
As organizations increasingly adopt foundation models (FMs) for their artificial intelligence and machine learning (AI/ML) workloads, managing large-scale inference operations efficiently becomes crucial. Amazon Bedrock supports two general types of large-scale inference patterns: real-time inference and batch inference for use cases that involve processing massive datasets where immediate results aren’t necessary.
Amazon Bedrock batch inference is a cost-effective solution that offers a 50% discount compared to on-demand processing, making it ideal for high-volume, time-insensitive workloads. However, implementing batch inference at scale comes with its own set of challenges, including managing input formatting and job quotas, orchestrating concurrent executions, and handling postprocessing tasks. Developers need a robust framework to streamline these operations.
In this post, we introduce a flexible and scalable solution that simplifies the batch inference workflow. This solution provides a highly scalable approach to managing your FM batch inference needs, such as generating embeddings for millions of documents or running custom evaluation or completion tasks with large datasets.
Solution overview
The following diagram details a broad overview of the automated workflow, which includes three main phases: preprocessing of input datasets (for example, prompt formatting), execution of batch inference jobs in parallel, and postprocessing to parse the model outputs.
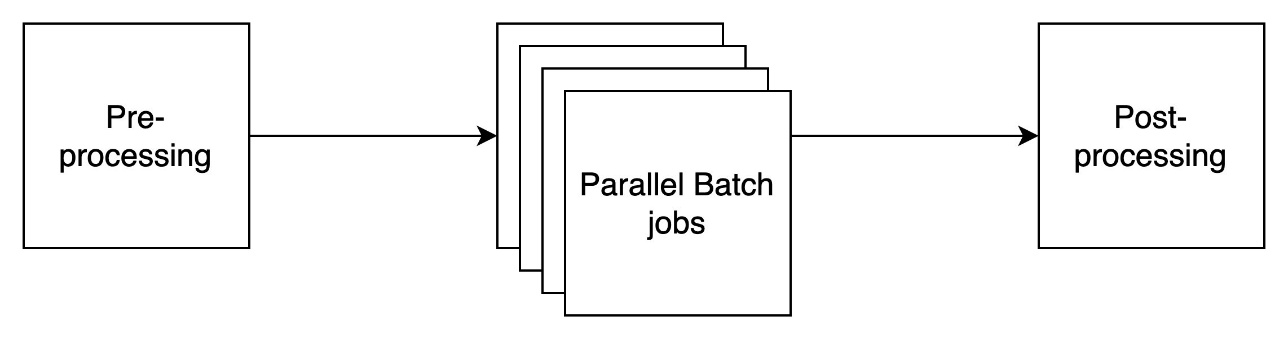
This solution provides a flexible and scalable framework to simplify batch orchestration. Given a simple configuration input, the Step Functions state machine deployed in this AWS Cloud Development Kit (AWS CDK) stack handles preprocessing the dataset, launching parallel batch jobs, and postprocessing the output.
In our specific use case, we use 2.2 million rows of data from the open source dataset SimpleCoT. The SimpleCoT dataset on Hugging Face is a collection of diverse task-oriented examples designed to demonstrate and train chain-of-thought (CoT) reasoning in language models. This dataset encompasses a wide range of problem types, including reading comprehension, mathematical reasoning, logical deduction, and natural language processing (NLP) tasks. The dataset is structured with each entry containing a task description, question, the correct answer, and a detailed explanation of the reasoning process.
The following diagram illustrates the solution architecture.
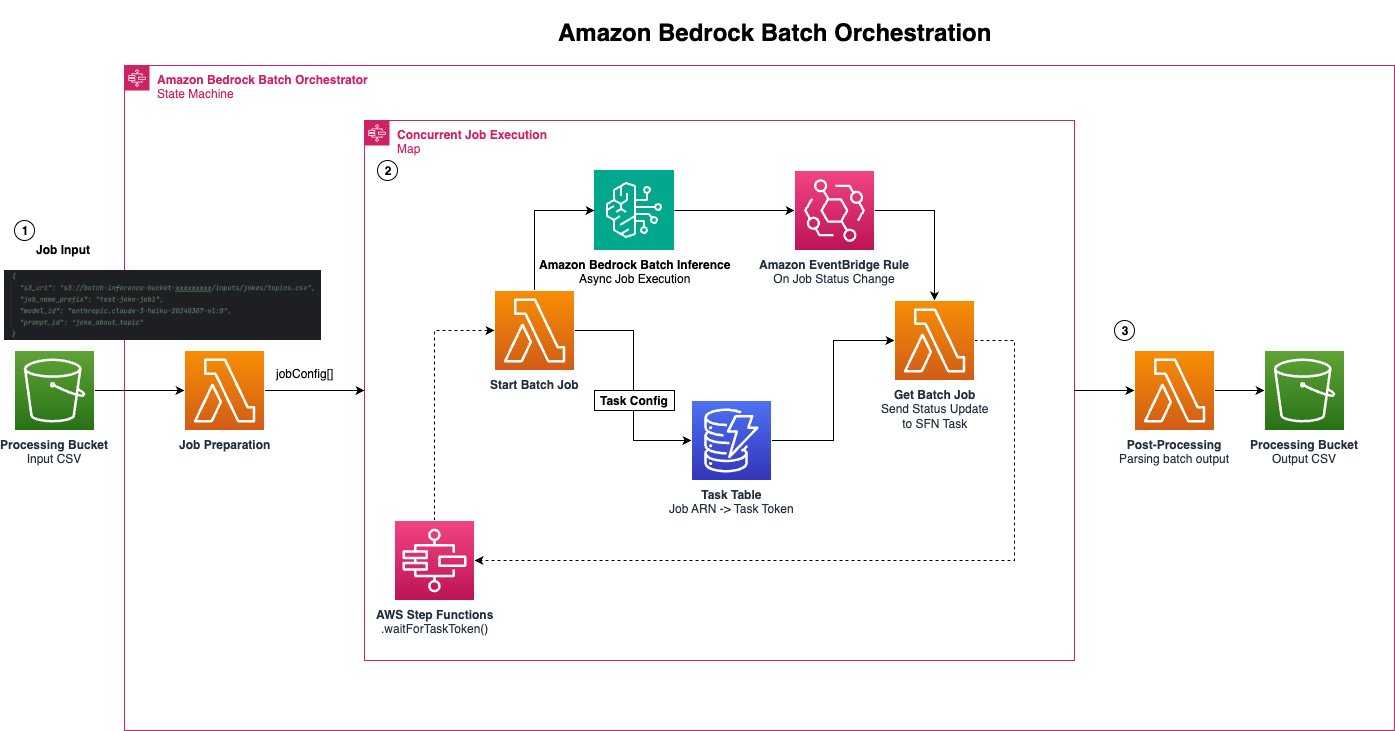
The Amazon Bedrock batch orchestration pattern uses scalable and serverless components to cover the key architectural considerations specific to batch processing workflows:
File format and storage – Job inputs must be structured as JSONL files stored in an Amazon Simple Storage Service (Amazon S3) bucket, with each line representing a single input record that matches the API request structure for that FM or provider. For example, Anthropic’s Claude models have a different JSON structure compared to Amazon Titan Text Embeddings V2. There are also quotas to consider: at the time of writing, a minimum of 1,000 and maximum of 50,000 records per batch. You can request a quota increase using Service Quotas based on your use case requirements.
Step Functions state machine – Orchestration of the asynchronous, long-running jobs requires a robust control flow system. Our architecture uses Step Functions to coordinate the overall process, with Amazon DynamoDB maintaining the inventory of individual jobs and their states. Again, there are important quota considerations: for example, the maximum sum of in-progress and submitted batch inference jobs using a base model for Amazon Titan Text Embeddings V2 is currently 20 per AWS Region. Using Map workflow states, Step Functions can help maximize throughput by controlling job submission and monitoring completion status.
Postprocessing – Finally, you will likely want to perform some light postprocessing on the batch outputs (also JSONL files in Amazon S3) to parse the responses and join the output back to the original input. For example, when generating text embeddings, you must have a mechanism to map output vectors back to their source text. These configurable AWS Lambda functions are triggered as part of the Step Functions workflow after batch results arrive in Amazon S3.
In the following sections, we walk through the steps to deploy the AWS CDK stack to your AWS environment.
Prerequisites
Complete the following prerequisite steps:
Install node and npm.
Install the AWS CDK:
Clone the GitHub repository into your local development environment:
Deploy the solution
Install the required packages with the following code:npm i
Check the prompt_templates.py file and add a new prompt template to prompt_id_to_template for your desired use case.
prompt_id_to_template is a dict where the key is the prompt_id (allowing you to associate a given job with a particular prompt). Formatting keys in the prompt string template must also exist in your input file. For example, consider the following prompt template:
You must make sure your input dataset has a column for each formatting key (for example, source in the preceding example code).
Prompt templates are not used for embedding model-based jobs.Deploy the AWS CDK stack with the following code:npm run cdk deploy
Take note of the AWS CloudFormation outputs denoting the names of the bucket and Step Functions workflow:
Job input structure
As your input dataset, you can either use a Hugging Face dataset ID or point directly to a dataset in Amazon S3 (CSV or Parquet formats are supported at the time of writing). The source of the input dataset and the type of model (text generation or embedding) dictate the structure of the Step Functions input.
Hugging Face dataset
For a Hugging Face dataset, reference a dataset ID (for example, w601sxs/simpleCoT) and split (for example, train), and your dataset will be pulled directly from Hugging Face Hub.

The question_answering prompt template in prompt_templates.py has a formatting key called source to match the name of the appropriate column in the referenced dataset (see the preceding example). We use this prompt to generate the rationale and answer for each of the 2.2 million rows in the dataset. See the following code:
We also have optional keys for max_num_jobs (to limit the total number of jobs, which is useful for testing on a smaller scale) and max_records_per_batch.
Amazon S3 dataset
Upload an input CSV or parquet file to the S3 bucket and copy the S3 URI. For example:aws s3 cp topics.csv s3://batch-inference-bucket-/inputs/jokes/topics.csv
Open your Step Functions state machine on the Step Functions console and submit an input with the following structure. You must supply an s3_uri for S3 datasets.
For example, for Anthropic models with an Amazon S3 input, use the following code:
The prompt_id of joke_about_topic maps to a prompt template in prompt_templates.py, which has a formatting key for topic, which must be one of the columns in the input CSV file.
Generate batch embeddings
To generate embeddings with a model like Amazon Titan Text Embeddings V2, you don’t need to provide a prompt_id, but you do need to make sure your input CSV file has a column called input_text with the text you want to embed. For example:
Step Functions workflow
The following diagram shows an example of a successful Step Functions workflow execution.
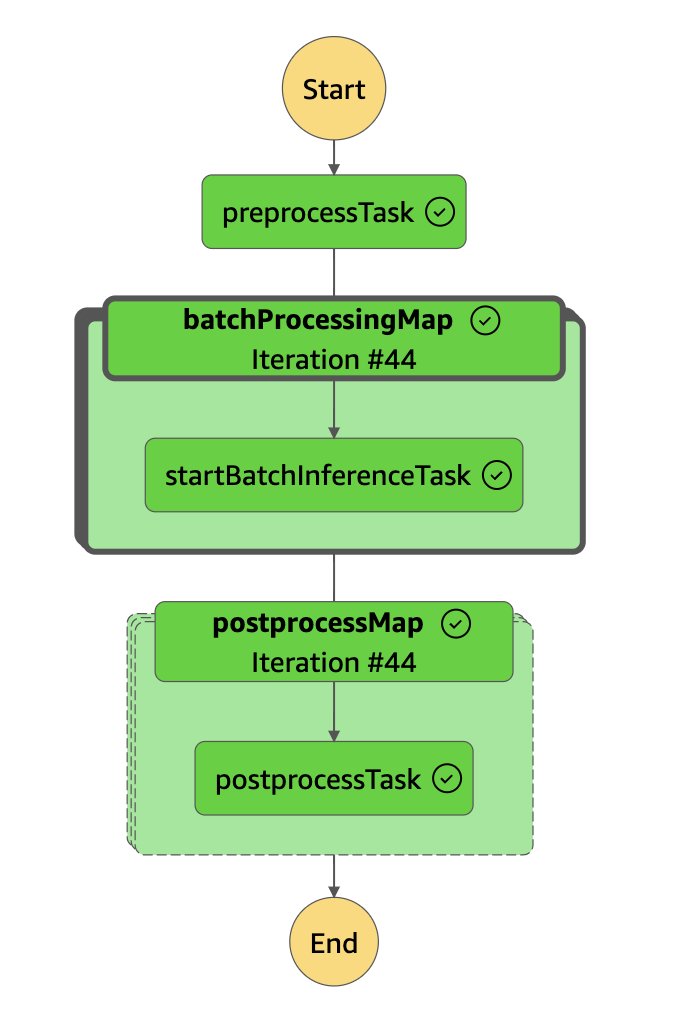
When a Step Functions state machine is initiated, it completes the following steps:
Preprocess input datasets to prepare batch job inputs for your particular model ID and prompt template. The BaseProcessor abstract class can quickly be extended for other model providers, such as Meta Llama 3 or Amazon Nova.
Orchestrate batch jobs in an event-driven fashion. We maintain an internal inventory of jobs in a DynamoDB table and keep it updated when Amazon Bedrock emits events related to job status changes. These updates are then transmitted back to the step function using the Wait for Task Token Callback integration pattern. Using a SFN Map, we make sure that the maximum capacity of concurrent jobs is maintained until the records have been processed.
Run concurrent postprocessing of batch outputs to perform some light parsing and merge model responses back to the original input data using the recordId field as a join key. The output data depends on the kind of model you use. For text-based models, the output string will be in a new column called response.
Monitor your state machine as it runs the jobs. The maximum number of concurrent jobs is controlled by an AWS CDK context variable in cdk.json (key: maxConcurrentJobs). The paths to your resulting Parquet files will be aggregated in the outputs from the execution.
The output Parquet files will contain the same columns as your input file alongside the generated responses.
For text generation models, the output string will be in a new column called response, as shown in the following screenshot of a sample output.

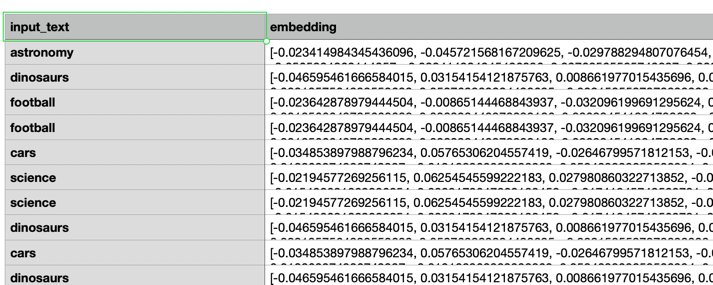
For embedding models, the output (list of floats) will be in a new column called embedding, as shown in the following screenshot.
There are no guaranteed SLAs for the Batch Inference API. Runtimes will vary based on the demand of the desired model at the time of your request. For example, to process the 2.2 million records in the SimpleCoT dataset, execution was spread across 45 individual processing jobs, with a maximum of 20 concurrent jobs at a given time. In our experiment with Anthropic’s Claude Haiku 3.5 in the us-east-1 Region, each individual job execution took an average of 9 hours, for a total end-to-end processing time of about 27 hours.
Clean up
To avoid incurring additional costs, you can clean up the stack’s resources by running cdk destroy.
Conclusion
In this post, we outlined a serverless architecture for performing large-scale batch processing using Amazon Bedrock batch inference. We explored using the solution for various use cases, including large-scale data labeling and embedding generation. You can also generate a large amount synthetic data from a teacher model used to train a student model as part of model distillation process.
The solution is publicly available in the GitHub repo. We can’t wait to see how you put this architecture to work for your use cases.
About the authors
 Swagat Kulkarni is a Senior Solutions Architect at AWS and an active Generative AI practitioner. He is passionate about helping customers solve real-world challenges using cloud-native services and machine learning. With a strong background in driving digital transformation across diverse industries, Swagat has delivered impactful solutions that enable innovation and scale. Outside of work, he enjoys traveling, reading, and cooking.
Swagat Kulkarni is a Senior Solutions Architect at AWS and an active Generative AI practitioner. He is passionate about helping customers solve real-world challenges using cloud-native services and machine learning. With a strong background in driving digital transformation across diverse industries, Swagat has delivered impactful solutions that enable innovation and scale. Outside of work, he enjoys traveling, reading, and cooking.
 Evan Diewald is a Data & Machine Learning Engineer with AWS Professional Services, where he helps AWS customers develop and deploy ML solutions in a variety of industry verticals. Prior to joining AWS, he received an M.S. from Carnegie Mellon University, where he conducted research at the intersection of advanced manufacturing and AI. Outside of work, he enjoys mountain biking and rock climbing.
Evan Diewald is a Data & Machine Learning Engineer with AWS Professional Services, where he helps AWS customers develop and deploy ML solutions in a variety of industry verticals. Prior to joining AWS, he received an M.S. from Carnegie Mellon University, where he conducted research at the intersection of advanced manufacturing and AI. Outside of work, he enjoys mountain biking and rock climbing.
 Shreyas Subramanian is a Principal Data Scientist and helps customers by using Generative AI and deep learning to solve their business challenges using AWS services like Amazon Bedrock and AgentCore. Dr. Subramanian contributes to cutting-edge research in deep learning, Agentic AI, foundation models and optimization techniques with several books, papers and patents to his name. In his current role at Amazon, Dr. Subramanian works with various science leaders and research teams within and outside Amazon, helping to guide customers to best leverage state-of-the-art algorithms and techniques to solve business critical problems. Outside AWS, Dr. Subramanian is a expert reviewer for AI papers and funding via organizations like Neurips, ICML, ICLR, NASA and NSF.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using Generative AI and deep learning to solve their business challenges using AWS services like Amazon Bedrock and AgentCore. Dr. Subramanian contributes to cutting-edge research in deep learning, Agentic AI, foundation models and optimization techniques with several books, papers and patents to his name. In his current role at Amazon, Dr. Subramanian works with various science leaders and research teams within and outside Amazon, helping to guide customers to best leverage state-of-the-art algorithms and techniques to solve business critical problems. Outside AWS, Dr. Subramanian is a expert reviewer for AI papers and funding via organizations like Neurips, ICML, ICLR, NASA and NSF.