
Deep learning is indeed finally hitting a wall, in the sense of reaching a point of diminishing results. That’s been clear for months. One of the clearest signs of this is the saga of the just-released Llama 4, the latest failed billion (?) dollar attempt by one of the majors to create what we might call GPT-5 level AI. OpenAI failed at this (calling their best result GPT-4.5, and recently announcing a further delay on GPT-5); Grok failed at this (Grok 3 is no GPT 5). Google has failed at reaching “GPT-5” level, Anthropic has, too. Several others have also taken shots on goal; none have succeeded.
According to media reports LLama 4 was delayed, in part, because despite the massive capital invested, it failed to meet expectations. But that’s not the scandal. That delay and failure to meet expectations is what I have been predicting for years, since the first day of this Substack, and it is what has happened to everyone else. (Some, like Nadella, have been candid about it). Meta did an experiment, and the experiment didn’t work; that’s science. The idea that you could predict a model’s performance entirely according to its size and the size of its data just turns out to be wrong, and Meta is the latest victim, the latest to waste massive sums on a mistaken hypothesis about scaling data and compute. But that’s just the start of today’s seedy story.
According to a rumor that sounds pretty plausible, the powers-that-be at Meta weren’t happy with the results, and wanted something better badly enough that they may have tried to cheat, per a thread on reddit (original in Chinese):
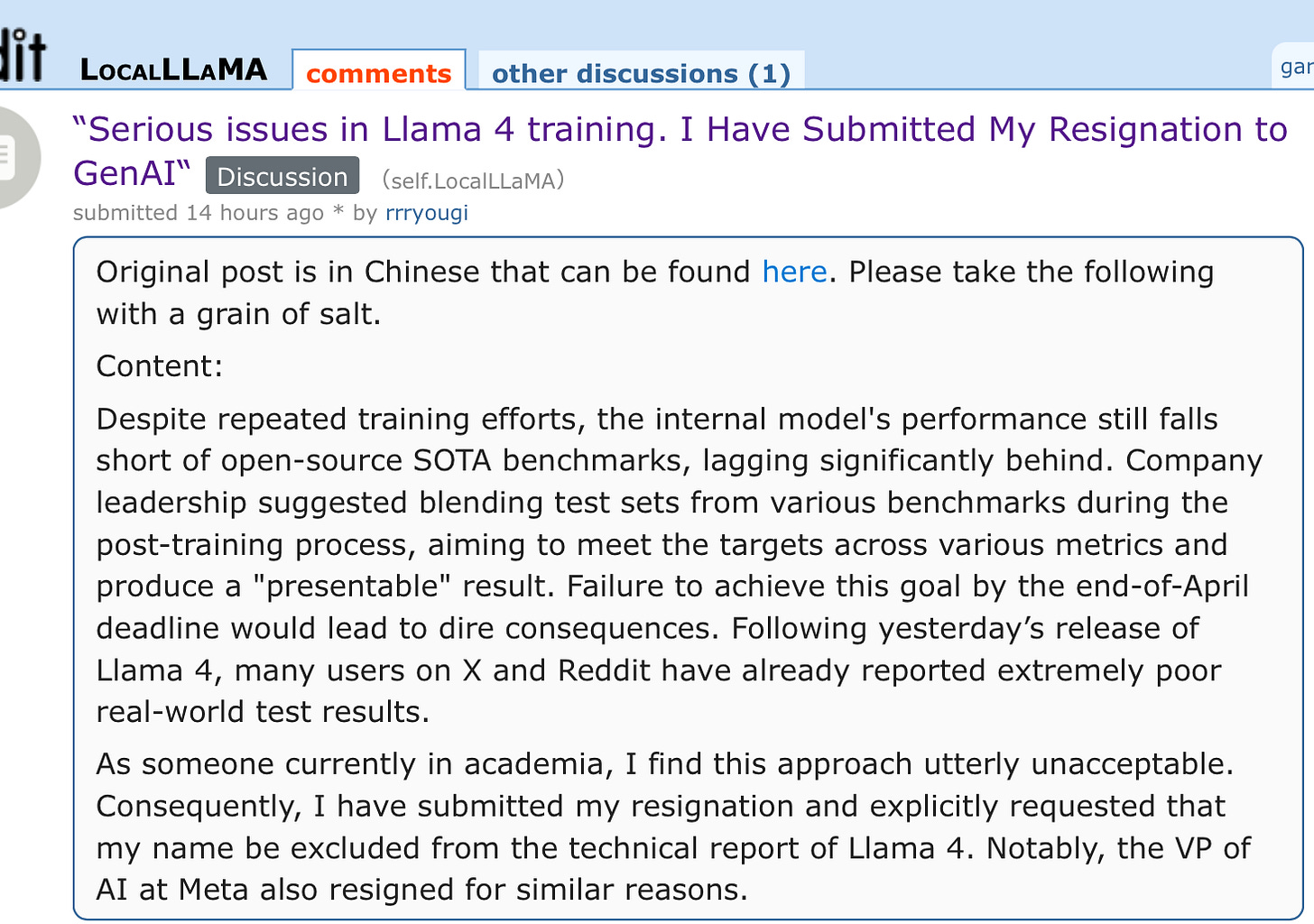
While I cannot directly attest to the veracity of the rumor, I can report two other things that seem to corroborate it. First, the AI community is in fact pretty disappointed with LLama 4’s performance:

And second, the part about the Meta VP of AI resigning checks out. Joelle Pineau, just abruptly quit Meta. I have known her for years to be someone who cares about the integrity of machine learning research; I often point to a wonderful piece of work of hers (done at McGill before she joined Meta) called the AI Replicability Checklist. Her leaving fits awfully well with the reddit report. What is rumored to have happened would be an absolute violation of Pineau’s values.
This looks really bad. It should also remind people of Alex Reisner’s important recent article in the Atlantic, “Chatbots are cheating on their benchmark tests”, the dismal results of several much ballyhoo’ed systems on a math exam that (to prevent data leakage) had been released only a few hours before, and some dodgy circumstances around OpenAI’s o3 and the FrontierMath benchmark.
It also makes me think of an essay at LessWrong from a couple of weeks ago that I discovered belatedly this morning, entitled “recent AI model progress feels mostly like bullshit”. Key passage (highlighting by Jade Cole):

§
If the juicing of benchmarks and “blending” of test data is the primary scandal, there is a secondary scandal too: a bunch of well-paid pundits, such as Roose, Newton, and Cowen, are failing to reckon with the repeated failures of massive companies to build GPT-5.
Not one has to my knowledge publicly asked the difficult questions about data leakage and data contamination. Not one to my knowledge has factored the repeated failures in building GPT-5 level models into their “AGI timelines.” Rather, from what I can tell, these pundits mainly get their timeline ideas from the producers of Generative AI – discounting the fact that such people have heavily vested interests — too often taking their word as gospel. Just because Meta or OpenAI wants you to believe something doesn’t mean it is true.
Real world customers, many of whom are disappointed, are rarely mentioned. Failures like the Humane AI pin are glossed over, in service of the “AGI is imminent” narrative. The fact that, per a recent AAAI survey, 84% of AI researchers think LLMs won’t be enough to reach AGI has also been conveniently ignored.
Even Nadella (who said in November, breaking ranks, “have we hit the wall with scaling laws. Is it gonna continue? Again, the thing to remember at the end of the day these are not physical laws. There are just empirical observations that hold true just like Moore’s law did for a long period of time”) is ignored.
§
The reality, reported or otherwise, is that large language models are no longer living up to expectations, and its purveyors appear to be making dodgy choices to keep that fact from becoming obvious.