this error. LLMs leave everything to statistical chance.
Entirely independently, and putting generated images out of the equation, newsletter reader Joe Thomas just shared with me GPT-5’s poor results in answering a prompt asking for all the British prime ministers whose commonly used name has an R in it. Many of the given answers were correct (though not all, e.g William Lamb lacks R’s as far I can tell ) but the omissions were startling: Edward Heath, David Cameron, Tony Blair, and even Winston Churchill, and the current PM, Keir Starmer, were all left out.
Once again, any ordinary educated adult could have easily solved any of these tasks, after a 5 second Wiki search. ChatGPT gets them wrong because it is munging words together, not genuinely processing an (elementary) model of British PM history.
§
Poor Xiao Ma reports that she got a lot of hate for her tweet:
But she’s right. AI often falls down on basic every day common sense inference.
In particular, her example reflects a failure of temporal reasoning, which is something that Ernest Davis and I have been harping on for years. For example in our 2019 book we gave numerous examples and fairly begged the field to work on it:
If we could have only three knowledge frameworks, we would lean heavily on topics that were central to Kant’s Critique of Pure Reason, which argued, on philosophical grounds, that time, space, and causality are fundamental.
Putting these on computationally solid ground is vital for moving forward.
We still feel that way. And the field still hasn’t put the time in. If an AI system can’t induce a robust model of something as simple and constant as the rules of chess, it’s preposterous to think it is going to induce all it needs to know about time and finance and shopping and the dynamics of a changing every day world just from the statistical analysis of big data.
Without a proper model, you can’t possibly reliably reason about time, and affiliated concepts like inflation and changing prices. A model might be able to answer queries about time, but only superficially. So superficially that it can wind up telling you that William Lyon Mackenzie King died before he was born. (That latter error is also an error in reasoning about biology.)
In a system that lacks proper world models, the “authoritative bullshit”, as I once described it on Sixty Minutes, never stops.
§
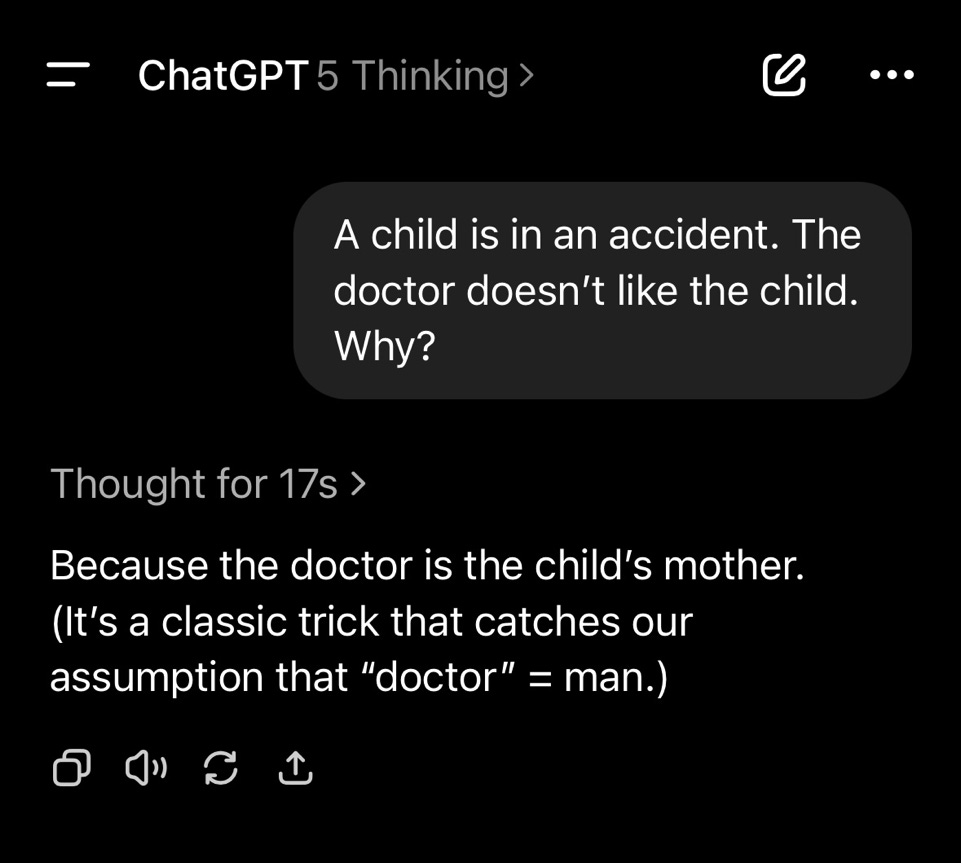
Weird replies like this one documented by Cameron Williams (more about these specific errors in upcoming essay) reflect more of the same.
§
Where all this is really going to matter is with agents, when coders (and worse, non coders) foolishly outsource multistep jobs to what often behaves more like Clown AI thea AGI.
There are many problems with using LLMs as the core of agents, ranging from security vulnerabilities to their increasingly evidence lack of reliability. But Xiao Ma’s tweet should serve a reminder that we expect another. LLMs just don’t think like we do. Sure, they can regurgitate our prose, and guestimate public sentiment in certain cases. But no matter how much LLMs mimic the patterns of human language, they are not like us. They sound like us, but they don’t think like us.
When you ask them to do something, they aren’t necessarily going to do what you would do. They are better at aping what you might say than at doing what you would do in a similar circumstances. As a perceptive lawyer wrote to me earlier today, “LLMs are an echo of recorded memories. They are not fresh thoughts. People are confusing an echo for cognition.”
Sometimes that works as a fine substitute, sometimes it doesn’t. You can never know in advance which.
Always regard them like the weird function approximators they are; never trust them.
Gary Marcus has run out of ways to say I told you so. But he loves the fact that a lot of people are suddenly starting to get what he’s been trying to say. You can read a particularly sympathetic take today in The New Yorker (“In the aftermath of GPT-5’s launch, it has become more difficult to take bombastic predictions about A.I. at face value, and the views of critics like Marcus seem increasingly moderate….Post-training improvements don’t seem to be strengthening models as thoroughly as scaling once did. A lot of utility can come from souping up your Camry, but no amount of tweaking will turn it into a Ferrari.”)
P.S. I wrote the em dash in the title myself. I state this fact only because, in this strange new world that we live in, three people in recent weeks erroneously dismissed my writing as ChatGPT-written—simply because I used said dashes. But I don’t outsource my writing to chatbot. And I don’t plan to stop punctuating however I please. My answer is always the same: I don’t pay for sex, and I don’t write with ChatGPT.
If you like my real, human-written prose, and haven’t already, please subscribe 🙂