
This post is cowritten by Salesforce’s AI Platform team members Srikanta Prasad, Utkarsh Arora, Raghav Tanaji, Nitin Surya, Gokulakrishnan Gopalakrishnan, and Akhilesh Deepak Gotmare.
Salesforce’s Artificial Intelligence (AI) platform team runs customized large language models (LLMs)—fine-tuned versions of Llama, Qwen, and Mistral—for agentic AI applications like Agentforce. Deploying these models creates operational overheads: teams spend months optimizing instance families, serving engines, and configurations. This process is time-consuming, hard to maintain with frequent releases, and expensive due to GPU capacity reservations for peak usage.
Salesforce solved this by adopting Amazon Bedrock Custom Model Import. With Amazon Bedrock Custom Model Import, teams can import and deploy customized models through a unified API, minimizing infrastructure management while integrating with Amazon Bedrock features like Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Agents. This shift lets Salesforce focus on models and business logic instead of infrastructure.
This post shows how Salesforce integrated Amazon Bedrock Custom Model Import into their machine learning operations (MLOps) workflow, reused existing endpoints without application changes, and benchmarked scalability. We share key metrics on operational efficiency and cost optimization gains, and offer practical insights for simplifying your deployment strategy.
Integration approach
Salesforce’s transition from Amazon SageMaker Inference to Amazon Bedrock Custom Model Import required careful integration with their existing MLOps pipeline to avoid disrupting production workloads. The team’s primary goal was to maintain their current API endpoints and model serving interfaces, keeping zero downtime and no required changes to downstream applications. With this approach, they could use the serverless capabilities of Amazon Bedrock while preserving the investment in their existing infrastructure and tooling. The integration strategy focused on creating a seamless bridge between their current deployment workflows and Amazon Bedrock managed services, enabling gradual migration without additional operational risk.
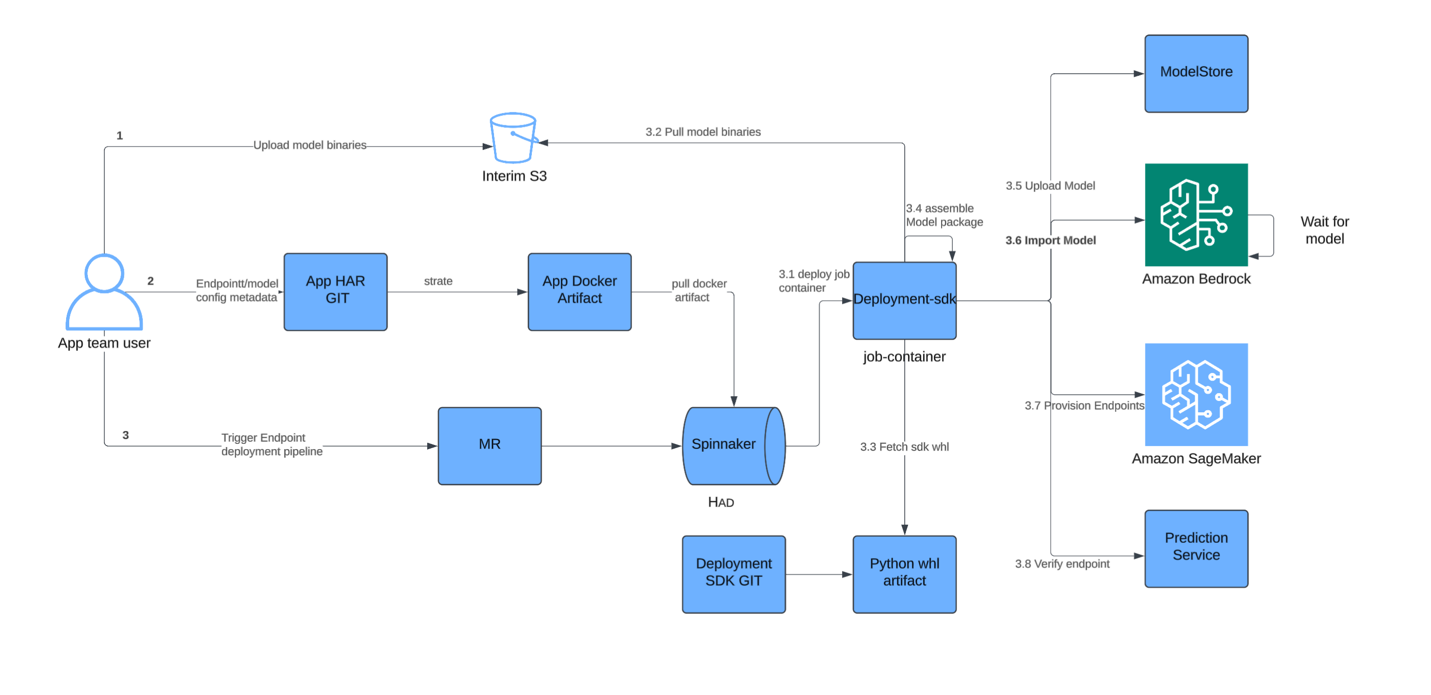
As shown in the following deployment flow diagram, Salesforce enhanced their existing model delivery pipeline with a single additional step to use Amazon Bedrock Custom Model Import. After their continuous integration and continuous delivery (CI/CD) process saves model artifacts to their model store (an Amazon Simple Storage Service (Amazon S3) bucket), they now call the Amazon Bedrock Custom Model Import API to register the model with Amazon Bedrock. This control plane operation is lightweight because Amazon Bedrock pulls the model directly from Amazon S3, adding minimal overhead (5–7 mins, depending on model size) to their deployment timeline—their overall model release process remains at approximately 1 hour. The integration delivered an immediate performance benefit: SageMaker no longer needs to download weights at container startup because Amazon Bedrock preloads the model. The main configuration changes involved granting Amazon Bedrock permissions to allow cross-account access to their S3 model bucket and updating AWS Identity and Access Management (IAM) policies to allow inference clients to invoke Amazon Bedrock endpoints.
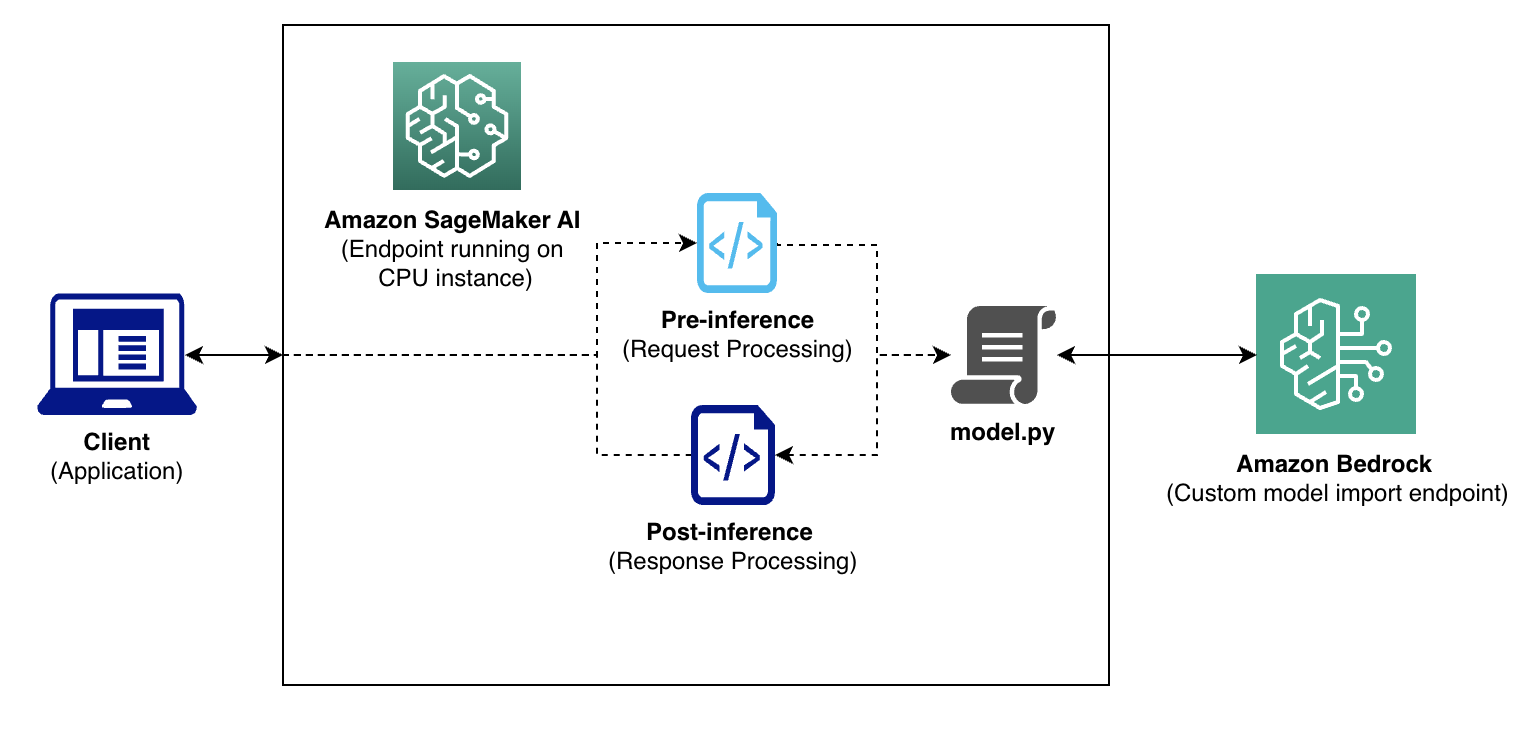
The following inference flow diagram illustrates how Salesforce maintained their existing application interfaces while using Amazon Bedrock serverless capabilities. Client requests flow through their established preprocessing layer for business logic like prompt formatting before reaching Amazon Bedrock, with postprocessing applied to the raw model output. To handle complex processing requirements, they deployed lightweight SageMaker CPU containers that act as intelligent proxies—running their custom model.py logic while forwarding the actual inference to Amazon Bedrock endpoints. This hybrid architecture preserves their existing tooling framework: their prediction service continues calling SageMaker endpoints without routing changes, and they retain mature SageMaker monitoring and logging for preprocessing and postprocessing logic. The trade-off involves an additional network hop adding 5–10 millisecond latency and the cost of always-on CPU instances, but this approach delivers backward-compatibility with existing integrations while keeping the GPU-intensive inference fully serverless through Amazon Bedrock.
Scalability benchmarking
To validate the performance capabilities of Amazon Bedrock Custom Model Import, Salesforce conducted comprehensive load testing across various concurrency scenarios. Their testing methodology focused on measuring how the transparent auto scaling behavior of Amazon Bedrock—where the service automatically spins up model copies on-demand and scales out under heavy load—would impact real-world performance. Each test involved sending standardized payloads containing model IDs and input data through their proxy containers to Amazon Bedrock endpoints, measuring latency and throughput under different load patterns. Results (see the following table) show that at low concurrency, Amazon Bedrock achieved 44% lower latency than the ml.g6e.xlarge baseline (bf16 precision). Under higher loads, Amazon Bedrock Custom Model Import maintained consistent throughput with acceptable latency (less than 10 milliseconds), demonstrating the serverless architecture’s ability to handle production workloads without manual scaling.
Concurrency (Count)
P95 Latency (in Seconds)
Throughput (Request per Minute)
1
7.2
11
4
7.96
41
16
9.35
133
32
10.44
232
The results show P95 latency and throughput performance of the ApexGuru model (fine-tuned QWEN-2.5 13B) at varying concurrency levels. Amazon Bedrock Custom Model Import auto scaled from one to three copies as concurrency reached 32. Each model copy used 1 model unit.
Results and metrics
Beyond scalability improvements, Salesforce evaluated Amazon Bedrock Custom Model Import across two critical business dimensions: operational efficiency and cost optimization. The operational efficiency gains were substantial—the team achieved a 30% reduction in time to iterate and deploy models to production. This improvement stemmed from alleviating complex decision-making around instance selection, parameter tuning, and choosing between serving engines like vLLM vs. TensorRT-LLM. The streamlined deployment process allowed developers to focus on model performance rather than infrastructure configuration.
Cost optimization delivered even more dramatic results, with Salesforce achieving up to 40% cost reduction through Amazon Bedrock. This savings was primarily driven by their diverse traffic patterns across generative AI applications—ranging from low to high production traffic—where they previously had to reserve GPU capacity for peak workloads. The pay-per-use model proved especially beneficial for development, performance testing, and staging environments that only required GPU resources during active development cycles, avoiding the need for round-the-clock reserved capacity that often sat idle.
Lessons learned
Salesforce’s journey with Amazon Bedrock Custom Model Import revealed several key insights that can guide other organizations considering a similar approach. First, although Amazon Bedrock Custom Model Import supports popular open source model architectures (Qwen, Mistral, Llama) and expands its portfolio frequently based on demand, teams working with cutting-edge architectures might need to wait for support. However, organizations fine-tuning with the latest model architectures should verify compatibility before committing to the deployment timeline.
For pre- and post-inference processing, Salesforce evaluated alternative approaches using Amazon API Gateway and AWS Lambda functions, which offer complete serverless scaling and pay-per-use pricing down to milliseconds of execution. However, they found this approach less backward-compatible with existing integrations and observed cold start impacts when using larger libraries in their processing logic.
Cold start latency emerged as a critical consideration, particularly for larger (over 7B parameter) models. Salesforce observed cold start delays of a couple of minutes with 26B parameter models, with latency varying based on model size. For latency-sensitive applications that can’t tolerate such delays, they recommend keeping endpoints warm by maintaining at least one model copy active through health check invocations every 14 minutes. This approach balances cost-efficiency with performance requirements for production workloads.
Conclusion
Salesforce’s adoption of Amazon Bedrock Custom Model Import shows how to simplify LLM deployment without sacrificing scalability or performance. They achieved 30% faster deployments and 40% cost savings while maintaining backward-compatibility through their hybrid architecture using SageMaker proxy containers alongside Amazon Bedrock serverless inference. For highly customized models or unsupported architectures, Salesforce continues using SageMaker AI as a managed ML solution.
Their success came from methodical execution: thorough load testing, and gradual migration starting with non-critical workloads. The results prove serverless AI deployment works for production, especially with variable traffic patterns. ApexGuru is now deployed in their production environment.
For teams managing LLMs at scale, this case study provides a clear blueprint. Check your model architecture compatibility, plan for cold starts with larger models, and preserve existing interfaces. Amazon Bedrock Custom Model Import offers a proven path to serverless AI that can reduce overhead, speed deployment, and cut costs while meeting performance requirements.
To learn more about pricing for Amazon Bedrock, refer to Optimizing cost for using foundational models with Amazon Bedrock and Amazon Bedrock pricing.
For help choosing between Amazon Bedrock and SageMaker AI, see Amazon Bedrock or Amazon SageMaker AI?
For more information about Amazon Bedrock Custom Model Import, see How to configure cross-account model deployment using Amazon Bedrock Custom Model Import.
For more details about ApexGuru, refer to Get AI-Powered Insights for Your Apex Code with ApexGuru.
About the authors
 Srikanta Prasad is a Senior Manager in Product Management specializing in generative AI solutions at Salesforce. He leads Model Hosting and Inference initiatives, focusing on LLM inference serving, LLMOps, and scalable AI deployments.
Srikanta Prasad is a Senior Manager in Product Management specializing in generative AI solutions at Salesforce. He leads Model Hosting and Inference initiatives, focusing on LLM inference serving, LLMOps, and scalable AI deployments.
 Utkarsh Arora is an Associate Member of Technical Staff at Salesforce, combining strong academic grounding from IIIT Delhi with early career contributions in ML engineering and research.
Utkarsh Arora is an Associate Member of Technical Staff at Salesforce, combining strong academic grounding from IIIT Delhi with early career contributions in ML engineering and research.
 Raghav Tanaji is a Lead Member of Technical Staff at Salesforce, specializing in machine learning, pattern recognition, and statistical learning. He holds an M.Tech from IISc Bangalore.
Raghav Tanaji is a Lead Member of Technical Staff at Salesforce, specializing in machine learning, pattern recognition, and statistical learning. He holds an M.Tech from IISc Bangalore.
 Akhilesh Deepak Gotmare is a Senior Research Staff Member at Salesforce Research, based in Singapore. He is an AI Researcher focusing on deep learning, natural language processing, and code-related applications
Akhilesh Deepak Gotmare is a Senior Research Staff Member at Salesforce Research, based in Singapore. He is an AI Researcher focusing on deep learning, natural language processing, and code-related applications
 Gokulakrishnan Gopalakrishnan is a Principal Software Engineer at Salesforce, where he leads engineering efforts on ApexGuru. With 15+ years of experience, including at Microsoft, he specializes in building scalable software systems
Gokulakrishnan Gopalakrishnan is a Principal Software Engineer at Salesforce, where he leads engineering efforts on ApexGuru. With 15+ years of experience, including at Microsoft, he specializes in building scalable software systems
 Nitin Surya is a Lead Member of Technical Staff at Salesforce with 8+ years in software/ML engineering. He holds a B.Tech in CS from VIT University and MS in CS (AI/ML focus) from University of Illinois Chicago.
Nitin Surya is a Lead Member of Technical Staff at Salesforce with 8+ years in software/ML engineering. He holds a B.Tech in CS from VIT University and MS in CS (AI/ML focus) from University of Illinois Chicago.
 Hrushikesh Gangur is a Principal Solutions Architect at AWS based in San Francisco, California. He specializes in generative and agentic AI, helping startups and ISVs build and deploy AI applications.
Hrushikesh Gangur is a Principal Solutions Architect at AWS based in San Francisco, California. He specializes in generative and agentic AI, helping startups and ISVs build and deploy AI applications.