
“Tavily is now available on AWS Marketplace and integrates natively with Amazon Bedrock AgentCore Gateway. This makes it even faster for developers and enterprises to embed real-time web intelligence into secure, AWS-powered agents.”

As enterprises accelerate their AI adoption, the demand for agent frameworks that can autonomously gather, process, and synthesize information has increased. Traditional approaches to building AI agents often require extensive orchestration code, explicit state management, and rigid architectures that are difficult to maintain and scale.
Strands Agents simplifies agent development by addressing these challenges. It introduces a model-centric paradigm that shifts the complexity from hard-coded logic into the large language model (LLM) itself. This dramatically reduces development overhead while increasing agent flexibility—for example, minimizing the need to write explicit logic for each input or output type. By embedding logic directly into the model, agents can be significantly improved simply by swapping in more advanced models as they are released.
In this post, we introduce how to combine Strands Agents with Tavily’s purpose-built web intelligence API, to create powerful research agents that excel at complex information gathering tasks while maintaining the security and compliance standards required for enterprise deployment.
Strands Agents SDK: Model-centric agent framework
The Strands Agents SDK is an open source framework that revolutionizes AI agent development by embracing a model-driven approach. It offers a code-first, lightweight yet powerful framework for building agentic workflows. Instead of requiring complex orchestration code, the Strands Agents SDK helps developers create sophisticated agents through three primary components:
Models – Offers flexible integration with leading LLM providers, including Amazon Bedrock, Anthropic, Ollama, and LiteLLM, and provides an extensible interface for implementing custom model providers.
Tools – Allows agents to interact with external systems, access data, and manipulate their environment. Strands Agents offers more than 20 built-in tool capabilities, and helps developers create custom tools using simple Python function decorators.
Prompts – Supports natural language instructions that guide agent behavior and objectives.
Strands Agents offers an advanced and rich feature set. With the Strands Agents SDK, developers can build intelligent agents with minimal code while maintaining enterprise-grade capabilities:
Security and responsible AI – Provides seamless integration with guardrails for content filtering, personally identifiable information (PII) protection, and more
Streamlined agent development lifecycle – Helps developers run agents locally and build complex evaluation workflows that can be automated as part of your continuous integration and delivery (CI/CD) pipelines
Flexible deployment – Offers support for many deployment options, from dedicated servers to serverless
Observability – Supports OpenTelemetry standard for transmitting logs, metrics, and traces
Strands Agents abstracts away the complexity of building, orchestrating, and deploying intelligent agents, providing a natural language-based interaction and control coupled with dynamic output generation. The result is a more intuitive and powerful development experience.
Tavily: Secure, modular web intelligence for AI agents
Tavily is an API-first web intelligence layer designed specifically for LLM agents, powering real-time search, high-fidelity content extraction, and structured web crawling. Built for developers building AI-based systems, Tavily is engineered for precision, speed, and modularity. It offers a seamless integration experience for agent frameworks like Strands Agents.Tavily’s API is an enterprise-grade infrastructure layer trusted by leading AI companies. It combines robust capabilities with production-grade operational guarantees, such as:
SOC 2 Type II compliance – Supports best-in-class security and privacy posture
Zero data retention – No queries, payloads, or user data are stored, maintaining compliance with strict internal policies and regulatory frameworks
Plug-and-play with Amazon Bedrock and private LLMs – Supports hybrid cloud deployments, private language model use, and latency-sensitive inference stacks
Modular endpoints – Designed for agent-style interaction, Tavily provides purpose-built APIs for:
Search – Retrieve semantically ranked links and content snippets across the public web, filtered by domain, recency, or count
Extract – Pull raw content or cleaned markdown from known URLs for summarization, QA, or embedding
Crawl – Traverse websites recursively through links to simulate exploratory behavior and build site maps
Each endpoint is exposed as a standalone tool, meaning they can be quickly wrapped into your agent framework’s tool schema (such as OpenAI’s tool-calling, LangChain, Strands, or ReAct-based implementations).
Combining Strands Agents with the Tavily web infrastructure
By combining the flexibility of the Strands Agents SDK with Tavily’s real-time web intelligence capabilities, developers can build dynamic, LLM-powered agents that interact intelligently with the internet. These agents can reason over open-ended queries, make decisions based on natural language prompts, and autonomously gather, process, and deliver insights from the web.This integration can be appropriate for a wide range of agent-based applications. For example:
Customer success agents that proactively retrieve the latest product documentation, policy updates, or external FAQs to resolve support issues faster
Internal employee assistants that answer workplace questions by pulling from both internal tools and publicly available information, reducing dependency on knowledge silos
Sales and revenue agents that surface timely company news and industry shifts to support account planning and outreach
Each use case benefits from the same foundation: a developer-friendly agent framework, composable web intelligence tools, and the decision-making power of LLMs.To demonstrate how this comes together in practice, we explore a focused implementation: a research agent designed for autonomous, high-fidelity web investigation.
Research agent example
Many research agent implementations require extensive development efforts and rely on deterministic logic or workflows with constrained inputs and outputs. Alternatively, Strands enables developers to build highly dynamic agents through natural language. Strands agents use prompt engineering to dynamically generate varied output types and accept diverse natural language inputs seamlessly.Combining Tavily with Strands unlocks a new class of agents purpose-built for deep, dynamic research. Unlike hardcoded research pipelines, this pairing helps developers accomplish the following:
Rapidly develop powerful research agents using Tavily’s endpoints (Search, Crawl, Extract) as tools within the Strands Agents framework, offering a developer-friendly interface
Offload complex decision-making relying on the LLM’s native capabilities
Inherit performance boosts automatically with every new generation of model (for example, Anthropic Claude’s on Amazon Bedrock or Amazon Nova), as the flexible agent architecture dynamically improves with minimal code changes
Combine the enterprise security infrastructure of Amazon Bedrock with Tavily’s zero data retention policies to create a highly secure environment for sensitive research tasks
With Strands Agents and Tavily’s capabilities combined, the agents excel in gathering industry intelligence and providing organizations with real-time insights into trends, competitor activities, and emerging opportunities. Agents can conduct comprehensive competitive analysis, scouring vast amounts of online data to identify strengths, weaknesses, and strategic positioning of industry players. In the realm of technical research, these agents can rapidly assimilate and synthesize complex information from multiple sources, which can help accelerate innovation and problem-solving processes. Additionally, such agents prove invaluable for regulatory compliance monitoring by continuously scanning and interpreting evolving legal landscapes to make sure organizations stay ahead of regulatory changes. The flexibility of the Strands Agents SDK allows for customization to specific industry needs—it’s equally effective for tasks ranging from customer service automation to sophisticated data analysis workflows.
Solution overview
To illustrate this combination, we created a deep researcher implementation (see the GitHub repo) that uses the agent loop capability at the core of the Strands Agents SDK to intelligently and autonomously choose from Tavily’s web intelligence capabilities. The following diagram illustrates this workflow.
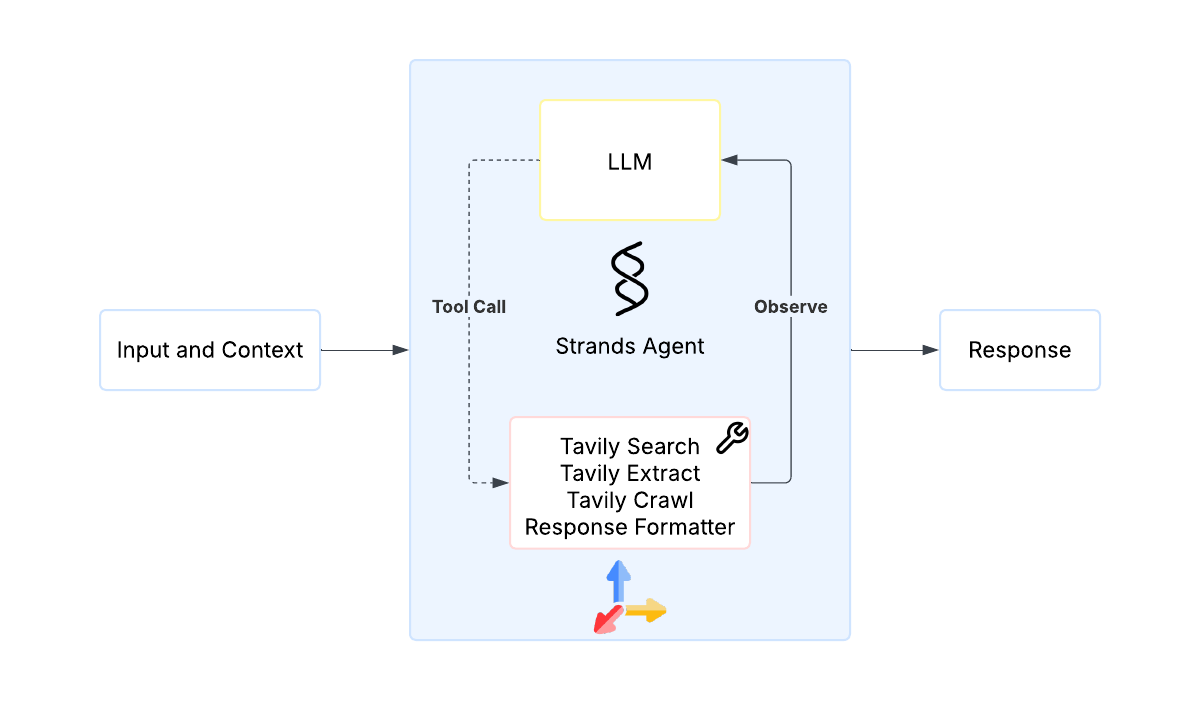
We configured the Strands Agents SDK to use Anthropic’s Claude 4 Sonnet on Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies through a unified API. The following diagram illustrates the solution architecture.
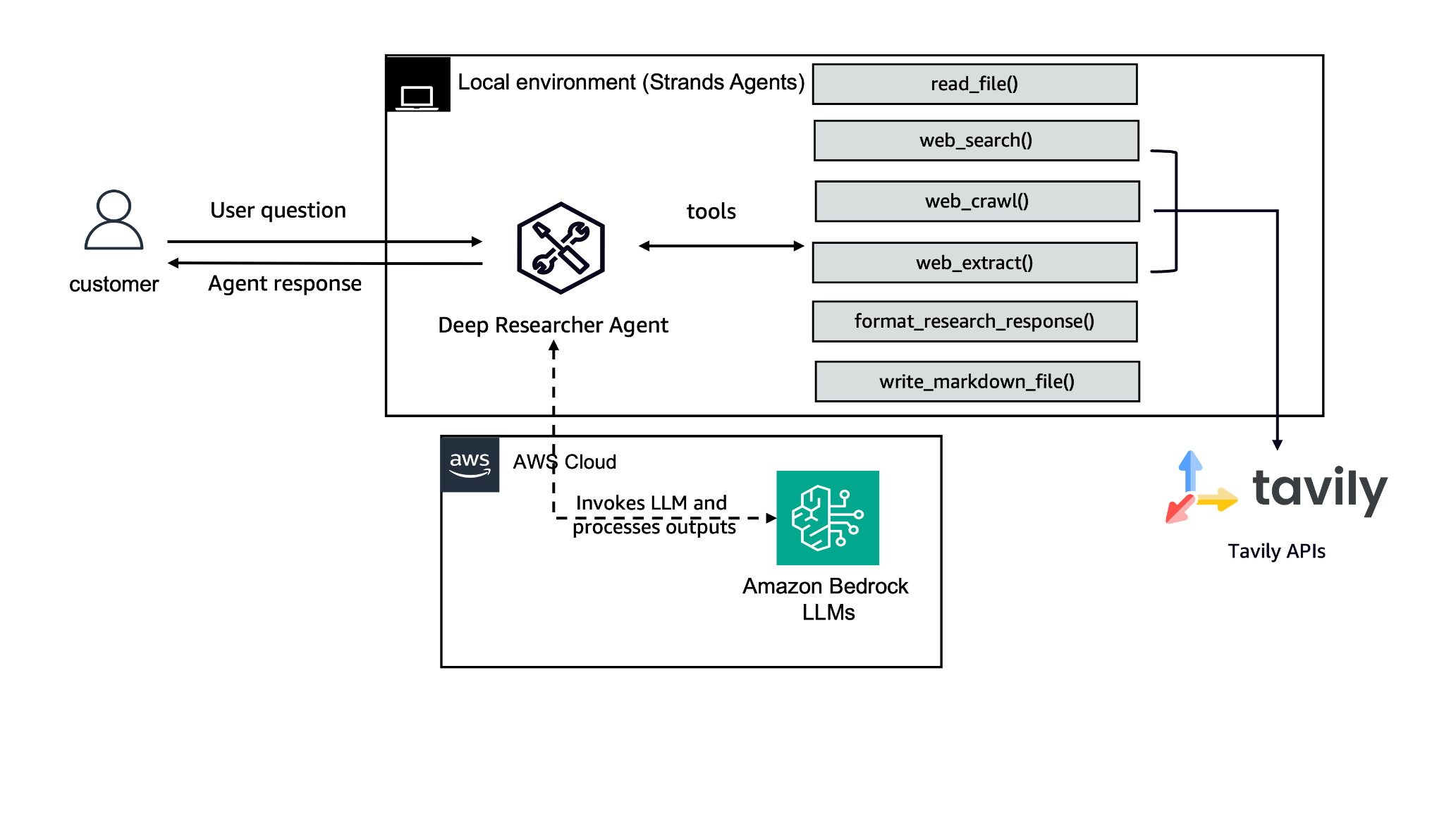
This research agent is composed of three primary components:
Large language model – Powers the agent to understand queries and generate responses
Tools – Helps the agent gather information from the internet using Tavily’s APIs, format the response, and save the output in Markdown format
System prompt – Guides the agent’s behavior, outlining how and when to use each tool to achieve its research objectives
In the following sections, we discuss the LLM and tools in more detail.
Large language model
The LLM influences the behavior of the agent as well as the quality of the generated response. We decided to use Anthropic’s Claude 4 Sonnet on Amazon Bedrock for its ability to plan and execute complex tasks, but you can use one of the other models supported by Amazon Bedrock or another model provider.
Tools
Tools help extend agents’ capabilities and interact with external services such as Tavily. We implemented the following tools to enable our agent to perform deep research over the internet and provide a formatted output:
web_search – Search the web for relevant information
web_extract – Extract the full page content from a webpage
web_crawl – Crawl entire websites and scrape their content
format_research_response – Transform raw research content into clear, well-structured, and properly cited responses
write_markdown_file – Save the research output in Markdown forward on the local file system
To define a tool with the Strands Agents SDK, you can simply wrap a Python function with the @tool decorator and provide a Python docstring with the tool description. Let’s explore an example of how we implemented the web_search tool using Tavily’s search endpoint.The search endpoint lets agents discover relevant webpages based on a natural language query. Results include URLs, title, content snippets, semantic scores, or even the full content of matched pages. You can fine-tune searches with parameters such as:
Max number of results – Limits the number of results to an upper bound
Time range filtering – Limits the results to content published within a specific time frame
Domain restrictions – Restricts results to specific domains
See the following code:
LLMs rely heavily on the tool definition and description to determine how and when to use them. To improve tool accuracy, consider the following best practices:
Clearly explain when the tool should be used and its functionally
Use type hints in the function signature to describe the parameters, return types, and default values
Detail each parameter and provide examples of the accepted formats
Each Tavily endpoint can be exposed to a language model as a distinct tool, giving AI agents flexible, granular access to the web. By combining these tools, agents become dramatically more capable at tasks like research, summarization, competitive intelligence, and decision-making. You can find the other tools implementation in the GitHub repository.
Strategic value proposition
AWS chose Tavily for the following benefits:
Shared vision – Tavily and AWS both serve the next generation of AI-based builders, with a strong emphasis on enterprise-readiness, security, and privacy
Marketplace integration – Tavily is available on AWS Marketplace, making integration and procurement seamless for enterprise customers
Go-to partner for web access – AWS chose Tavily as the premier tool for real-time search integration within the Strands Agents SDK, providing the best web access experience for agent developers
Amazon Bedrock – Amazon Bedrock is a fully managed, secure service that offers a choice of high-performing FMs from leading AI companies like Meta, Anthropic, AI21, and Amazon
Conclusion
The combination of the Strands Agents SDK and Tavily represents a significant advancement in enterprise-grade research agent development. This integration can help organizations build sophisticated, secure, and scalable AI agents while maintaining the highest standards of security and performance. To learn more, refer to the following resources:
About the authors
 Akarsha Sehwag is a Generative AI Data Scientist in Amazon Bedrock Agents GTM team. With over six years of expertise in AI/ML product development, she has built Machine learning solutions across diverse customer segments.
Akarsha Sehwag is a Generative AI Data Scientist in Amazon Bedrock Agents GTM team. With over six years of expertise in AI/ML product development, she has built Machine learning solutions across diverse customer segments.
 Lorenzo Micheli is a Principal Delivery Consultant at AWS Professional Services, focused on helping Global Financial Services and Healthcare organizations navigate their cloud journey. He develops strategic roadmaps for generative AI adoption and cloud-native architectures that drive innovation while ensuring alignment with their business objectives and regulatory requirements.
Lorenzo Micheli is a Principal Delivery Consultant at AWS Professional Services, focused on helping Global Financial Services and Healthcare organizations navigate their cloud journey. He develops strategic roadmaps for generative AI adoption and cloud-native architectures that drive innovation while ensuring alignment with their business objectives and regulatory requirements.
 Dean Sacoransky is a Forward Deployed Engineer at Tavily, specializing in applied AI. He helps enterprises and partners use Tavily’s web infrastructure technology to power and enhance their AI systems.
Dean Sacoransky is a Forward Deployed Engineer at Tavily, specializing in applied AI. He helps enterprises and partners use Tavily’s web infrastructure technology to power and enhance their AI systems.
 Lee Tzanani is Head of GTM and Partnerships at Tavily. She leads strategic collaborations with Tavily’s most valuable partners and works with enterprise and Fortune 500 customers to integrate real-time web search into production AI systems. Lee drives Tavily’s go-to-market efforts across the AI landscape, advancing its mission to onboard the next billion AI agents to the web.
Lee Tzanani is Head of GTM and Partnerships at Tavily. She leads strategic collaborations with Tavily’s most valuable partners and works with enterprise and Fortune 500 customers to integrate real-time web search into production AI systems. Lee drives Tavily’s go-to-market efforts across the AI landscape, advancing its mission to onboard the next billion AI agents to the web.
 Sofia Guzowski leads Partnerships and Community at Tavily, where she works with companies to integrate real-time web data into their AI products. She focuses on strategic collaborations, developer engagement, and bringing Tavily’s APIs to the broader AI landscape.
Sofia Guzowski leads Partnerships and Community at Tavily, where she works with companies to integrate real-time web data into their AI products. She focuses on strategic collaborations, developer engagement, and bringing Tavily’s APIs to the broader AI landscape.