
This post is cowritten with Thomas Voss and Bernhard Hersberger from Hapag-Lloyd.
Hapag-Lloyd is one of the world’s leading shipping companies with more than 308 modern vessels, 11.9 million TEUs (twenty-foot equivalent units) transported per year, and 16,700 motivated employees in more than 400 offices in 139 countries. They connect continents, businesses, and people through reliable container transportation services on the major trade routes across the globe.
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.
For Hapag-Lloyd, accurate vessel schedule predictions are crucial for maintaining schedule reliability, where schedule reliability is defined as percentage of vessels arriving within 1 calendar day (earlier or later) of their estimated arrival time, communicated around 3 to 4 weeks before arrival.
Prior to developing the new ML solution, Hapag-Lloyd relied on simple rule-based and statistical calculations, based on historical transit patterns for vessel schedule predictions. While this statistical method provided basic predictions, it couldn’t effectively account for real-time conditions such as port congestion, requiring significant manual intervention from operations teams.
Developing a new ML solution to replace the existing system presented several key challenges:
Dynamic shipping conditions – The estimated time of arrival (ETA) prediction model needs to account for numerous variables that affect journey duration, including weather conditions, port-related delays such as congestion, labor strikes, and unexpected events that force route changes. For example, when the Suez Canal was blocked by the Ever Given container ship in March 2021, vessels had to be rerouted around Africa, adding approximately 10 days to their journey times.
Data integration at scale – The development of accurate models requires integration of large volumes of historical voyage data with external real-time data sources including port congestion information and vessel position tracking (AIS). The solution needs to scale across 120 vessel services or lines and 1,200 unique port-to-port routes.
Robust MLOps infrastructure – A robust MLOps infrastructure is required to continuously monitor model performance and quickly deploy updates whenever needed. This includes capabilities for regular model retraining to adapt to changing patterns, comprehensive performance monitoring, and maintaining real-time inference capabilities for immediate schedule adjustments.
Hapag-Llyod’s previous approach to schedule planning couldn’t effectively address these challenges. A comprehensive solution that could handle both the complexity of vessel schedule prediction and provide the infrastructure needed to sustain ML operations at global scale was needed.
The Hapag-Lloyd network consists of over 308 vessels and many more partner vessels that continuously circumnavigate the globe on predefined service routes, resulting in more than 3,500 port arrivals per month. Each vessel operates on a fixed service line, making regular round trips between a sequence of ports. For instance, a vessel might repeatedly sail a route from Southampton to Le Havre, Rotterdam, Hamburg, New York, and Philadelphia before starting the cycle again. For each port arrival, an ETA must be provided multiple weeks in advance to arrange critical logistics, including berth windows at ports and onward transportation of containers by sea, land or air transport. The following table shows an example where a vessel travels from Southampton to New York through Le Havre, Rotterdam, and Hamburg. The vessel’s time until arrival at the New York port can be calculated as the sum of ocean to port time to Southampton, and the respective berth times and port-to-port times for the intermediate ports called while sailing to New York. If this vessel encounters a delay in Rotterdam, it affects its arrival in Hamburg and cascades through the entire schedule, impacting arrivals in New York and beyond as shown in the following table. This ripple effect can disrupt carefully planned transshipment connections and require extensive replanning of downstream operations.
Port
Terminal call
Scheduled arrival
Scheduled departure
SOUTHAMPTON
1
2025-07-29 07:00
2025-07-29 21:00
LE HAVRE
2
2025-07-30 16:00
2025-07-31 16:00
ROTTERDAM
3
2025-08-03 18:00
2025-08-05 03:00
HAMBURG
4
2025-08-07 07:00
2025-08-08 07:00
NEW YORK
5
2025-08-18 13:00
2025-08-21 13:00
PHILADELPHIA
6
2025-08-22 06:00
2025-08-24 16:30
SOUTHAMPTON
7
2025-09-01 08:00
2025-09-02 20:00
When a vessel departs Rotterdam with a delay, new ETAs must be calculated for the remaining ports. For Hamburg, we only need to estimate the remaining sailing time from the vessel’s current position. However, for subsequent ports like New York, the prediction requires multiple components: the remaining sailing time to Hamburg, the duration of port operations in Hamburg, and the sailing time from Hamburg to New York.
Solution overview
As an input to the vessel ETA prediction, we process the following two data sources:
Hapag-Lloyd’s internal data, which is stored in a data lake. This includes detailed vessel schedules and routes, port and terminal performance information, real-time port congestion and waiting times, and vessel characteristics datasets. This data is prepared for model training using AWS Glue jobs.
Automatic Identification System (AIS) data, which provides streaming updates on the vessel movements. This AIS data ingestion is batched every 20 minutes using AWS Lambda and includes crucial information such as latitude, longitude, speed, and direction of vessels. New batches are processed using AWS Glue and Iceberg to update the existing AIS database—currently holding around 35 million observations.
These data sources are combined to create training datasets for the ML models. We carefully consider the timing of available data through temporal splitting to avoid data leakage. Data leakage occurs when using information that wouldn’t be available at prediction time in the real world. For example, when training a model to predict arrival time in Hamburg for a vessel currently in Rotterdam, we can’t use actual transit times that were only known after the vessel reached Hamburg.
A vessel’s journey can be divided into different legs, which led us to develop a multi-step solution using specialized ML models for each leg, which are orchestrated as hierarchical models to retrieve the overall ETA:
The Ocean to Port (O2P) model predicts the time needed for a vessel to reach its next port from its current position at sea. The model uses features such as remaining distance to destination, vessel speed, journey progress metrics, port congestion data, and historical sea leg durations.
The Port to Port (P2P) model forecasts sailing time between any two ports for a given date, considering key features such as ocean distance between ports, recent transit time trends, weather, and seasonal patterns.
The Berth Time model estimates how long a vessel will spend at port. The model uses vessel characteristics (such as tonnage and load capacity), planned container load, and historical port performance.
The Combined model takes as input the predictions from the O2P, P2P, and Berth Time models, along with the original schedule. Rather than predicting absolute arrival times, it computes the expected deviation from the original schedule by learning patterns in historical prediction accuracy and specific voyage conditions. These computed deviations are then used to update ETAs for the upcoming ports in a vessel’s schedule.
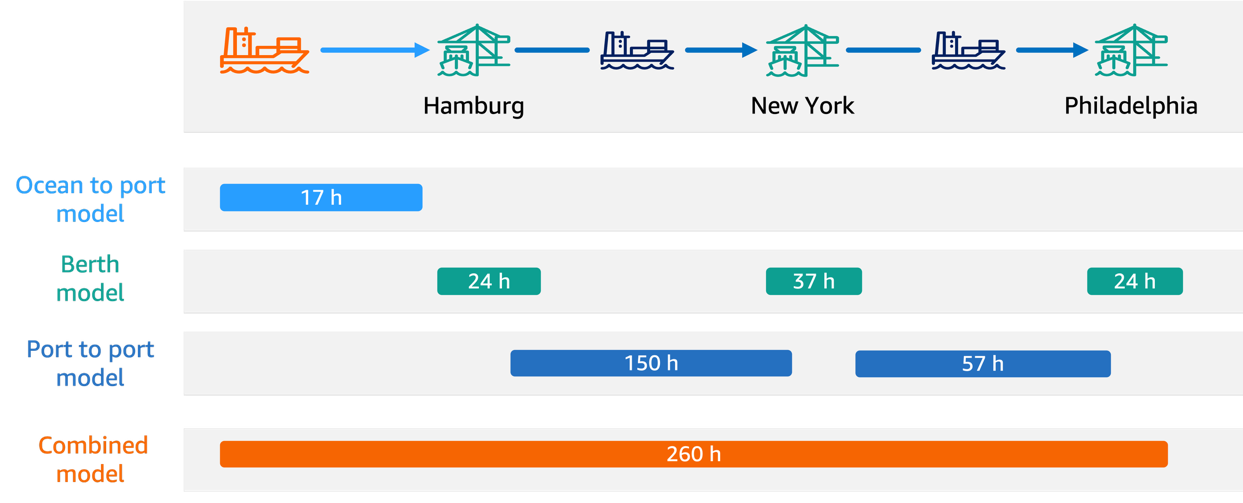
All four models are trained using the XGBoost algorithm built into SageMaker, chosen for its ability to handle complex relationships in tabular data and its robust performance with mixed numerical and categorical features. Each model has a dedicated training pipeline in SageMaker Pipelines, handling data preprocessing steps and model training. The following diagram shows the data processing pipeline, which generates the input datasets for ML training.
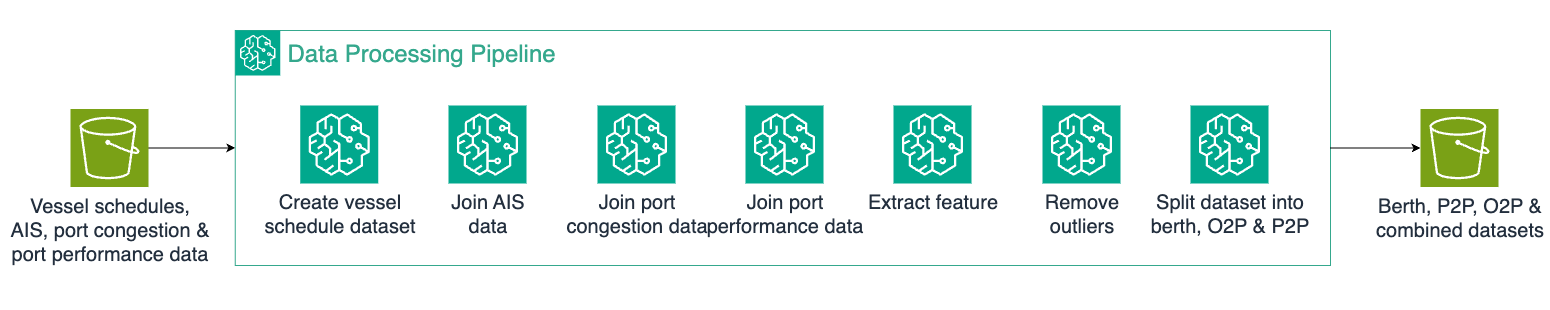
As an example, this diagram shows the training pipeline of the Berth model. The steps in the SageMaker training pipelines of the Berth, P2P, O2P, and Combined models are identical. Therefore, the training pipeline is implemented once as a blueprint and re-used across the other models, enabling a fast turn-around time of the implementation.
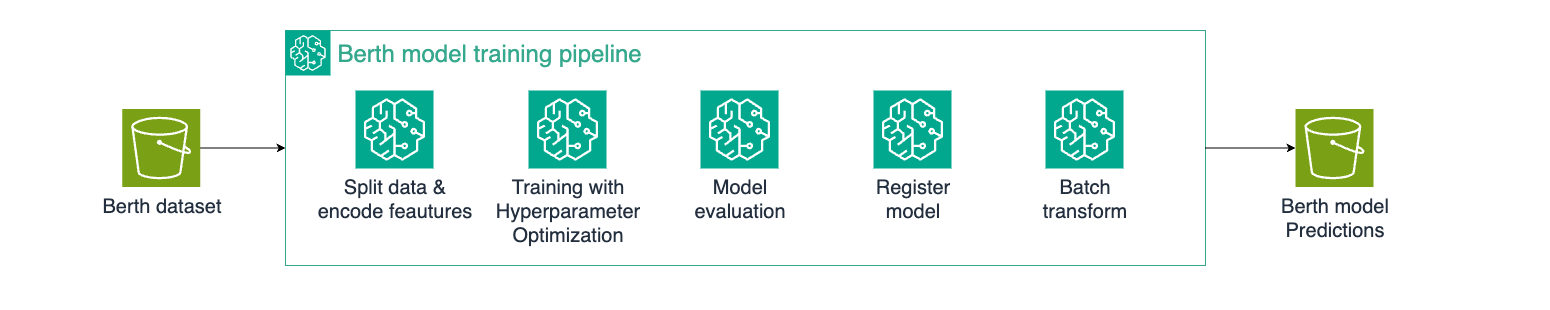
Because the Combined model depends on outputs from the other three specialized models, we use AWS Step Functions to orchestrate the SageMaker pipelines for training. This helps ensure that the individual models are updated in the correct sequence and maintains prediction consistency across the system. The orchestration of the training pipelines is shown in the following pipeline architecture.
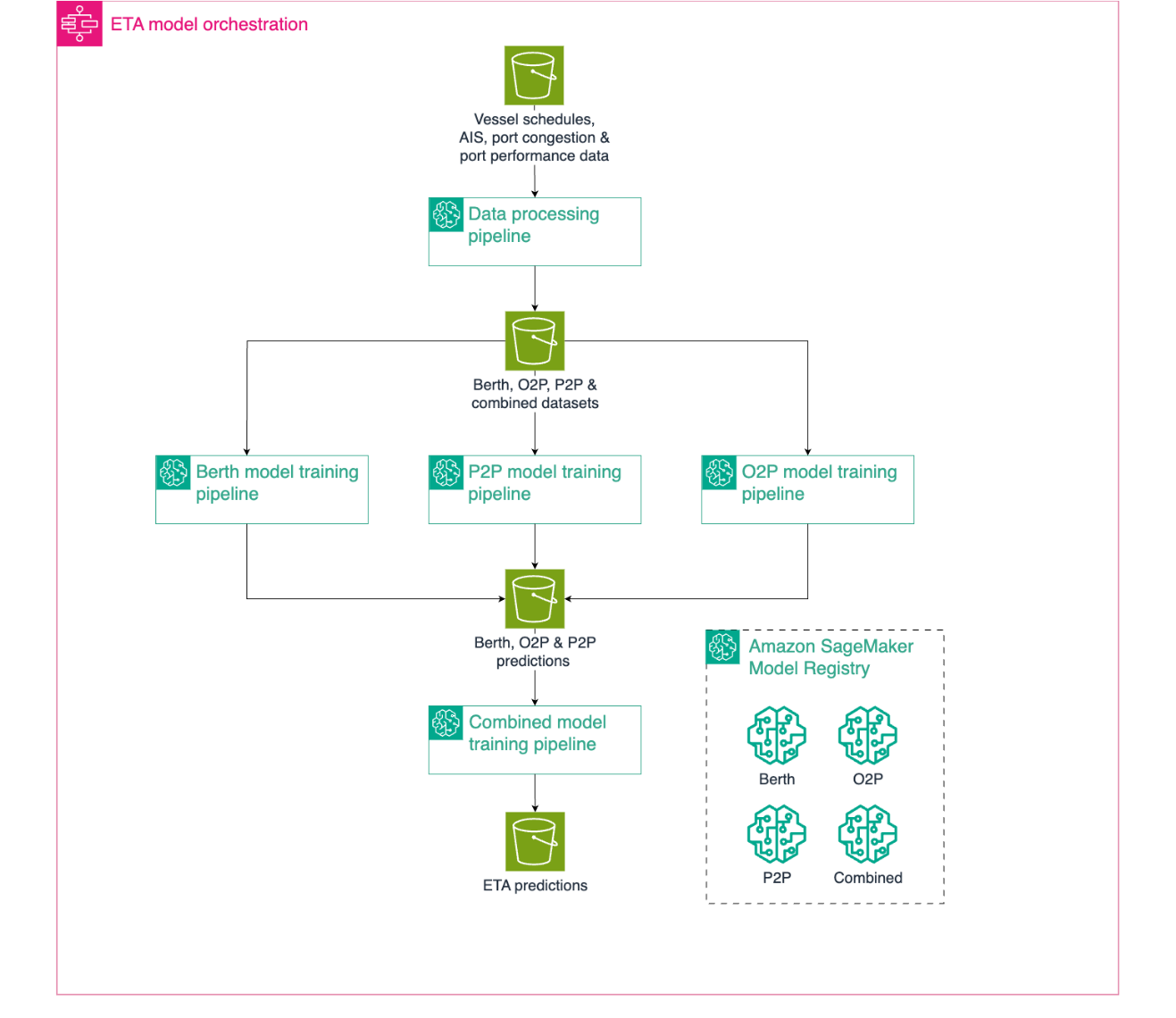
The individual workflow begins with a data processing pipeline that prepares the input data (vessel schedules, AIS data, port congestion, and port performance metrics) and splits it into dedicated datasets. This feeds into three parallel SageMaker training pipelines for our base models (O2P, P2P, and Berth), each following a standardized process of feature encoding, hyperparameter optimization, model evaluation, and registration using SageMaker Processing and hyperparameter turning jobs and SageMaker Model Registry. After training, each base model runs a SageMaker batch transform job to generate predictions that serve as input features for the combined model training. The performance of the latest Combined model version is tested on the last 3 months of data with known ETAs, and performance metrics (R², mean absolute error (MAE)) are computed. If the model’s performance is below a set MAE threshold, the entire training process fails and the model version is automatically discarded, preventing the deployment of models that don’t meet the minimum performance threshold.
All four models are versioned and stored as separate model package groups in the SageMaker Model Registry, enabling systematic version control and deployment. This orchestrated approach helps ensure that our models are trained in the correct sequence using parallel processing, resulting in an efficient and maintainable training process.The hierarchical model approach helps further ensure that a degree of explainability comparable to the current statistical and rule-based solution is maintained—avoiding ML black box behavior. For example, it becomes possible to highlight unusually long berthing time predictions when discussing predictions results with business experts. This helps increase transparency and build trust, which in turn increases acceptance within the company.
Inference solution walkthrough
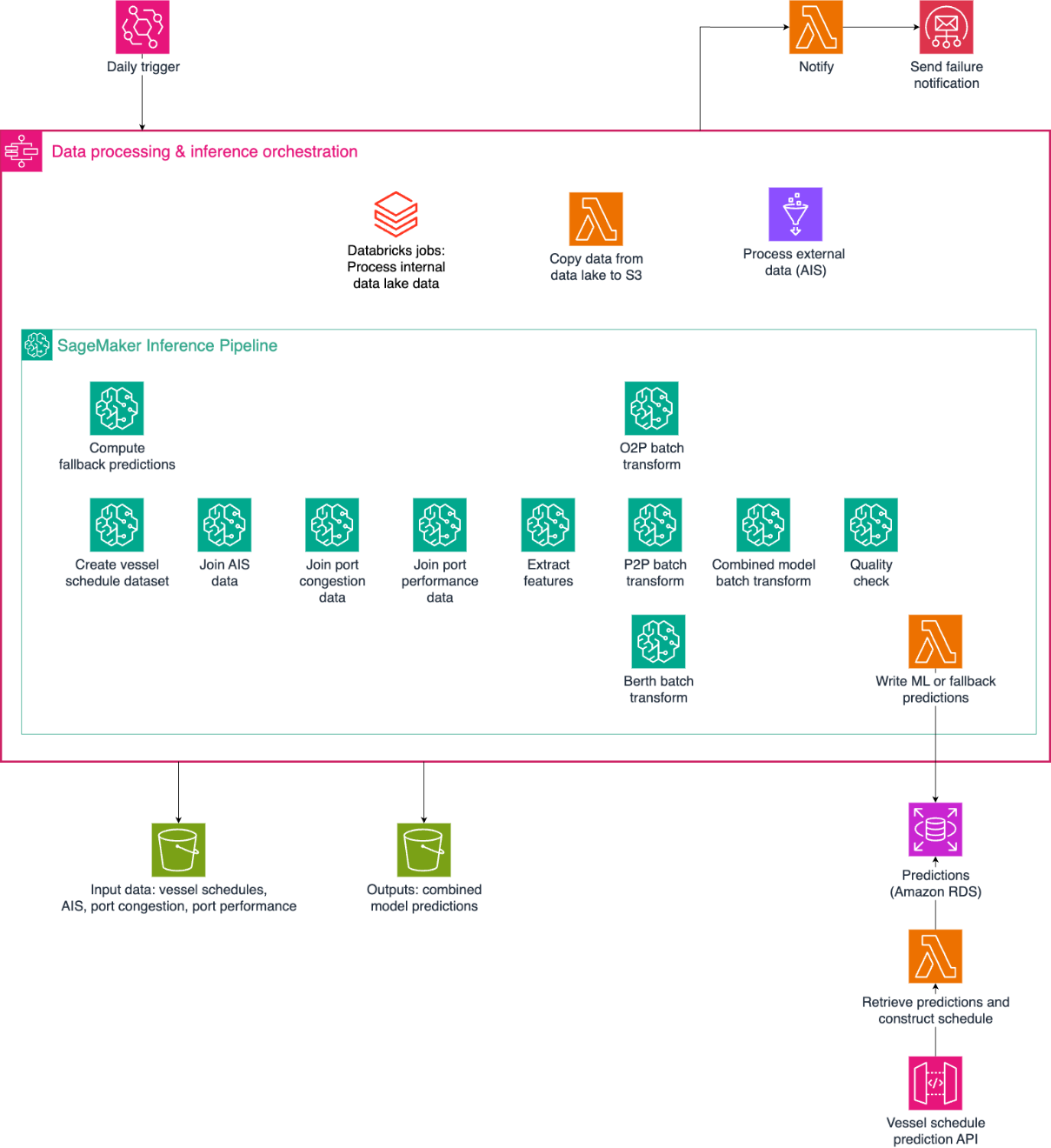
The inference infrastructure implements a hybrid approach combining batch processing with real-time API capabilities as shown in Figure 5. Because most data sources update daily and require extensive preprocessing, the core predictions are generated through nightly batch inference runs. These pre-computed predictions are complemented by a real-time API that implements business logic for schedule changes and ETA updates.
Daily batch Inference:
Amazon EventBridge triggers a Step Functions workflow every day.
The Step Functions workflow orchestrates the data and inference process:
Lambda copies internal Hapag-Lloyd data from the data lake to Amazon Simple Storage Service (Amazon S3).
AWS Glue jobs combine the different data sources and prepare inference inputs
SageMaker inference executes in sequence:
Fallback predictions are computed from historical averages and written to Amazon Relational Database Service (Amazon RDS). Fallback predictions are used in case of missing data or a downstream inference failure.
Preprocessing data for the four specialized ML models.
O2P, P2P, and Berth model batch transforms.
The Combined model batch transform generates final ETA predictions, which are written to Amazon RDS.
Input features and output files are stored in Amazon S3 for analytics and monitoring.
For operational reliability, any failures in the inference pipeline trigger immediate email notifications to the on-call operations team through Amazon Simple Email Service (Amazon SES).
Real-time API:
Amazon API Gateway receives client requests containing the current schedule and an indication for which vessel-port combinations an ETA update is required. By receiving the current schedule through the client request, we can take care of intraday schedule updates while doing daily batch transform updates.
The API Gateway triggers a Lambda function calculating the response. The Lambda function constructs the response by linking the ETA predictions (stored in Amazon RDS) with the current schedule using custom business logic, so that we can take care of short-term schedule changes unknown at inference time. Typical examples of short-term schedule changes are port omissions (for example, due to port congestion) and one-time port calls.
This architecture enables millisecond response times to custom requests while achieving a 99.5% availability (a maximum 3.5 hours downtime per month).
Conclusion
Hapag Lloyd’s ML powered vessel scheduling assistant outperforms the current solution in both accuracy and response time. Typical API response times are in the order of hundreds of milliseconds, helping to ensure a real-time user experience and outperforming the current solution by more than 80%. Low response times are crucial because, in addition to fully automated schedule updates, business experts require low response times to work with the schedule assistant interactively. In terms of accuracy, the MAE of the ML-powered ETA predictions outperform the current solution by approximately 12%, which translates into climbing by two positions in the international ranking of schedule reliability on average. This is one of the key performance metrics in liner shipping, and this is a significant improvement within the industry.
To learn more about architecting and governing ML workloads at scale on AWS, see the AWS blog post Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker and the accompanying AWS workshop AWS Multi-Account Data & ML Governance Workshop.
Acknowledgement
We acknowledge the significant and valuable work of Michal Papaj and Piotr Zielinski from Hapag-Lloyd in the data science and data engineering areas of the project.
About the authors
 Thomas Voss
Thomas Voss
Thomas Voss works at Hapag-Lloyd as a data scientist. With his background in academia and logistics, he takes pride in leveraging data science expertise to drive business innovation and growth through the practical design and modeling of AI solutions.
 Bernhard Hersberger
Bernhard Hersberger
Bernhard Hersberger works as a data scientist at Hapag-Lloyd, where he heads the AI Hub team in Hamburg. He is enthusiastic about integrating AI solutions across the company, taking comprehensive responsibility from identifying business issues to deploying and scaling AI solutions worldwide.
 Gabija Pasiunaite
Gabija Pasiunaite
At AWS, Gabija Pasiunaite was a Machine Learning Engineer at AWS Professional Services based in Zurich. She specialized in building scalable ML and data solutions for AWS Enterprise customers, combining expertise in data engineering, ML automation and cloud infrastructure. Gabija has contributed to the AWS MLOps Framework used by AWS customers globally. Outside work, Gabija enjoys exploring new destinations and staying active through hiking, skiing, and running.
 Jean-Michel Lourier
Jean-Michel Lourier
Jean-Michel Lourier is a Senior Data Scientist within AWS Professional Services. He leads teams implementing data driven applications side by side with AWS customers to generate business value out of their data. He’s passionate about diving into tech and learning about AI, machine learning, and their business applications. He is also an enthusiastic cyclist.
 Mousam Majhi
Mousam Majhi
Mousam Majhi is a Senior ProServe Cloud Architect focusing on Data & AI within AWS Professional Services. He works with Manufacturing and Travel, Transportation & Logistics customers in DACH to achieve their business outcomes by leveraging data and AI powered solutions. Outside of work, Mousam enjoys hiking in the Bavarian Alps.