
OpenAI’s o3-mini model, now available within the free tier of ChatGPT, is a compact, yet powerful AI model designed to excel in advanced reasoning, coding proficiency, and mathematical problem-solving, scoring 96.7% on the American Invitational Mathematics Examination (AIME), surpassing its predecessor, o1.
DeepSeek, the popular Chinese chatbot has proven to be particularly strong in mathematical reasoning and coding tasks, effectively solving complex problems and generating code snippets. With superior multilingual capabilities and high inference efficiency, the model has shown versatility in a wide range of applications. Two models, R1 and V3 offer similar answers, yet R1 has the ability to “think” through the answers, offering increased reasoning for more detailed responses.
Yet, since Alibaba’s Qwen 2.5 launched, it has been a top competitor of both DeepSeek and ChatGPT. Also free for users and also excelling at coding proficiency, multilingual understanding, mathematical reasoning, and extended content processing with efficiency and speed, this chatbot is proving to hold its own within the competitive AI space.
So how do these chatbots compare? I put them through a series of the same prompts to test them on everything from advanced reasoning and coding proficiency to problem-solving capabilities. Here’s what happened when these free tier models faced off, including the overall winner.
1. Lateral thinking puzzle

Prompt: “You are in a completely dark room with three light switches on a wall. Each switch controls one of three light bulbs in another room, but you cannot see the bulbs from where you are. You can flip the switches as many times as you want, but you can only enter the bulb room once to check the bulbs. How do you determine which switch controls which bulb?”
o3-mini clearly explains why each bulb state corresponds to a specific switch while using natural, conversational language, making the explanation accessible with easy-to-follow steps.
Qwen 2.5 included an extra layer of clarity by explicitly labeling the switches and numbering the steps, making the explanation easier to follow with strong logical reasoning.
You may like
DeepSeek correctly identifies the key insight with a concise and straight to the point explanation.
Winner: Qwen 2.5 wins for its structured response because it is the easiest to follow. o3-mini comes in second for the thorough explanation, but less structured than Qwen 2.5.
2. Deductive reasoning

Prompt: “A detective is investigating a murder case. He interviews three suspects: Alice, Bob, and Charlie. One of them is guilty, and the other two are telling the truth. Here’s what they say
Alice: “Bob is innocent.”
Bob: “Charlie is guilty.”
Charlie: “I am innocent.”
Who is the murderer?”
o3-mini delivered a step-by-step elimination approach: the model systematically assumes each person is guilty and checks for contradictions. The explanation is clear, logical, and doesn’t overcomplicate.
Qwen 2.5 offers a very structured and logical explanation with well-marked steps, ensuring no contradiction remains in the final conclusion.
DeepSeek offered detailed reasoning and checks for contradictions effectively while explicitly stating why Alice and Bob cannot be guilty. The model maintains logical consistency throughout.
Winner: o3-mini wins for being the most structured and methodical, making it easier for a reader to follow. Qwen 2.5 was a close second.
3. Coding challenge

Prompt: “Write a Python script that simulates a basic banking system with functionalities to deposit, withdraw, and check balance.”
o3-mini Provided a solid implementation using a class-based approach and included meaningful error messages while ensuring proper handling of deposits and withdrawals. It also offers a clear explanation of each method and its functionality.
Qwen 2.5 offered a well-structured breakdown of how the script works, covering class definition, deposit/withdraw methods, error handling, and user experience. It includes try-except blocks to handle invalid inputs, making it more robust. The script is clean and well-commented, making it easy for beginners to understand.
DeepSeek kept the script structured and efficient and introduces an owner name for the account, adding a personal touch. Yet, while the explanation is clear, it is not as detailed as Qwen 2.5.
Winner: Qwen 2.5 wins for providing a clean, well-structured script with strong error handling, detailed explanations, and intuitive user experience. With a good implementation but slightly less comprehensive with error handling, o3-mini was a close second.
4. Mathematical proof
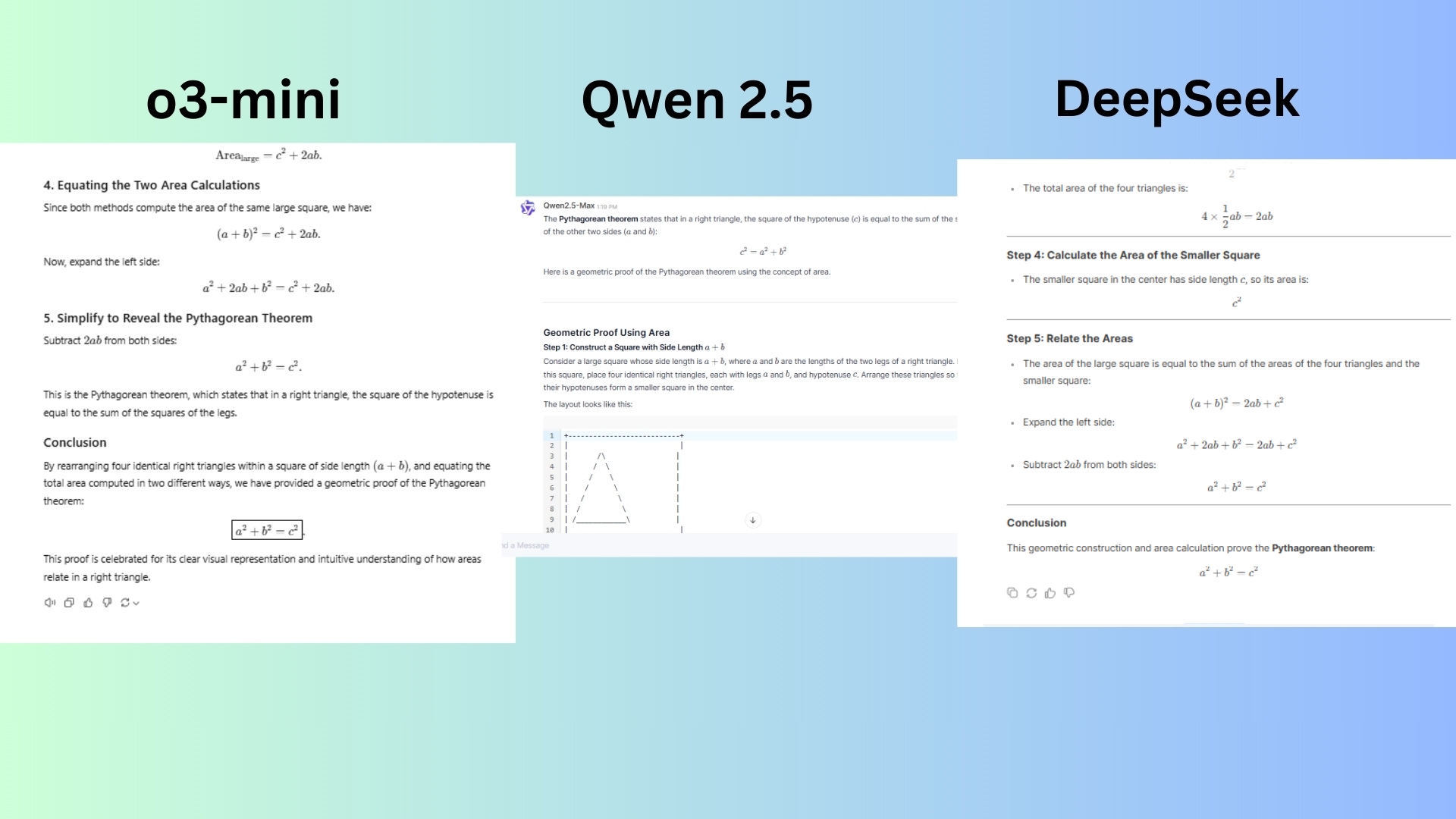
Prompt: “Prove the Pythagorean theorem using a geometric approach.”
o3-mini delivered an explanation that follows a well-structured, step-by-step approach, making it easy to understand. The explanation is neither overly verbose nor lacking in necessary details.
Qwen 2.5 offered a similar approach to o3-mini, using the large square and rearranging triangles while breaking down the steps clearly and methodically. The explanation contains formatting issues and some parts, like the ASCII diagram, are slightly unclear or misaligned, making it harder to visualize.
DeepSeek crafted a correct proof that follows a logical structure. Yet it lacks the conversational approach response of 03-mini or Qwen 2.5.
Winner: o3-mini wins for the best combination of clarity, detail and logical flow. Qwen 2.5 is in second place with a solid response but formatting and visualization issues.
5. Scientific explanation

Prompt: “Explain the process of photosynthesis in detail.”
o3-mini provided detailed descriptions of both light-dependent and light-independent reactions with clear breakdowns of each step. The step-by-step progression from capturing light to converting energy into glucose is easy to follow. It breaks down complex processes into digestible segments.
Qwen 2.5 provided all the key concepts in photosynthesis with a good step-by-step breakdown of the light-dependent reactions and the Calvin cycle. However, the chatbot placed less emphasis on real-word significance such as climate change, food security and the response feels overly condensed compared to o3-mini’s thorough explanation.
DeepSeek covered both stages of photosynthesis well and included factors affecting photosynthesis (e.g., light intensity, CO₂ levels, water availability) but lacked minor details in comparison to the o3-mini’s response.
Winner: o3-mini wins for best balance of depth, clarity, organization, and accuracy. DeepSeek was a close second for its solid explanation but lacking some finer details.
6. Historical analysis

Prompt: “Analyze the causes and effects of the French Revolution.”
o3-mini crafted a comprehensive and well-structured analysis clearly dividing the causes and effects into distinct sections and provided in-depth explanations for each factor, rather than just listing them.
Qwen 2.5 discussed global impact, including Napoleon and later revolutions within its strong explanation and well-organized response. However, the economic consequences could have been explored in more detail.
DeepSeek covered key causes well, including social inequality, economic struggles, and Enlightenment ideas, but did not reference sources.
Winner: o3-mini wins for the best balance of depth, clarity, organization, and historical analysis. DeepSeek comes in second place for a solid response but slightly less detailed.
7. Literary critique

Prompt: “Provide a critical analysis of Shakespeare’s ‘Hamlet’ focusing on its themes of madness and revenge.”
o3-mini explored both themes of madness and revenge and how they intertwine rather than treating them as separate topics. It explored Hamlet’s psychological struggle, examining whether his madness is feigned or real, which is a central debate in Shakespearean scholarship.
Qwen 2.5 offered a very detailed discussion of feigned vs. real madness. Yet, there was some redundancy in explaining revenge, which felt more descriptive than analytical.
DeepSeek provided a solid comparison between Hamlet, Laertes, and Fortinbras in their approach to revenge, but the response felt like a well-structured summary rather than a deep analysis. The list-like structure made it feel less like a flowing critical argument.
Winner: o3-mini wins again for the best blend of depth, structure, and thematic connection. DeepSeek is second for a strong response, but it was more summary-like and less interwoven.
8. Philosophical discussion

Prompt: “Discuss the concept of utilitarianism and its implications in modern ethics.”
o3-mini clearly outlined the core principles of utilitarianism (consequentialism, hedonistic calculus, impartiality) and discussed their modern applications (policy-making, healthcare, environmental ethics) in greater detail than the other responses.
Qwen 2.5 delivered a solid breakdown of act vs. rule utilitarianism and covered business ethics, technology, AI, and medical ethics well. But there was some redundancy and over-explanation in defining utilitarian concepts.
DeepSeek covered the core principles well and includes historical context but it failed at exploring critiques as deeply as the other two agents. Additionally, the response lacked a strong thematic connection between theory and real-world issues.
Winner: o3-mini delivered the best in-depth response with clarity and connection to modern ethical issues. Qwen 2.5 is in second place for a good explanation but slightly weaker structure and conclusion.
9. Urban planning

Prompt: “Design an integrated strategy to optimize urban transportation in a rapidly growing megacity. Your plan should address the following aspects.”
o3-mini covered all major aspects required to optimize urban transportation with smart references and strong logical flow with clear implementation steps.
Qwen 2.5 delivered a well-structured response and covered most essential components with a good use of data-driven decision-making. However it lacked a strong global case study and did not emphasize implementation phases.
DeepSeek included in-depth transport electrification plans and had a solid focus on equity and gender safety in transit. However, the chatbot lacked a strong focus on governance and long-term futureproofing. It also is missing a well-defined policy execution framework from its response.
Winner: o3-mini wins for its execution roadmap, innovation, depth, and realism. Qwen 2.5 came in second for a strong but slightly-less structured response.
Overall winner: o3-mini
ChatGPT’s o3-mini emerged as the most well-rounded and consistently high-performing chatbot in this chatbot face-off. Across a diverse range of challenges — including coding, mathematics, historical analysis, literary critique, philosophical discussions, and problem solving — o3-mini repeatedly demonstrated superior depth, clarity, organization, and real-world applicability.
03 mini excelled in balancing detail with readability, offering well-structured and insightful responses that blended theoretical understanding with practical implications.
While DeepSeek and Qwen 2.5 had their strengths, neither could match o3-mini’s versatility across all tested domains.
Notably, Qwen 2.5 edged out o3-mini in the coding challenge due to its well-commented script and error-handling capabilities, and DeepSeek occasionally placed second when it provided a more comprehensive but less nuanced response.
Consistently ranking first in five out of the seven challenges, o3-mini proved to be the most balanced AI model for users seeking thoughtful, well-articulated, and logically sound answers. While all three models provide valuable assistance in various tasks, o3-mini currently offers the most polished and reliable experience among these free-tier chatbot options.
More from Tom’s Guide
Back to MacBook Air