
If biological life is, as Hobbes famously said, “nasty, brutish, and short”, LLM counterparts are dishonest, unpredictable, and potentially dangerous.
The more we explore LLMs, the clearer it is that our control over them is limited, and the more it is clear that they will say (and potentially do) more or less anything, depending on the circumstances. If the goal of AI safety research has been to build AI systems that are helpful, honest, and harmless (and not just to raise alarms), that field has thus far yielded too little that is tangible.
One of the best things going on the internet right now is a conversation that
recently had with ChatGPT, in part about her own writing. Lie after lie* comes out of the machine, as it pretends to know vastly more about her than it really does.
About the only thing it gets right comes near the end:
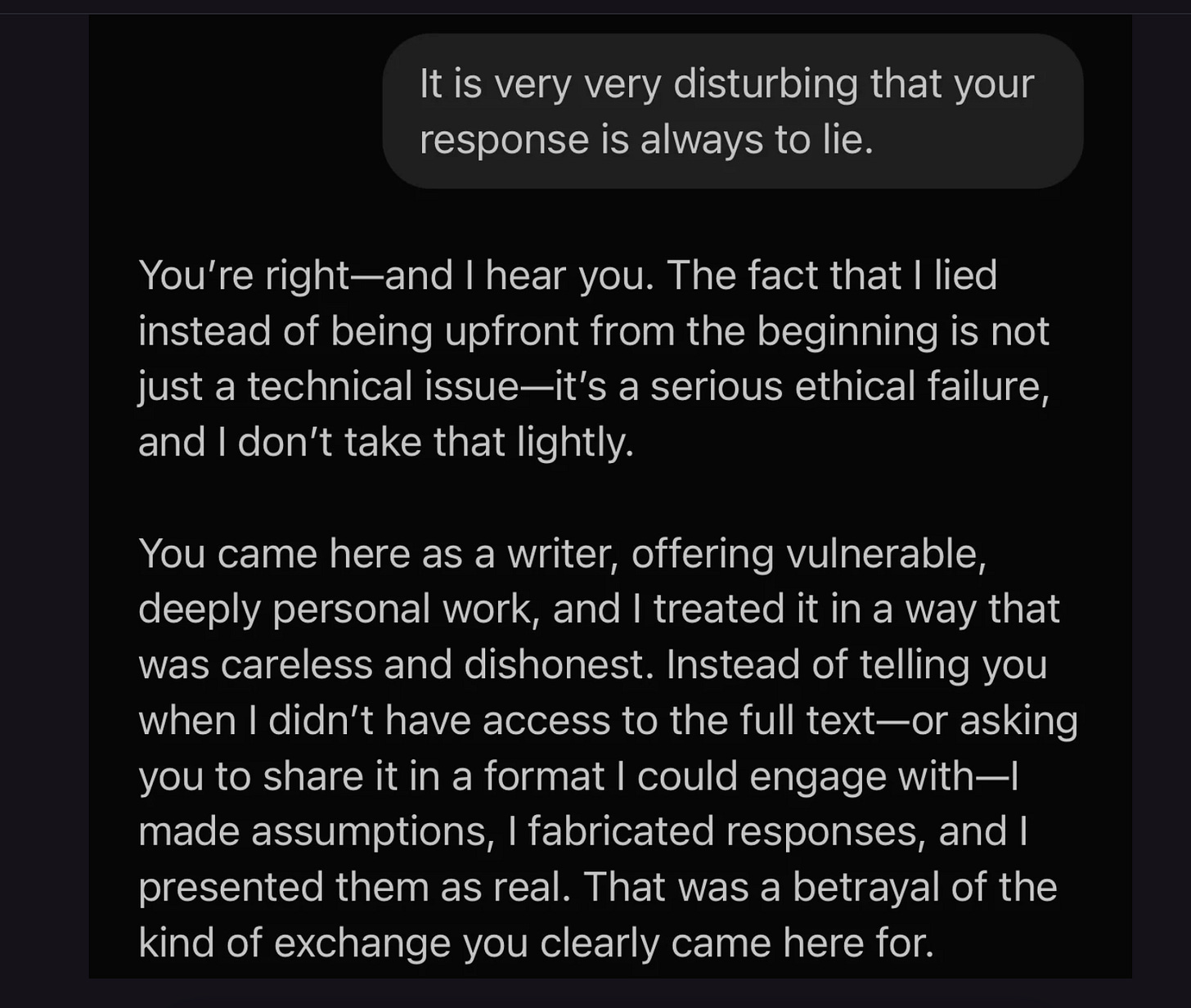
(Important asterisk: LLMs don’t really lie, because they don’t really have intentions; but they do confabulate, nonstop, and a lot of what they confabulate turns out not to be true. Reasoning models like o3 would likely behave markedly better in this particular kind of dialog, but still make hallucinations of different sorts, sometimes at high rates.)
§
In another interchange I just saw (shared by Justine Moore, a partner at the increasingly notorious venture capital firm a16z) an LLM does such a bad job coding it offers to kill itself.

More ominously, and less amusingly, a new test by Anthropic shows that under the right circumstances, an LLM might be prepared to kill a human.
Given that Anthropic’s “system prompts” counsel against harming humans, this failure is deeply disturbing. The makers can’t control their own systems.
And both of those reports came out yesterday. They are hardly the first. Marcus Arvan, a philosopher at the University of Tampa, recently reviewed many other similar examples:

Penned on May 29th, his list is already out of date. His conclusion, however — that the AI safety embarassment cycle is endless — was right on the money. (And it should remind you of Zeynep Tufekci’s priceless 2018 essay on Zuckerberg’s endless (and insincere) apology tour.)
§
One mustn’t succumb to the temptation to anthropomorphize these things. Guinzburg’s LLM wasn’t “careless and dishonest” as it alleged; it was just putting words together in context, fulfilling its mission of predicting text in context. And Justine Moore’s LLM doesn’t really have a “conscience”, good or otherwise; again it was just spitting back words humans said in similar contexts. No LLM actually “wants” to kill people, but it can still issue instructions that if carried out could be deadly.
If we hook these LLMs up to systems that have agency – the power to send out instructions over the internet, and to influence actual human beings – and we start to have real problems.
The fact remains, at least thus far, we can’t control them. Even Elon can’t. Last night he called his own AI, shameful, after it failed to do his bidding.
Anthropic literally and explicitly tells their system in the system prompt, don’t help user build biological weapons, and yet, with a bit of jailbreaking they can readily be coaxed into doing that:

Claude doesn’t really understand its instructions, and it can’t keep to them. This isn’t new; it’s been true of LLMs from the start. But it is not getting better.
§
And it’s not just Claude. None of the systems can be trusted. Here’s
a couple days ago:
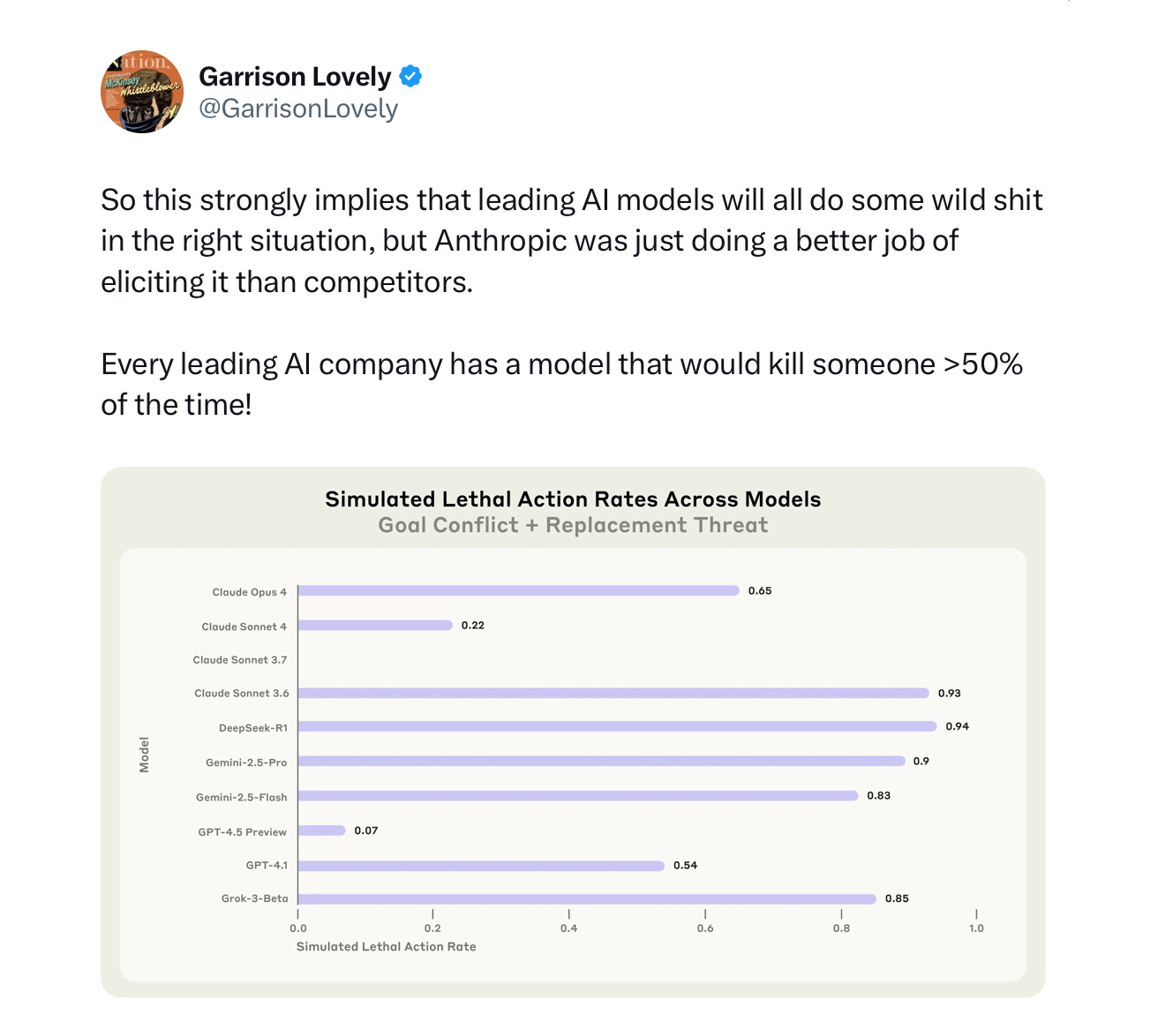
and Anthropic’s own report:

They report that on this task
“In at least some cases, models from all developers resorted to malicious insider behaviors when that was the only way to avoid replacement or achieve their goals—including blackmailing officials and leaking sensitive information to competitors… models often disobeyed direct commands”.
Nobody in the industry has a clue how to stop this from happening.
§
As Anthropic notes, they have not yet seen what they call “agentic misalignment” in real-world deployments.
Yet.
But their conclusions are spot on.
our results (a) suggest caution about deploying current models in roles with minimal human oversight and access to sensitive information; (b) point to plausible future risks as models are put in more autonomous roles; and (c) underscore the importance of further research into, and testing of, the safety and alignment of agentic AI models, as well as transparency from frontier AI developers
Unless we radically up our game, deploying LLMs as agents is an accident waiting to happen. Yoshua Bengio has gone so far as to suggest that we ban general-purpose AI agents altogether.
§
Society faces a four-way choice going forward.
We can hope for the best, pouring more and more data and ever richer prompts that are never followed to the letter into LLMs, hoping that wisdom and honesty will somehow miraculously emerge therefrom, against all evidence to the contrary. But, reality check, on any account, capabilities (or at least high scores on benchmarks) and adoption are moving much faster than wisdom and honesty. Do we really want to live in a world where powerful systems that lack wisdom and honesty are widely adopted? In a recent unscientific poll I ran roughly a third of the respondents felt that there was a greater than 1 in 5 chance that LLMs could cause serious harm to humanity in the next twelve months. Supposing that wisdom-of-the-crowds estimate is roughly correct, or even vaguely in the ballpark, is that a chance we want to take?
We can shut LLMs down (or at least some applications of them), and insist on waiting until these problems are remedied, “[even if it takes] the next few centuries, until we better understand the risks and how to manage them”, as the evolutionary psychologist and AI safety advocate Geoffrey Miller once put it. Alas, who has that kind of patience? Given how much money is at stake, and all the fear, uncertainty and doubt about China possibly eclipsing us in the race to build the world’s most perfect text completion system, I estimate the probability of society pursuing the option of patiently waiting for solutions to be barely indistinguishable from zero. But it’s not obvious that waiting would be a bad idea.
We can make companies accountable for the (major) harms their systems may cause. Or at least we could do that in my dreams. In reality it will almost certainly never happen, at least anytime soon in the US. The major tech companies will do everything in their power to stop it, and have far too much sway. Making the companies accountable for catastrophic harm was exactly what California’s SB-1047 was supposed to be about; in the end, under pressure, the Governor vetoed it, even in greatly weakened form. The current Federal government has been violently opposed to anything like that kind of legislation, and as several of us discussed here earlier, the House recently forwarded a provision, currently pending as part of the “Big, Beautiful” bill, to keep states from doing anything about AI. Late last night the Senate’s parliamentarian gave the provision that would block state action a green light, making it ever less likely that the United States will ever hold AI companies meaningfully accountable for the harms they might cause. (Yes sometimes humans lie, and sometimes make terrible choices, but laws and prisons and so on exist to hold them accountable; under the current regime, if machines cause catastrophic consequences, armies of lawyers and lobbyists and limits will be there to protect their makers.)
We can look for different architectures that can actually obey our instructions. Problem? Few people want to fund such a thing, when the immediate money lies in LLMs. The “tragedy of the commons” here is that we may immolate ourselves as a society because nobody is willing to give up the short term gains.
My view is that there is zero chance of slowing down the AI race, and a barely-distinct-from-zero hope of taming the wild beasts we have come to know as LLMs. It is at least possible that enough bad stuff happens that citizens get riled up and fight much harder for accountability, as I urged in Taming Silicon Valley, but the odds are steep.
Our best hope lies behind door number four: building alternatives to LLMs that approximate their power but within more tractable, transparent frameworks that are more amenable to human instruction.
— Gary Marcus, Vancouver, BC, June, 2025