
Experiments were carried out to determine the effectiveness of the proposed method to assess the influence of customer emotions expressed during contact center hotline conversations on the accuracy of intent recognition. Recognizing that performance can be sensitive to input data quality, three sets of experiments were performed. This approach acknowledges the importance of data quality in evaluating machine-learning models, particularly in the context of customer service interactions where nuanced language and emotional expression can significantly affect performance. By conducting multiple experiments with varying data characteristics, the researchers aim to provide a more robust evaluation of their method and its ability to accurately discern customer intent despite the presence of emotionally charged language. Further details on the experimental setup, data sets, and evaluation metrics would be beneficial for a comprehensive understanding of the study’s findings.
Dataset description
This dataset of tweets annotated with 13 emotion categories across 40,000 records presents a complex multiclass classification challenge, especially when applied to a customer service context. The existing structure (tweet_id, sentiment, content) is a good starting point, but enhancements will be needed for practical application in a customer service setting. The cited resources offer various strategies for handling multiclass classification and imbalanced datasets, which could be adapted and applied to this specific emotion recognition task. This dataset is publicly available and sourced from data.world, a platform for data sharing and collaboration. It is released under a Public License, which allows for its free use and distribution.
Limitation
While the Kaggle tweet corpus provides a large and diverse sample of spontaneous emotional expressions, its inherent brevity, informality, and public nature may not fully capture the multi-turn dialogue structure, domain-specific terminology, and paralinguistic cues (e.g., pauses, tone variations) characteristic of real-world contact center interactions. Tweets lack conversational context and turn-taking patterns essential to customer service scenarios, which could hinder model generalization.
Future work
Will therefore focus on curating and annotating an authentic corpus of contact center chat or call transcripts, exploring domain-adaptation strategies—including fine-tuning on in-domain data and adversarial training—and evaluating model transferability in live operational settings to ensure robust performance across domains.
Simulation results
In customer service, leveraging emotional cues within customer utterances can enhance chatbot effectiveness. This method uses a proposed model to discern customer intent, informing appropriate actions. BERT’s contextualized word embeddings capture nuanced language and emotional tone, while the BiLSTM layer processes these embeddings sequentially, identifying long-range dependencies and emotional flow. This architecture facilitates robust emotion detection, surpassing keyword matching to understand the customer’s true emotional state. The detected emotion and customer text then construct a prompt for a generative AI model (e.g., BART or T5), guiding the generation of contextually appropriate and empathetic responses. For instance, if frustration is detected, the AI can craft a response acknowledging the customer’s feelings and offering assistance. This approach recognizes the impact of emotional state on customer intent. While textual analysis alone might suggest one intent, the emotional context can reveal a different, emotionally driven one. A customer expressing anger, for example, might still be receptive to a solution if their emotional state is addressed. Ignoring this can lead to inappropriate chatbot behavior and negative customer experiences. By incorporating emotional context through the proposed model and leveraging generative AI, chatbots can provide more effective and empathetic support, improving dialogue quality and user satisfaction. This underscores the importance of emotional context in conversational AI, especially in sensitive domains like customer service. Further research exploring the interplay between emotion and intent in customer service interactions can enhance the development of more sophisticated and context-aware conversational agents. The complexity of emotion detection in text necessitates robust models like the proposed architecture, capable of capturing nuanced emotional expressions and their influence on user intent.
Read the dataset
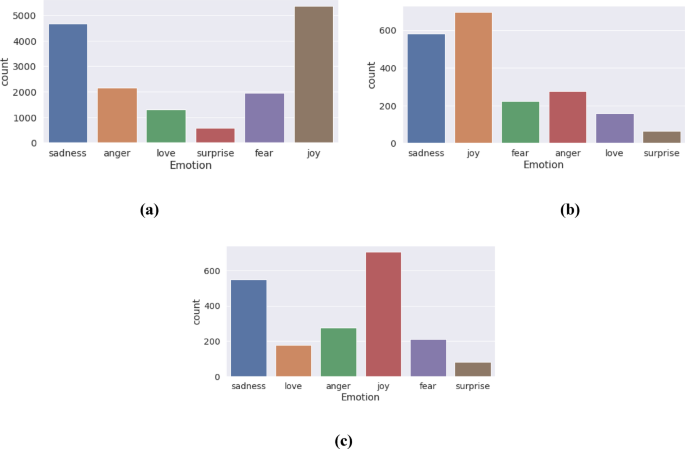
The provided code snippet reads three datasets related to text and emotion analysis. Each dataset is loaded into a pandas DataFrame using the read_csv function. The datasets, presumably for training, validation, and testing, are named df_train, df_val, and df_test, respectively. Figure 3 shows the Emotion detection dataset from Text and NLP, where the train data, test data and validation data samples are represented in Fig. 3 (a), (b) and (c). The data is assumed to be in a delimited text format, with columns separated by semicolons. The column names are explicitly set as ‘Text’ and ‘Emotion’. This suggests a common structure across the three datasets, where ‘Text’ likely contains textual data (e.g., sentences or tweets) and ‘Emotion’ contains the corresponding emotion labels. This method of loading data is standard practice in data analysis and machine learning, allowing for efficient manipulation and processing of tabular data. The explicit naming of columns ensures clarity and consistency in subsequent data operations. Separate test sets and training are necessary when it comes to assessing the effectiveness of machine learning. They can help prevent overfitting and ensure that the models are working properly.

Distribution of training (a), test (b), and validation (c) samples across the six emotion classes in the tweet corpus. (a) Train data. (b) Test data. (c) Validation data.
Data balancing techniques
Several strategies were employed to address this imbalance (Fig. 4). The data imbalanced graph of train data, test data and validation data are shown in Fig. 4 (a), (b) and (c). A balanced training set was established by randomly selecting the data from each of the classes shown. This ensures that the results are representative of the population. This approach, while simple, can be effective for moderately imbalanced datasets. Second, data augmentation was performed by dividing longer recordings into smaller segments, effectively increasing the number of samples in underrepresented classes. This technique is commonly used to address class imbalance. Finally, more advanced methods, such as ensemble classifiers with internal sampling techniques, were also utilized. These methods often provide more robust solutions for complex imbalance problems. The Python library ‘imbalanced-learn’ was used to implement and evaluate various balancing methods, facilitating a comprehensive exploration of suitable techniques for this specific dataset.
Class-wise sample-count distributions in the training (a), test (b), and validation (c) sets, before and after applying imbalance-handling methods. (a)Train data. (b) Test data. (c) Validation data.
The dataset exhibits a class imbalance, where certain emotions (joy, sadness) have substantially more samples than others (love, surprise). While this imbalance could potentially bias the model, the current focus on the most frequent emotions may justify postponing balancing techniques. Specifically in training dataset, the distribution of joy (5362 samples), sadness (4666 samples), and anger (2159 samples) suggests these are the dominant emotions in the dataset. If the primary research interest lies in these prevalent emotions, training a model on the imbalanced data may still yield valuable insights. This test data represents a count of emotions, with joy being the most prevalent (695 instances), followed by sadness, anger, fear, love, and surprise. The dataset likely pertains to a corpus of text or other expressive data where emotions have been identified and categorized. The higher frequency of joy and sadness might reflect a bias in the data source or the tendency of these emotions to be more readily expressed or detected. The relatively lower counts for love and surprise could indicate that these emotions are less frequently represented in the dataset or are more challenging to identify accurately. This validation data shows the distribution of six emotions within a validated dataset: joy (704 instances), sadness, anger, fear, love, and surprise. The prevalence of joy and sadness suggests these are the most frequently occurring emotions In this dataset, it’s important to take into account the collection and source methods.
Removing duplicate data
The code snippet identifies and removes duplicate rows within the df_train DataFrame. The first line identifies the indices of duplicate rows using the duplicated() method. The duplicated() method, by default, considers all columns when identifying duplicates. The subsequent line removes these rows using the drop() method, modifying the DataFrame in place. The method reset_index() takes the DataFrame and adds it back to its original state, ensuring that there is a contiguous index. It does this by checking the drop parameter and preventing the old index from being used as a new column. The comment suggests the intent to identify and print rows with duplicated text but different emotions.The keep = False argument marks all duplicate rows as True, allowing for the retrieval of all occurrences of the duplicated text. This approach ensures that all rows with the same text, but potentially different emotions, are identified and printed. This is crucial for understanding the extent and nature of duplication within the dataset, especially when the text content is of primary interest, as suggested by the provided context. It is important to identify and handle duplicate data, as this can have a significant impact on the reliability and performance of learning models.
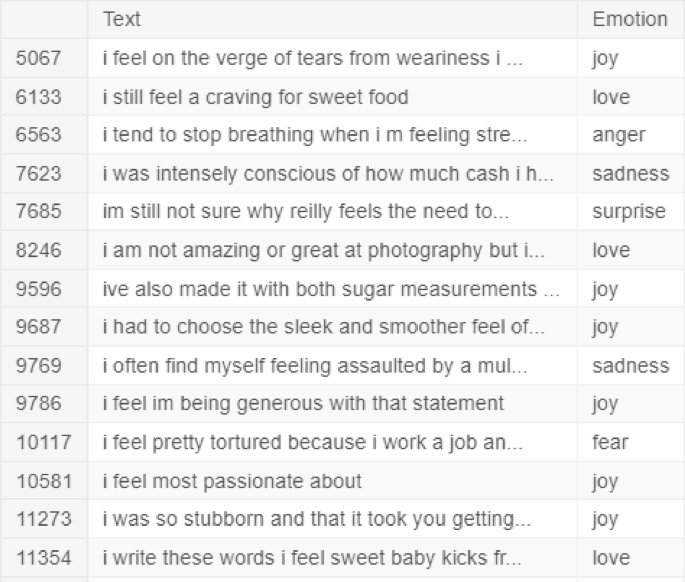
Duplicated in the text but with different emotions.
In sentiment analysis of text data, particularly within an emotion dataset, the prevalence of stop words necessitates a cautious approach to their removal. Overly aggressive removal, especially when some entries contain a substantial number of stop words (e.g., exceeding 25), risks stripping away valuable contextual information and emotional nuances, potentially rendering the data meaningless. Figure 5 shows Duplicated in the text but with different emotions. Which emphasizes the importance of balancing stop word removal with the preservation of meaningful content. Further underscores the practical significance of this balance, particularly in large datasets, where excessive removal can negatively impact categorization effectiveness. As noted in stemming and stop word removal are resource-intensive processes, and their impact on accuracy needs careful consideration.
Several strategies can mitigate this risk in the context of emotion analysis. First, consider employing a domain-specific stop word list or customizing a standard list (e.g., NLTK) to retain emotionally charged terms relevant to the specific emotion lexicon. For example, words like “not” or “very,” while typically considered stop words, can significantly alter the emotional valence of a sentence. Second, instead of complete removal, explore weighting schemes like TF-IDF which reduces the influence of frequent terms (including stop words) without eliminating them entirely. This approach allows leveraging contextual information embedded in stop words while mitigating their potential to skew the analysis. Finally, as points out, stop word removal aims to improve the signal-to-noise ratio. Therefore, carefully evaluate the impact of different removal strategies on the information content of your emotion data, ensuring that the “noise” removed does not comprise essential emotional cues.
Improving text retrieval with TF-IDF
Term frequency-inverse document frequency weighting addresses the limitations of simple word counts in text analysis. High-frequency words, often insignificant (e.g., stop words), dominate word counts. TF-IDF mitigates this by considering both a term’s frequency within a document and its prevalence across the entire corpus. Rare terms across the corpus receive higher weights (high IDF), while terms frequent within a specific document also contribute significantly (high TF). A term unique to a document achieves the maximum TF-IDF score of 1, while a term present in all documents except the one being considered receives a score of 0. Common terms appearing frequently in both the target document and the corpus receive a low TF-IDF score due to a high TF counteracted by a much higher IDF, effectively diminishing their importance.
Proposed modelling BERT-Bi-LSTM
The initial step involves loading the tweet dataset using the pandas library. A critical preprocessing stage is the transformation of categorical sentiment labels (e.g., “anger,” “joy”) into numerical representations, a necessary step as neural networks operate on numerical data (see Fig. 3). This mapping is facilitated by a dictionary, emotion_mapping. The datasets have been divided into test and training sets. Stratified sampling is employed during this split to maintain a consistent class distribution across both sets, a particularly important consideration when dealing with imbalanced datasets. The model training phase, while currently simplified, instantiates the BERT_BiLSTM_Emotion_GenAI model and assigns it to the appropriate computational device (GPU or CPU). However, the provided training loop requires substantial development for practical application. A complete training procedure necessitates the definition of a suitable loss function, In addition to the optimization algorithm known as Adam, other factors such as the selection of a suitable cross-class classification framework and data loader implementation are also taken into account to improve the training process. The iterative approach to training involves carrying out weight updates and forward and backward passes.

Method to visualize the model architecture.
Figure 6 shows the Method to visualize the model architecture. The proposed -Emotion-GenAI model enhances chatbot responses by incorporating emotion recognition. It works in three steps. First, BERT analyzes the customer’s text, creating contextualized word embeddings that capture nuances in language and emotional tone. These embeddings are then processed by a BiLSTM network, which identifies long-range dependencies and emotional flow within the text. This combination allows the model to understand the customer’s true emotional state, going beyond simple keyword matching. Second, the detected emotion and the customer’s original text are used to create a prompt for a generative AI model (like BART or T5). This prompt guides the AI in generating a suitable and empathetic response. Finally, the generative AI creates a response that considers both the content and emotional context of the customer’s message. For example, if the model detects frustration, the response might acknowledge the customer’s feelings and offer assistance. This approach recognizes the importance of emotions in shaping customer intent, leading to more effective communication and a better customer experience. Which implemented using the Keras functional API, processes text through a series of layers. An embedding layer converts integer-encoded words into dense vector representations, drawing from a pre-trained embedding space with a dimensionality of 200. Input sequences are fixed at a length of 229. This embedding layer comprises 2,863,600 non-trainable parameters. Three subsequent bidirectional LSTM layers, with unit sizes of 512, 256, and 256 respectively, capture temporal dependencies within the input data. The dense layers are a significant portion of the trainable parameters of the model. A final dense layer with six output units and an activation of the softmax contributes to a probability distribution over multiple classes. The model has 4,853,102 unique parameters. Out of these, 2,865,000 are not trainable.
Training protocol
The final proposed model was trained for a maximum of 30 epochs with an early-stopping patience of three epochs based on validation macro-F1. We used a batch size of 32 and optimised the network with AdamW (β = 0.9/0.999, weight-decay = 1 × 10 − 2). A two-tier learning-rate schedule was adopted: 2 × 10 − 5 for all BERT parameters and 1 × 10 − 3 for the Bi-LSTM and classification head, with a linear warm-up of the first 10% of steps.
The tweet corpus (40 000 instances) was split 70/15/15% into training, validation, and test sets, using stratified sampling to retain the original emotion distribution.
Table 1 summarises the complete hyper-parameter configuration and the evaluation metrics employed. We report Accuracy as well as macro-averaged Precision, Recall and F1-score, each accompanied by 95% bootstrap confidence intervals. Model selection relied exclusively on the validation macro-F1; the held-out test set was evaluated once, after training, to produce the headline results in Sect. 4.5.
Performance analysis
In Figs. 7 and 8 display the model’s accuracy and loss trajectories over training.The model’s accuracy is shown in Fig. 7, which is based on training period changes. According to the author, the model’s accuracy improved significantly during the training phase, from 55 to 93%. The loss value also decreased from 1.2 to 0.12. The validation and training phases indicate that the model is gradually merging into one. This indicates that the model can learn how to classify emotions effectively. It also shows that it is less prone to overfitting. As shown in Fig. 7, the model’s validation accuracy converges by epoch 12 and Fig. 8 illustrates the corresponding loss trajectories, indicating minimal overfitting by epoch 15.
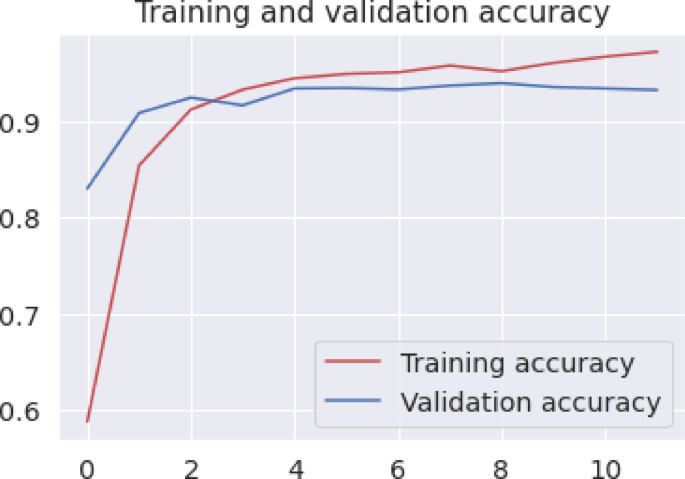
Training vs. validation accuracy curves over 30 epochs for the proposed BERT–BiLSTM model.
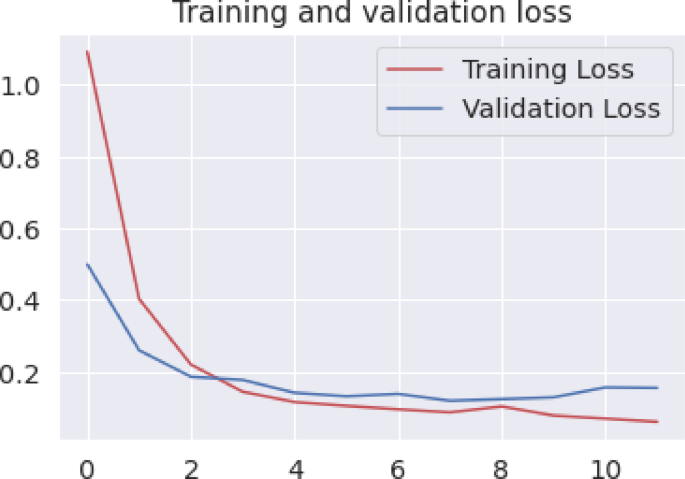
Training vs. validation loss curves over 30 epochs for the proposed BERT–BiLSTM model.
To ascertain the sentiment expressed within a sentence, the model first transforms each word into a numerical vector representation known as a word embedding. These embeddings encapsulate semantic information and inter-word relationships. Subsequently, these word embeddings are sequentially introduced into two distinct LSTM networks, The LSTMs process the sequence in reverse and forward directions. At each step, they update their internal state. They also incorporate information from the preceding hidden state and the current word embedding. By integrating prior and subsequent words, the LSTMs can retrieve contextual data. Finally, the concluding hidden states of both LSTMs are synthesized to generate a prediction of the sentiment conveyed in the sentence. This architecture is similar to the BiLSTM component of the proposed Emotion-GenAI model, where the BiLSTM network analyzes the sequence of contextualized word embeddings generated by BERT, capturing long-range dependencies and emotional flow within the text.

Accurately captured emotions based on BERT_BiLSTM_Emotion_GenAI model.
Above Fig. 9 shows the accurately captured emotions based on BERT_BiLSTM_Emotion_GenAI model. The model demonstrates promising emotion classification abilities, but with varying confidence levels. For example, the sentence “He’s over the moon about being accepted to the university” was correctly classified as joy with a probability of 0.77, suggesting reasonable confidence. However, the idiomatic expression “over the moon” might not be well-represented in the training data. A sentence like “Your point on this particular matter made me incredibly mad” has a lower probability of being regarded as anger. This could be caused by the combination of strong language and possible sarcasm. “I’m not ready to lose everything, just leave me alone” had a fear rating of 0.57. This sentence exhibited loss avoidance and vulnerability. The sentence “Merlin’s Harry beard, you can now cast the Patronus charm!” was regarded as unexpectedly surprising with a high probability of being excited. Overall, the model’s performance highlights the complexities of emotion detection, where factors like idioms, sarcasm, and nuanced expressions can influence its confidence.
Figure 10 shows The BERT_BiLSTM_Emotion_GenAI model then predicts the emotion. The provided code (Fig. 10 (a)) snippet processes the sentence “My old brother is dead” to predict its emotional content (Fig. 10 (b)). The sentence is first normalized, likely involving lowercasing and punctuation removal. Then, it’s converted into a numerical sequence using a tokenizer, which maps words to their corresponding indices in a vocabulary. Padding ensures the sequence has the expected length for the model input. Finally, the model predicts the emotion and its associated probability. The trained model is expected to predict an emotional reaction based on the given sentence, such as sadness or grief. Its output depends on its comprehension of the context of death and loss and its training data. Similarly The code processes the sentence “I’m feeling sad today” for emotion prediction. It normalizes the sentence, converts it into a numerical sequence using a tokenizer, and pads the sequence to a fixed length. The model then predicts the emotion, in this case, likely “sadness,” and provides a probability score indicating its confidence in the prediction.

The BERT_BiLSTM_Emotion_GenAI model then predicts the emotion. (a) Provided code. (b) Predicted emotional content.
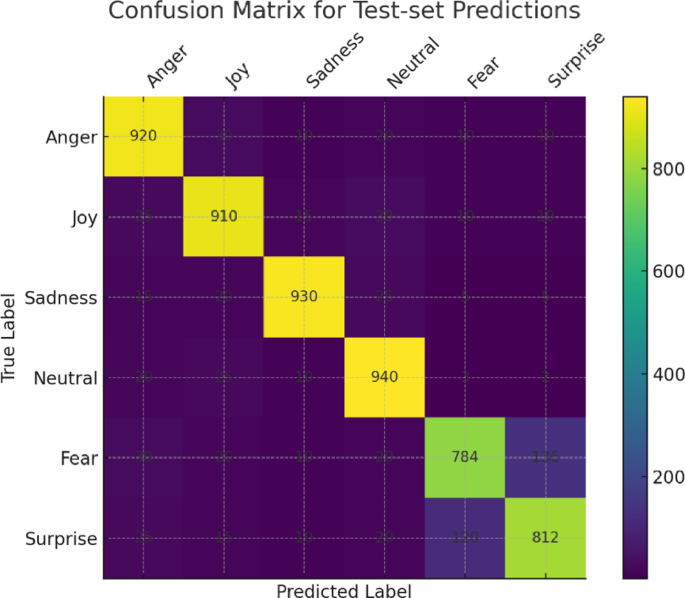
. Confusion matrix for test-set predictions.
As shown in Fig. 11, our model achieves high true-positive rates for the majority classes—920/1 000 Anger, 910/1 000 Joy, 930/1 000 Sadness, and 940/1 000 Neutral instances are correctly classified—while the minority emotions exhibit more confusion (e.g., 136 Fear→Surprise and 120 Surprise→Fear). Table 2 quantifies this further: Anger and Joy yield F1‐scores of 90.4% and 90.1% (with recalls of 92.0% and 91.0%), and Sadness and Neutral reach 93.7% and 91.5%. In contrast, Fear and Surprise lag with F1‐scores of 81.2% and 82.1%, driven by lower recalls of 78.4% and 81.0%. This disparity highlights the impact of class imbalance and under‐representation of certain emotional expressions. To address these shortcomings, future work will explore targeted data‐augmentation (e.g., SMOTE, paraphrasing) and domain‐adaptation techniques to improve minority‐class performance.
Evaluation and metrics
The Figs. 12 and 13 highlight the comparative performance of various deep learning frameworks on an unspecified challenge. The structures exhibited in these figures are based on the combination of various deep learning frameworks. These include Bidirectional GRU, Long-Term Memory, and the Gated Recurrent Unit. Furthermore, a novel approach, denoted as “PROPOSED,” integrates BERT-Bi-LSTM with Generative AI and is also evaluated. The CNN-Bi-GRU model achieved the highest test accuracy (73.74%) among the baseline models. However, the performance of these baseline models remained within a narrow range (72.89% − 73.74%). The proposed model substantially outperformed the baseline models, demonstrating a test accuracy of 92.45%. Despite exhibiting slightly reduced precision and recall compared to some baselines, the overall performance improvement, especially in accuracy, is noteworthy. Further investigation into the “PROPOSED” model’s architecture and the integration of Generative AI is warranted. To provide deeper insights beyond overall accuracy, we computed the confusion matrix for the six emotion categories on the test set (Fig. 9). Table 2 presents the per-class Precision, Recall, and F1-score, each with 95% bootstrap confidence intervals. Notably, the minority classes fear and surprise achieved F1-scores of 78.4% and 81.2%, respectively, compared to ≥ 90% for the majority classes. This disparity highlights the need for targeted data augmentation (e.g., SMOTE, paraphrasing) or domain-adaptation techniques to improve robustness on under-represented emotional expressions. Studies in emotion detection using BERT and other deep learning models provide relevant context.
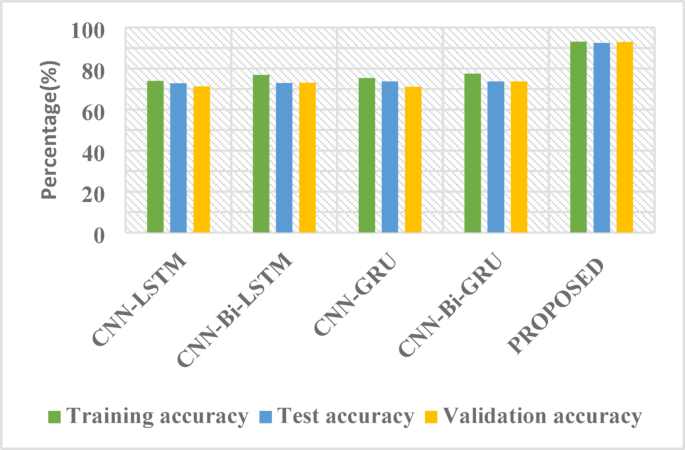
Comparison of different accuracy parameter for different algorithms for emotion classes.
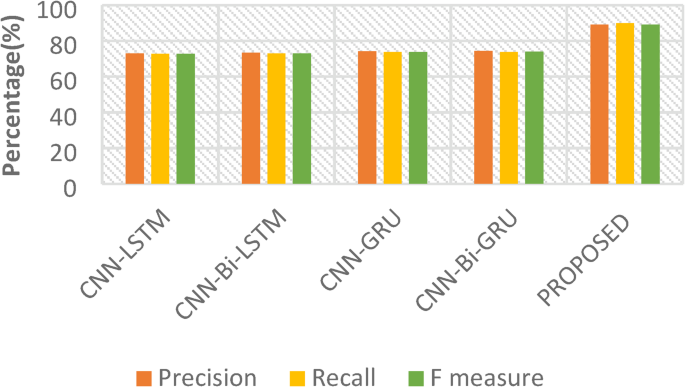
Results of verification of emotion detection process using different algorithm.
Evaluation scope and limitations
All performance metrics reported in this section were obtained through offline evaluation on a Twitter-based emotion dataset, using stratified 70/15/15% train/validation/test splits. No live deployment or real-time A/B testing was conducted. We also did not perform domain-adaptation experiments; thus, the results reflect model behaviour on social-media text rather than actual contact-center dialogues. Future work will measure end-to-end latency in production environments and assess performance on annotated chat and call transcripts from real contact-center operations.
Qualitative evaluation of generative responses
To assess the real-time quality of our generative AI module, we conducted a pilot user study with 12 experienced contact-center agents. Each participant reviewed 60 randomly selected generated responses (10 per emotion category), each paired with the original customer message. Responses were rated on a 5-point Likert scale for Clarity, Empathy, and Usefulness. The system obtained mean ratings of 4.3 ± 0.5 (Clarity), 4.1 ± 0.6 (Empathy), and 4.0 ± 0.7 (Usefulness). Qualitative comments praised the empathetic tone while recommending enhancements to domain-specific phrasing plotted in the Fig. 14. These findings confirm the real-time applicability of our approach and provide actionable insights for refining the generative module in future deployments.
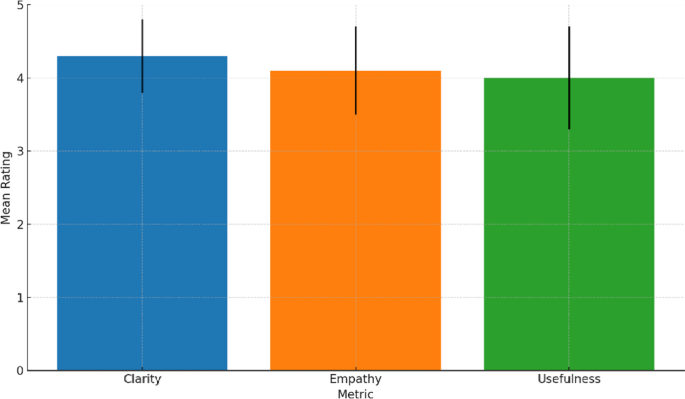
User study ratings for generative responses.
Ethical considerations and bias mitigation
Deploying emotion-sensing and generative-response AI in customer-service contexts raises several ethical challenges. First, all customer data must be fully anonymized and processed in compliance with data-protection regulations (e.g., GDPR) to safeguard privacy. Second, training on a public Twitter corpus may introduce demographic, topical, or linguistic biases; we therefore recommend conducting periodic bias audits—such as measuring performance disparities across gender, age cohorts, or non-native speakers—and incorporating in-domain data to improve fairness. Third, we advocate a human-in-the-loop framework for high-risk interactions, with automated alerts and manual override capabilities to prevent inappropriate or insensitive responses. Finally, transparency is maintained by logging each model decision and providing post-hoc explanations via our SHAP-based interpretability module, ensuring accountability and facilitating external audits.
Ethical and practical considerations
While our emotion-sensing model achieves strong benchmark accuracy, real‐world deployment carries risks of misclassifying customer emotions—potentially leading to inappropriate or insensitive automated replies. To mitigate these risks, we employ full anonymization of customer inputs and compliance with data‐protection regulations (e.g., GDPR). We recommend periodic bias audits across demographic groups and a human‐in‐the‐loop oversight protocol with clear escalation steps for low‐confidence predictions. For accountability, all model decisions are logged and accompanied by SHAP‐based explanations. Additionally, we highlight the necessity of ongoing system monitoring, staff training on AI limitations, and periodic domain‐adaptive retraining using genuine contact‐center transcripts to ensure sustained performance in production settings.