
Retrieval Augmented Generation (RAG) is a fundamental approach for building advanced generative AI applications that connect large language models (LLMs) to enterprise knowledge. However, crafting a reliable RAG pipeline is rarely a one-shot process. Teams often need to test dozens of configurations (varying chunking strategies, embedding models, retrieval techniques, and prompt designs) before arriving at a solution that works for their use case. Furthermore, management of high-performing RAG pipeline involves complex deployment, with teams often using manual RAG pipeline management, leading to inconsistent results, time-consuming troubleshooting, and difficulty in reproducing successful configurations. Teams struggle with scattered documentation of parameter choices, limited visibility into component performance, and the inability to systematically compare different approaches. Additionally, the lack of automation creates bottlenecks in scaling the RAG solutions, increases operational overhead, and makes it challenging to maintain quality across multiple deployments and environments from development to production.
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement. By combining experimentation and automation with SageMaker AI, you can verify that the entire pipeline is versioned, tested, and promoted as a cohesive unit. This approach provides comprehensive guidance for traceability, reproducibility, and risk mitigation as the RAG system advances from development to production, supporting continuous improvement and reliable operation in real-world scenarios.
Solution overview
By streamlining both experimentation and operational workflows, teams can use SageMaker AI to rapidly prototype, deploy, and monitor RAG applications at scale. Its integration with SageMaker managed MLflow provides a unified platform for tracking experiments, logging configurations, and comparing results, supporting reproducibility and robust governance throughout the pipeline lifecycle. Automation also minimizes manual intervention, reduces errors, and streamlines the process of promoting the finalized RAG pipeline from the experimentation phase directly into production. With this approach, every stage from data ingestion to output generation operates efficiently and securely, while making it straightforward to transition validated solutions from development to production deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from data preparation and vector embedding generation to model inference and evaluation all with repeatable and version-controlled code. Integrating continuous integration and delivery (CI/CD) practices further enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from development to staging or production environments. Promoting an entire RAG pipeline (not just an individual subsystem of the RAG solution like a chunking layer or orchestration layer) to higher environments is essential because data, configurations, and infrastructure can vary significantly across staging and production. In production, you often work with live, sensitive, or much larger datasets, and the way data is chunked, embedded, retrieved, and generated can impact system performance and output quality in ways that are not always apparent in lower environments. Each stage of the pipeline (chunking, embedding, retrieval, and generation) must be thoroughly evaluated with production-like data for accuracy, relevance, and robustness. Metrics at every stage (such as chunk quality, retrieval relevance, answer correctness, and LLM evaluation scores) must be monitored and validated before the pipeline is trusted to serve real users.
The following diagram illustrates the architecture of a scalable RAG pipeline built on SageMaker AI, with MLflow experiment tracking seamlessly integrated at every stage and the RAG pipeline automated using SageMaker Pipelines. SageMaker managed MLflow provides a unified platform for centralized RAG experiment tracking across all pipeline stages. Every MLflow execution run whether for RAG chunking, ingestion, retrieval, or evaluation sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The architecture uses SageMaker Pipelines to orchestrate the entire RAG workflow through versioned, repeatable automation. These RAG pipelines manage dependencies between critical stages, from data ingestion and chunking to embedding generation, retrieval, and final text generation, supporting consistent execution across environments. Integrated with CI/CD practices, SageMaker Pipelines enable seamless promotion of validated RAG configurations from development to staging and production environments while maintaining infrastructure as code (IaC) traceability.
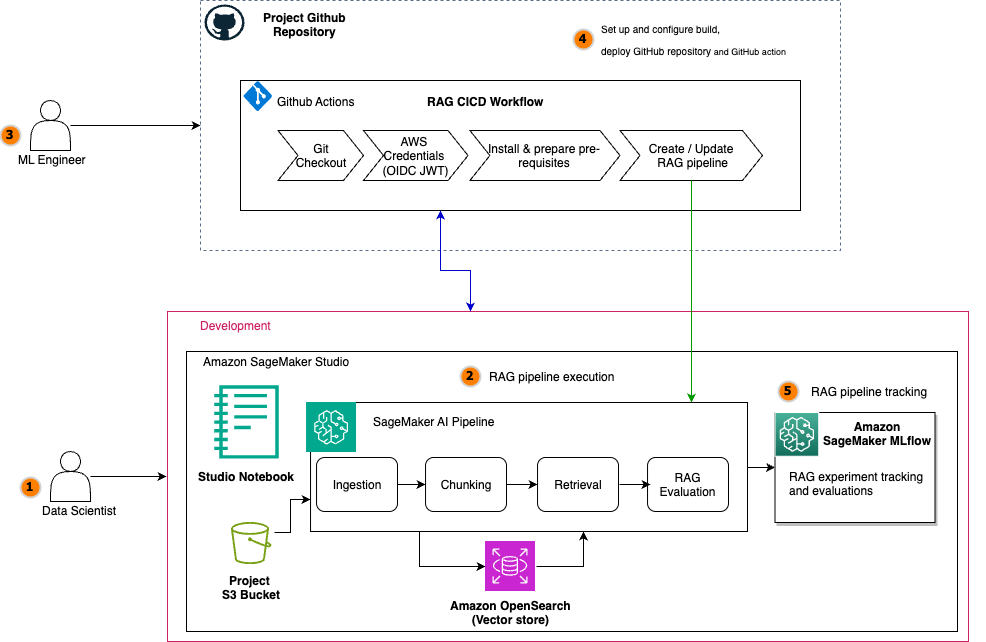
For the operational workflow, the solution follows a structured lifecycle: During experimentation, data scientists iterate on pipeline components within Amazon SageMaker Studio notebooks while SageMaker managed MLflow captures parameters, metrics, and artifacts at every stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion phase uses CI/CD to trigger pipeline execution in target environments, rigorously validating stage-specific metrics (chunk quality, retrieval relevance, answer correctness) against production data before deployment. The other core components include:
Amazon SageMaker JumpStart for accessing the latest LLM models and hosting them on SageMaker endpoints for model inference with the embedding model huggingface-textembedding-all-MiniLM-L6-v2 and text generation model deepseek-llm-r1-distill-qwen-7b.
Amazon OpenSearch Service as a vector database to store document embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
The Amazon Bedrock model anthropic.claude-3-haiku-20240307-v1:0 as an LLM-as-a-judge component for all the MLflow LLM evaluation metrics.
A SageMaker Studio notebook for a development environment to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You can implement this agentic RAG solution code from the GitHub repository. In the following sections, we use snippets from this code in the repository to illustrate RAG pipeline experiment evolution and automation.
Prerequisites
You must have the following prerequisites:
An AWS account with billing enabled.
A SageMaker AI domain. For more information, see Use quick setup for Amazon SageMaker AI.
Access to a running SageMaker managed MLflow tracking server in SageMaker Studio. For more information, see the instructions for setting up a new MLflow tracking server.
Access to SageMaker JumpStart to host LLM embedding and text generation models.
Access to the Amazon Bedrock foundation models (FMs) for RAG evaluation tasks. For more details, see Subscribe to a model.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow provides a powerful framework for organizing RAG experiments, so teams can manage complex, multi-stage processes with clarity and precision. The following diagram illustrates the RAG experiment stages with SageMaker managed MLflow experiment tracking at every stage. This centralized tracking offers the following benefits:
Reproducibility: Every experiment is fully documented, so teams can replay and compare runs at any time
Collaboration: Shared experiment tracking fosters knowledge sharing and accelerates troubleshooting
Actionable insights: Visual dashboards and comparative analytics help teams identify the impact of pipeline changes and drive continuous improvement
The following diagram illustrates the solution workflow.
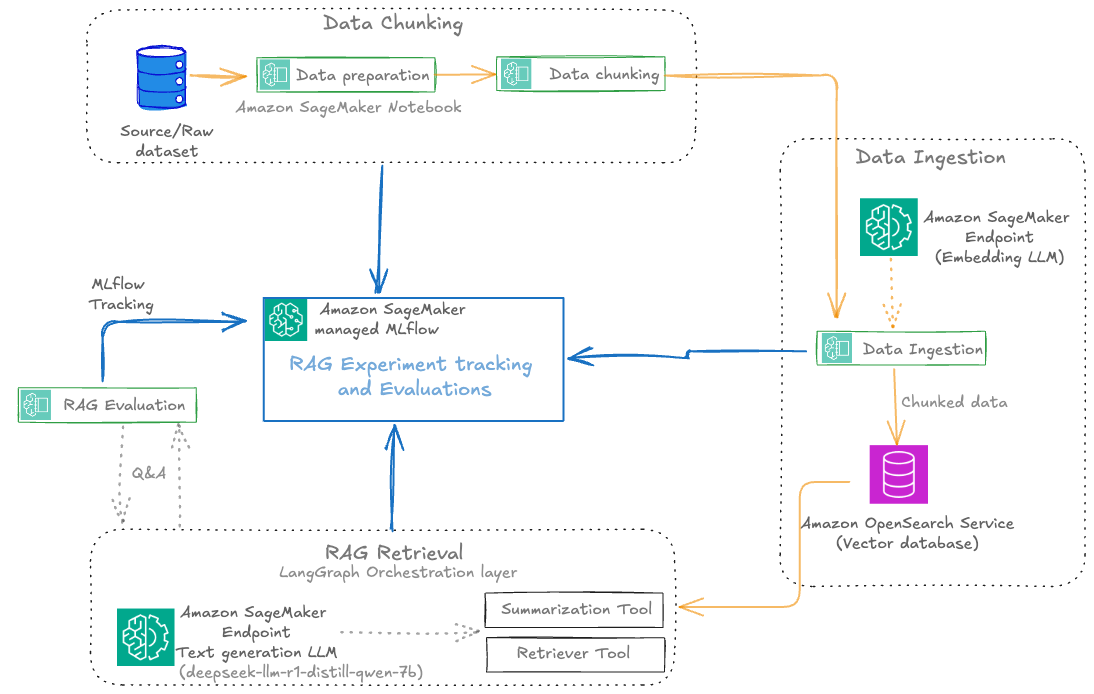
Each RAG experiment in MLflow is structured as a top-level run under a specific experiment name. Within this top-level run, nested runs are created for each major pipeline stage, such as data preparation, data chunking, data ingestion, RAG retrieval, and RAG evaluation. This hierarchical approach allows for granular tracking of parameters, metrics, and artifacts at every step, while maintaining a clear lineage from raw data to final evaluation results.
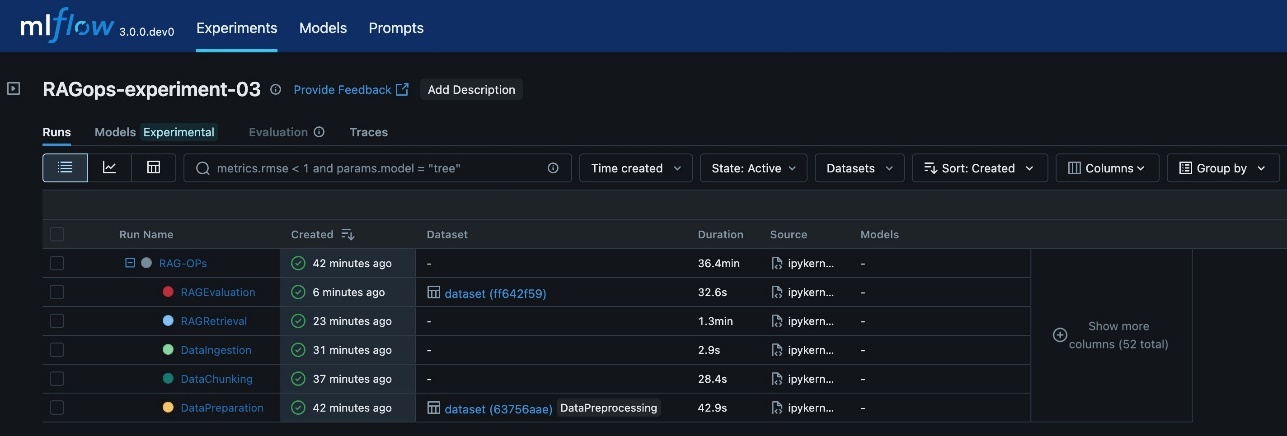
The following screenshot shows an example of the experiment details in MLflow.
The various RAG pipeline steps defined are:
Data preparation: Logs dataset version, preprocessing steps, and initial statistics
Data chunking: Records chunking strategy, chunk size, overlap, and resulting chunk counts
Data ingestion: Tracks embedding model, vector database details, and document ingestion metrics
RAG retrieval: Captures retrieval model, context size, and retrieval performance metrics
RAG evaluation: Logs evaluation metrics (such as answer similarity, correctness, and relevance) and sample results
This visualization provides a clear, end-to-end view of the RAG pipeline’s execution, so you can trace the impact of changes at any stage and achieve full reproducibility. The architecture supports scaling to multiple experiments, each representing a distinct configuration or hypothesis (for example, different chunking strategies, embedding models, or retrieval parameters). MLflow’s experiment UI visualizes these experiments side by side, enabling side-by-side comparison and analysis across runs. This structure is especially valuable in enterprise settings, where dozens or even hundreds of experiments might be conducted to optimize RAG performance.
We use MLflow experimentation throughout the RAG pipeline to log metrics and parameters, and the different experiment runs are initialized as shown in the following code snippet:
RAG pipeline experimentation
The key components of the RAG workflow are ingestion, chunking, retrieval, and evaluation, which we explain in this section. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline.

Data ingestion and preparation
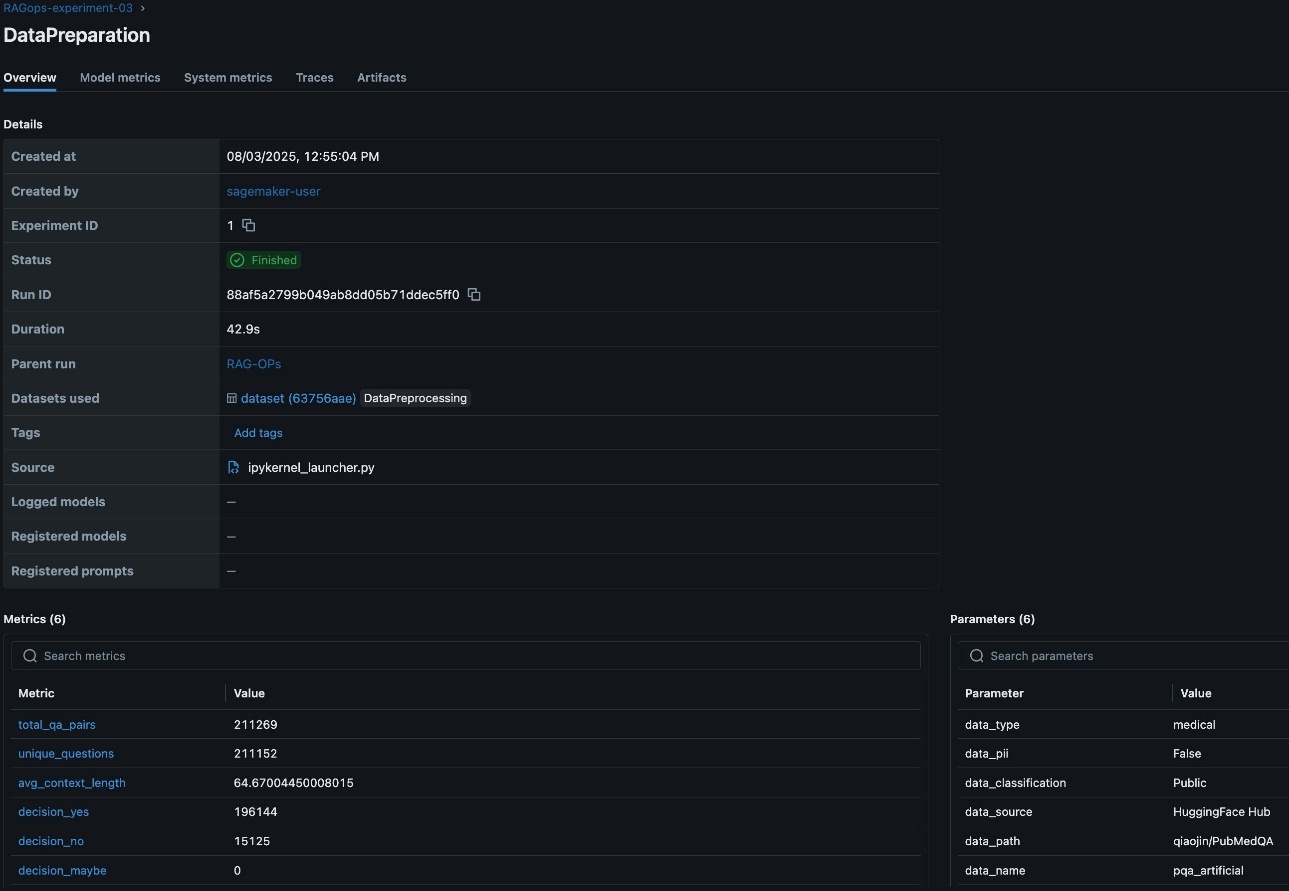
In the RAG workflow, rigorous data preparation is foundational to downstream performance and reliability. Tracking detailed metrics on data quality, such as the total number of question-answer pairs, the count of unique questions, average context length, and initial evaluation predictions, provides essential visibility into the dataset’s structure and suitability for RAG tasks. These metrics help validate the dataset is comprehensive, diverse, and contextually rich, which directly impacts the relevance and accuracy of the RAG system’s responses. Additionally, logging critical RAG parameters like the data source, detected personally identifiable information (PII) types, and data lineage information is vital for maintaining compliance, reproducibility, and trust in enterprise environments. Capturing this metadata in SageMaker managed MLflow supports robust experiment tracking, auditability, efficient comparison, and root cause analysis across multiple data preparation runs, as visualized in the MLflow dashboard. This disciplined approach to data preparation lays the groundwork for effective experimentation, governance, and continuous improvement throughout the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
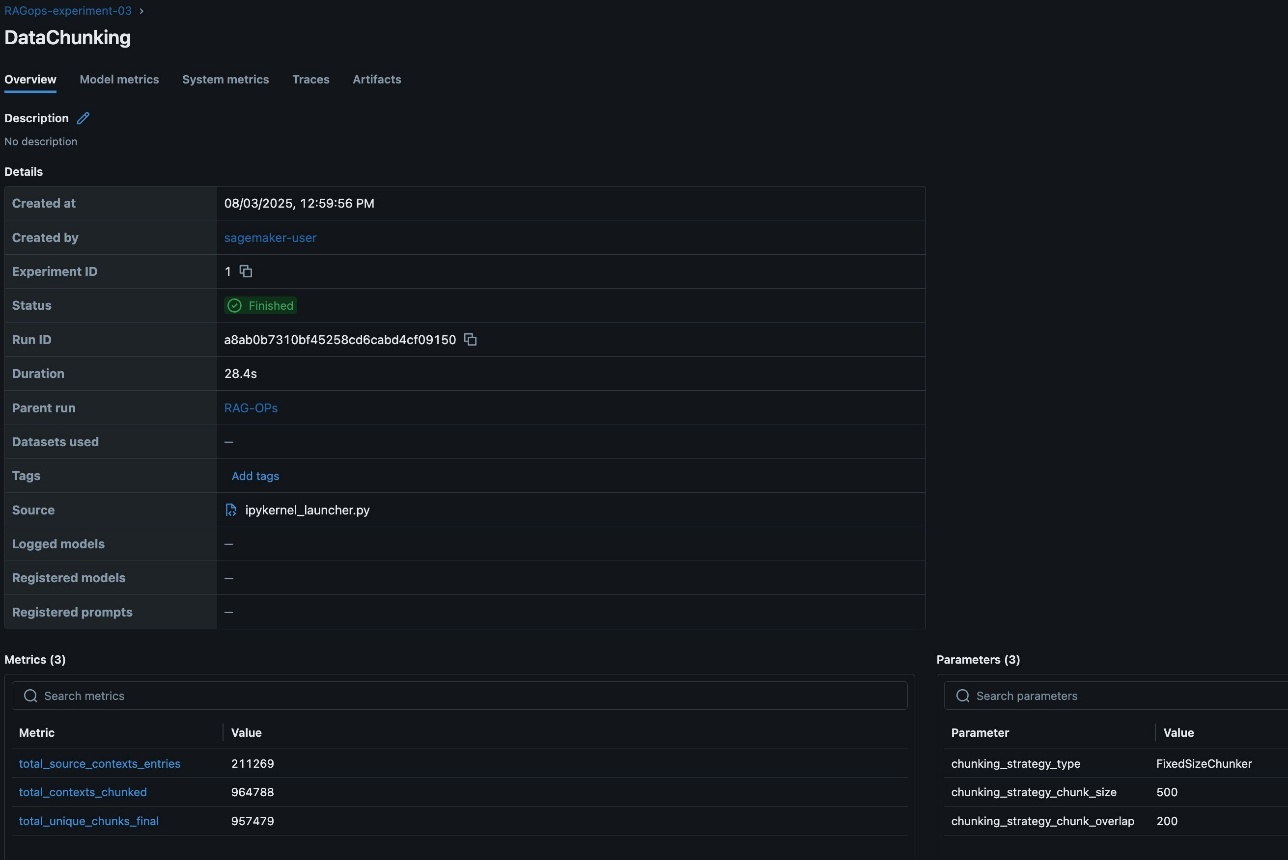
Data chunking
After data preparation, the next step is to split documents into manageable chunks for efficient embedding and retrieval. This process is pivotal, because the quality and granularity of chunks directly affect the relevance and completeness of answers returned by the RAG system. The RAG workflow in this post supports experimentation and RAG pipeline automation with both fixed-size and recursive chunking strategies for comparison and validations. However, this RAG solution can be expanded to many other chucking techniques.
FixedSizeChunker divides text into uniform chunks with configurable overlap
RecursiveChunker splits text along logical boundaries such as paragraphs or sentences
Tracking detailed chunking metrics such as total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is crucial for understanding how much of the source data is represented, how effectively it is segmented, and whether the chunking approach is yielding the desired coverage and uniqueness. These metrics help diagnose issues like excessive duplication or under-segmentation, which can impact retrieval accuracy and model performance.
Additionally, logging parameters such as chunking_strategy_type (for example, FixedSizeChunker), chunking_strategy_chunk_size (for example, 500 characters), and chunking_strategy_chunk_overlap provide transparency and reproducibility for each experiment. Capturing these details in SageMaker managed MLflow helps teams systematically compare the impact of different chunking configurations, optimize for efficiency and contextual relevance, and maintain a clear audit trail of how chunking decisions evolve over time. The MLflow dashboard makes it straightforward to visualize and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage within the RAG pipeline. The following screenshot shows an example of the experiment run details in MLflow.
After the documents are chunked, the next step is to convert these chunks into vector embeddings using a SageMaker embedding endpoint, after which the embeddings are ingested into a vector database such as OpenSearch Service for fast semantic search. This ingestion phase is crucial because the quality, completeness, and traceability of what enters the vector store directly determine the effectiveness and reliability of downstream retrieval and generation stages.
Tracking ingestion metrics such as the number of documents and chunks ingested provides visibility into pipeline throughput and helps identify bottlenecks or data loss early in the process. Logging detailed parameters, including the embedding model ID, endpoint used, and vector database index, is essential for reproducibility and auditability. This metadata helps teams trace exactly which model and infrastructure were used for each ingestion run, supporting root cause analysis and compliance, especially when working with evolving datasets or sensitive information.
Retrieval and generation
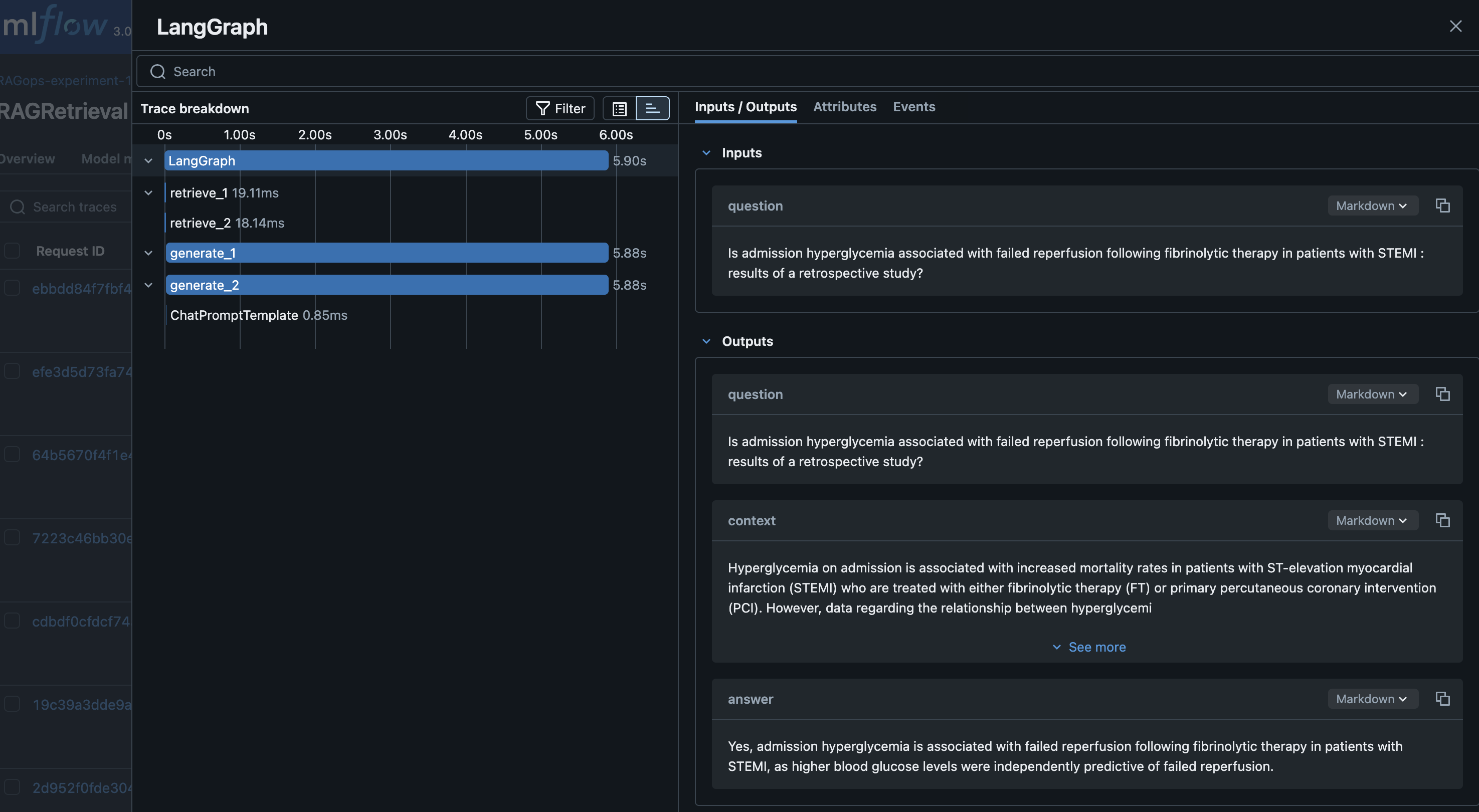
For a given query, we generate an embedding and retrieve the top-k relevant chunks from OpenSearch Service. For answer generation, we use a SageMaker LLM endpoint. The retrieved context and the query are combined into a prompt, and the LLM generates an answer. Finally, we orchestrate retrieval and generation using LangGraph, enabling stateful workflows and advanced tracing:
With the GenerativeAI agent defined with LangGraph framework, the agentic layers are evaluated for each iteration of RAG development, verifying the efficacy of the RAG solution for agentic applications. Each retrieval and generation run is logged to SageMaker managed MLflow, capturing the prompt, generated response, and key metrics and parameters such as retrieval performance, top-k values, and the specific model endpoints used. Tracking these details in MLflow is essential for evaluating the effectiveness of the retrieval stage, making sure the returned documents are relevant and that the generated answers are accurate and complete. It is equally important to track the performance of the vector database during retrieval, including metrics like query latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes sure the RAG pipeline delivers correct and relevant answers and meets production requirements for responsiveness and scalability. The following screenshot shows an example of the Langraph RAG retrieval tracing in MLflow.
RAG Evaluation
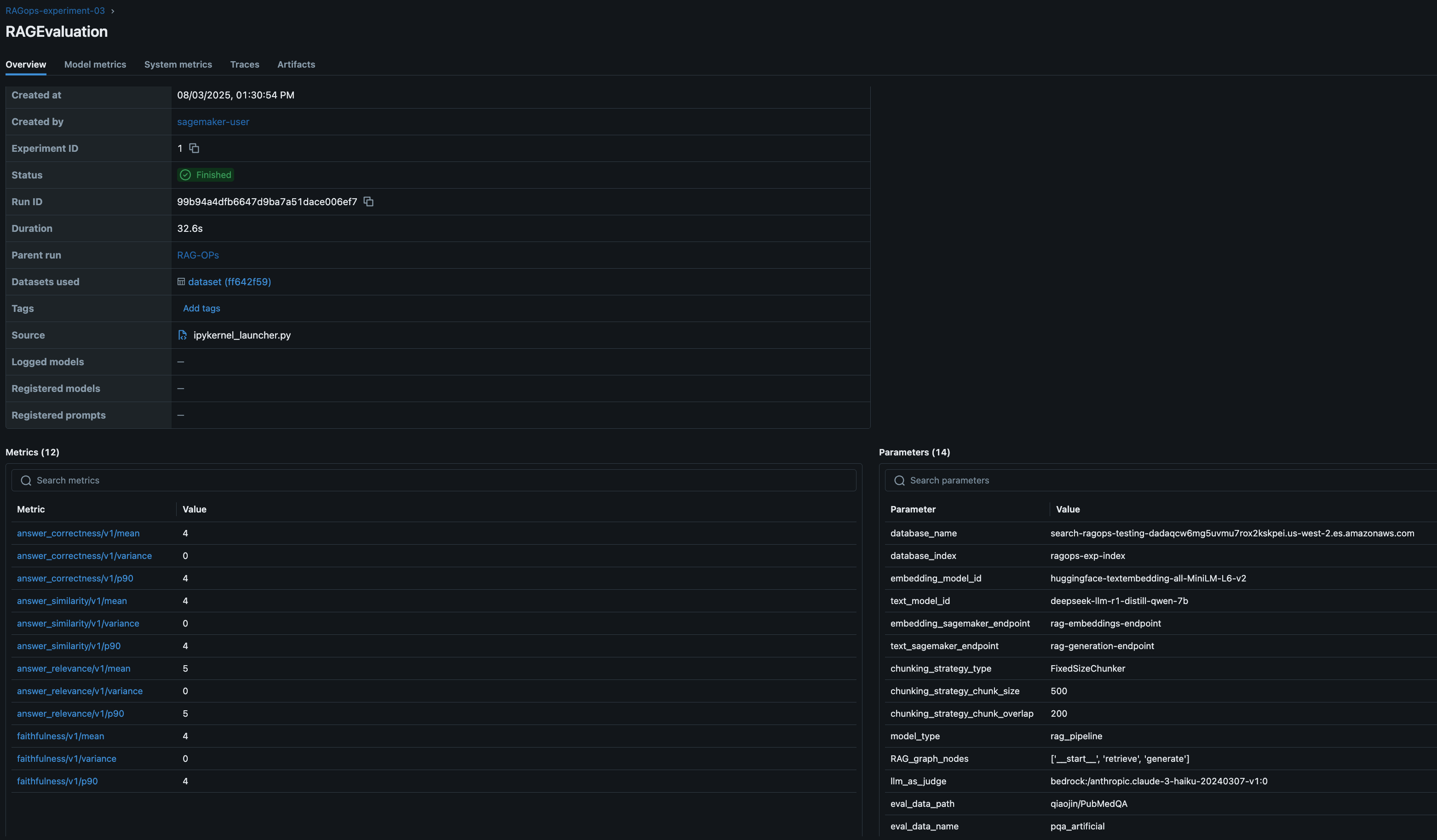
Evaluation is conducted on a curated test set, and results are logged to MLflow for quick comparison and analysis. This helps teams identify the best-performing configurations and iterate toward production-grade solutions. With MLflow you can evaluate the RAG solution with heuristics metrics, content similarity metrics and LLM-as-a-judge. In this post, we evaluate the RAG pipeline using advanced LLM-as-a-judge MLflow metrics (answer similarity, correctness, relevance, faithfulness):
The following screenshot shows an RAG evaluation stage experiment run details in MLflow.
You can use MLflow to log all metrics and parameters, enabling quick comparison of different experiment runs. See the following code for reference:
By using MLflow’s evaluation capabilities (such as mlflow.evaluate()), teams can systematically assess retrieval quality, identify potential gaps or misalignments in chunking or embedding strategies, and compare the performance of different retrieval and generation configurations. MLflow’s flexibility allows for seamless integration with external libraries and evaluation libraries such as RAGAS for comprehensive RAG pipeline assessment. RAGAS is an open source library that provide tools specifically for evaluation of LLM applications and generative AI agents. RAGAS includes the method ragas.evaluate() to run evaluations for LLM agents with the choice of LLM models (evaluators) for scoring the evaluation, and an extensive list of default metrics. To incorporate RAGAS metrics into your MLflow experiments, refer to the following GitHub repository.
Comparing experiments
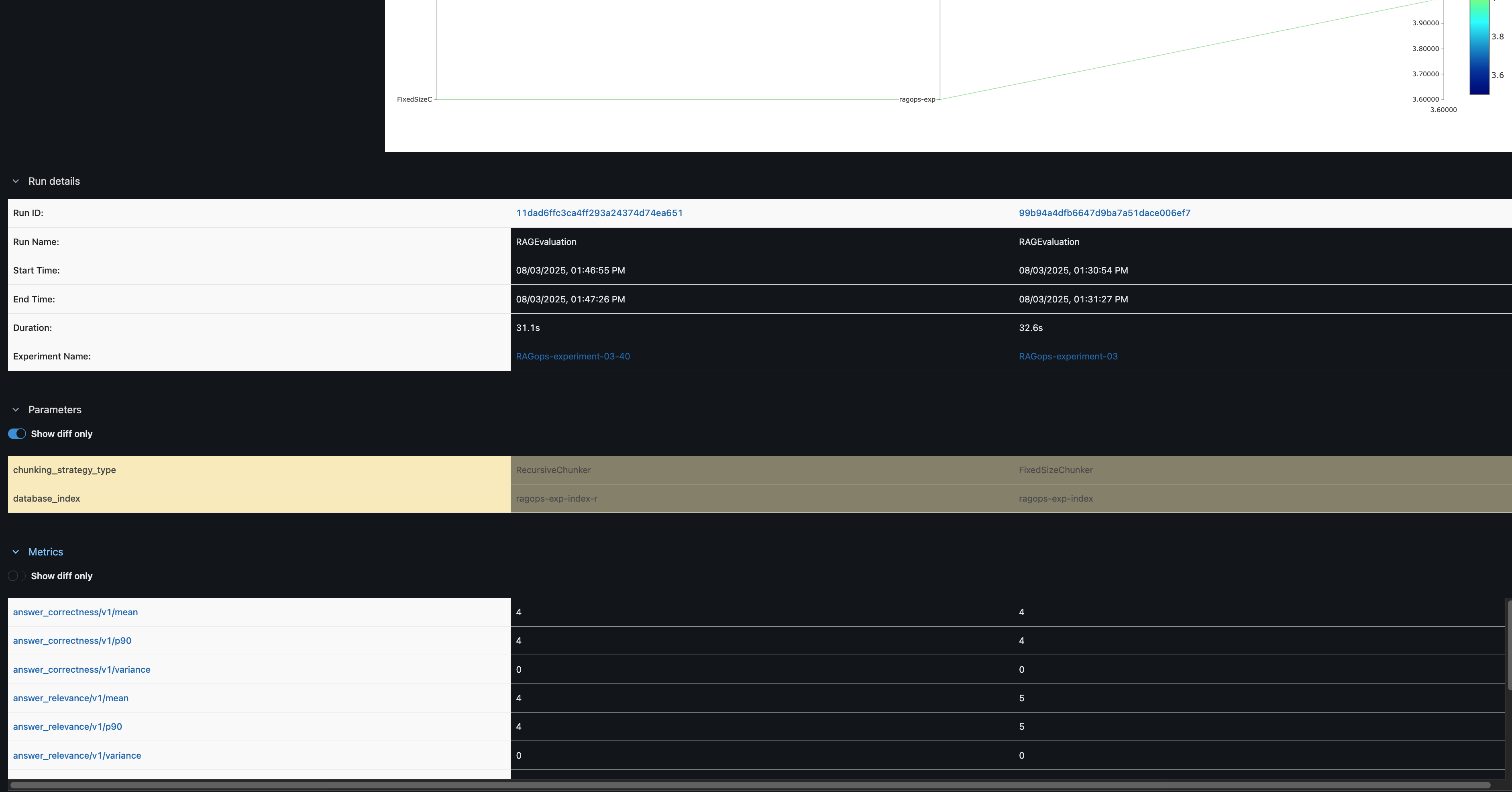
In the MLflow UI, you can compare runs side by side. For example, comparing FixedSizeChunker and RecursiveChunker as shown in the following screenshot reveals differences in metrics such as answer_similarity (a difference of 1 point), providing actionable insights for pipeline optimization.
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing each component of the RAG workflow through SageMaker managed MLflow, the next step is transforming these validated configurations into production-ready automated pipelines. Although MLflow experiments help identify the optimal combination of chunking strategies, embedding models, and retrieval parameters, manually reproducing these configurations across environments can be error-prone and inefficient.
To produce the automated RAG pipeline, we use SageMaker Pipelines, which helps teams codify their experimentally validated RAG workflows into automated, repeatable pipelines that maintain consistency from development through production. By converting the successful MLflow experiments into pipeline definitions, teams can make sure the exact same chunking, embedding, retrieval, and evaluation steps that performed well in testing are reliably reproduced in production environments.
SageMaker Pipelines offers a serverless workflow orchestration for converting experimental notebook code into a production-grade pipeline, versioning and tracking pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow offers dependency management, comprehensive custom testing and validation before production deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you can automate your entire RAG workflow, from data preparation to evaluation, as reusable, parameterized pipeline definitions. This provides the following benefits:
Reproducibility – Pipeline definitions capture all dependencies, configurations, and executions logic in version-controlled code
Parameterization – Key RAG parameters (chunk sizes, model endpoints, retrieval settings) can be quickly modified between runs
Monitoring – Pipeline executions provide detailed logs and metrics for each step
Governance – Built-in lineage tracking supports full audibility of data and model artifacts
Customization – Serverless workflow orchestration is customizable to your unique enterprise landscape, with scalable infrastructure and flexibility with instances optimized for CPU, GPU, or memory-intensive tasks, memory configuration, and concurrency optimization
To implement a RAG workflow in SageMaker pipelines, each major component of the RAG process (data preparation, chunking, ingestion, retrieval and generation, and evaluation) is included in a SageMaker processing job. These jobs are then orchestrated as steps within a pipeline, with data flowing between them, as shown in the following screenshot. This structure allows for modular development, quick debugging, and the ability to reuse components across different pipeline configurations.
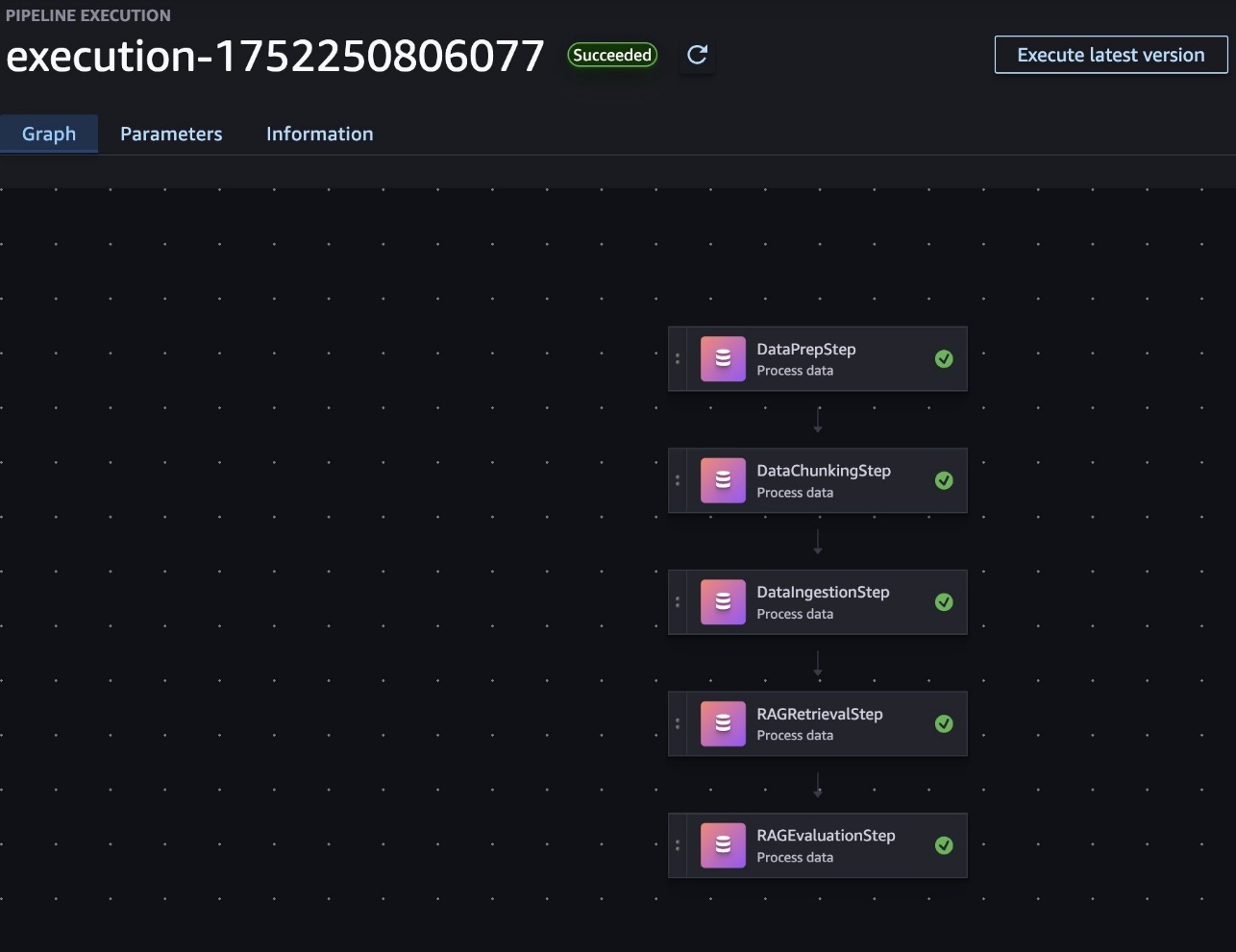
The key RAG configurations are exposed as pipeline parameters, enabling flexible experimentation with minimal code changes. For example, the following code snippets showcase the modifiable parameters for RAG configurations, which can be used as pipeline configurations:
In this post, we provide two agentic RAG pipeline automation approaches to building the SageMaker pipeline, each with own benefits: single-step SageMaker pipelines and multi-step pipelines.
The single-step pipeline approach is designed for simplicity, running the entire RAG workflow as one unified process. This setup is ideal for straightforward or less complex use cases, because it minimizes pipeline management overhead. With fewer steps, the pipeline can start quickly, benefitting from reduced execution times and streamlined development. This makes it a practical option when rapid iteration and ease of use are the primary concerns.
The multi-step pipeline approach is preferred for enterprise scenarios where flexibility and modularity are essential. By breaking down the RAG process into distinct, manageable stages, organizations gain the ability to customize, swap, or extend individual components as needs evolve. This design enables plug-and-play adaptability, making it straightforward to reuse or reconfigure pipeline steps for various workflows. Additionally, the multi-step format allows for granular monitoring and troubleshooting at each stage, providing detailed insights into performance and facilitating robust enterprise management. For enterprises seeking maximum flexibility and the ability to tailor automation to unique requirements, the multi-step pipeline approach is the superior choice.
CI/CD for an agentic RAG pipeline
Now we integrate the SageMaker RAG pipeline with CI/CD. CI/CD is important for making a RAG solution enterprise-ready because it provides faster, more reliable, and scalable delivery of AI-powered workflows. Specifically for enterprises, CI/CD pipelines automate the integration, testing, deployment, and monitoring of changes in the RAG system, which brings several key benefits, such as faster and more reliable updates, version control and traceability, consistency across environments, modularity and flexibility for customization, enhanced collaboration and monitoring, risk mitigation, and cost savings. This aligns with general CI/CD benefits in software and AI systems, emphasizing automation, quality assurance, collaboration, and continuous feedback essential to enterprise AI readiness.
When your SageMaker RAG pipeline definition is in place, you can implement robust CI/CD practices by integrating your development workflow and toolsets already enabled at your enterprise. This setup makes it possible to automate code promotion, pipeline deployment, and model experimentation through simple Git triggers, so changes are versioned, tested, and systematically promoted across environments. For demonstration, in this post, we show the CI/CD integration using GitHub Actions and by using GitHub Actions as the CI/CD orchestrator. Each code change, such as refining chunking strategies or updating pipeline steps, triggers an end-to-end automation workflow, as shown in the following screenshot. You can use the same CI/CD pattern with your choice of CI/CD tool instead of GitHub Actions, if needed.
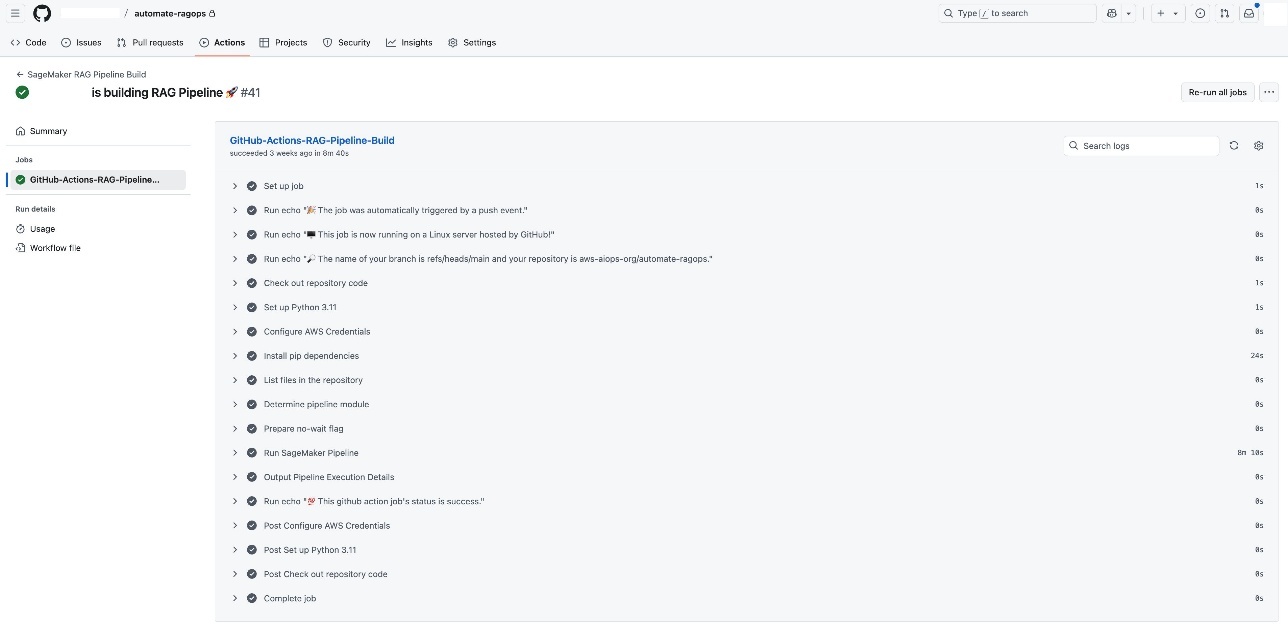
Each GitHub Actions CI/CD execution automatically triggers the SageMaker pipeline (shown in the following screenshot), allowing for seamless scaling of serverless compute infrastructure.
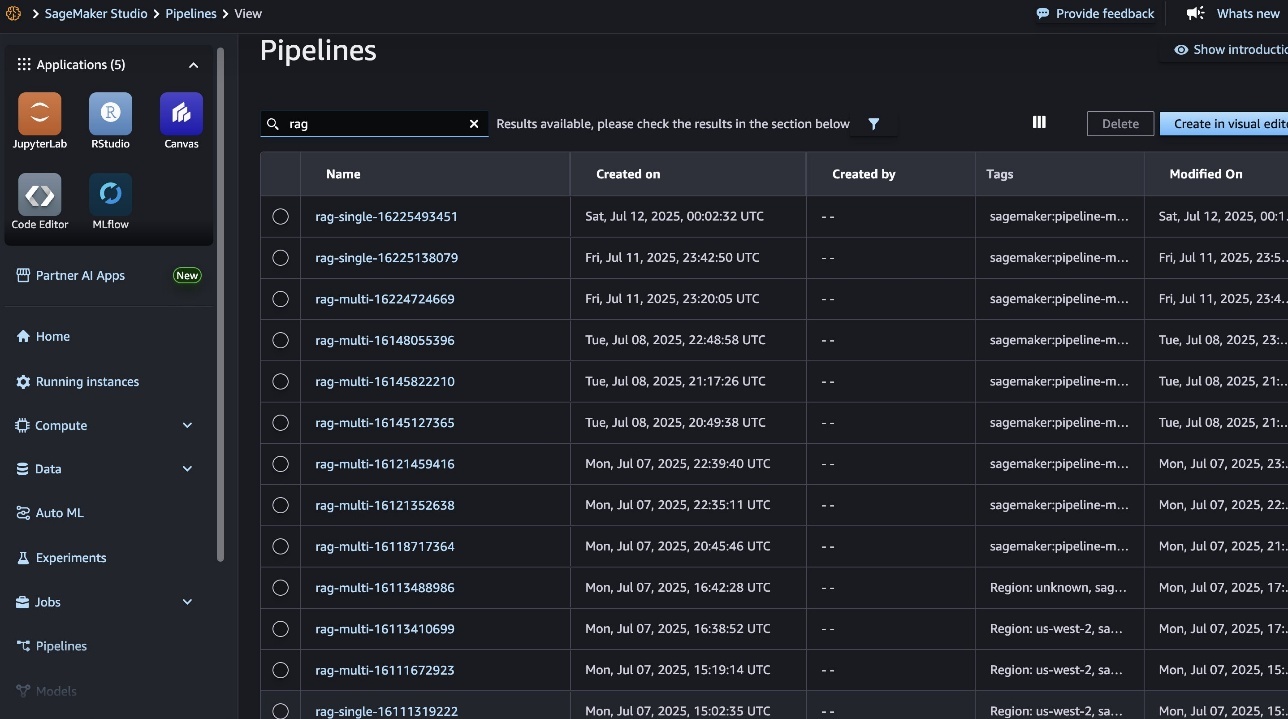
Throughout this cycle, SageMaker managed MLflow records every executed pipeline (shown in the following screenshot), so you can seamlessly review results, compare performance across different pipeline runs, and manage the RAG lifecycle.
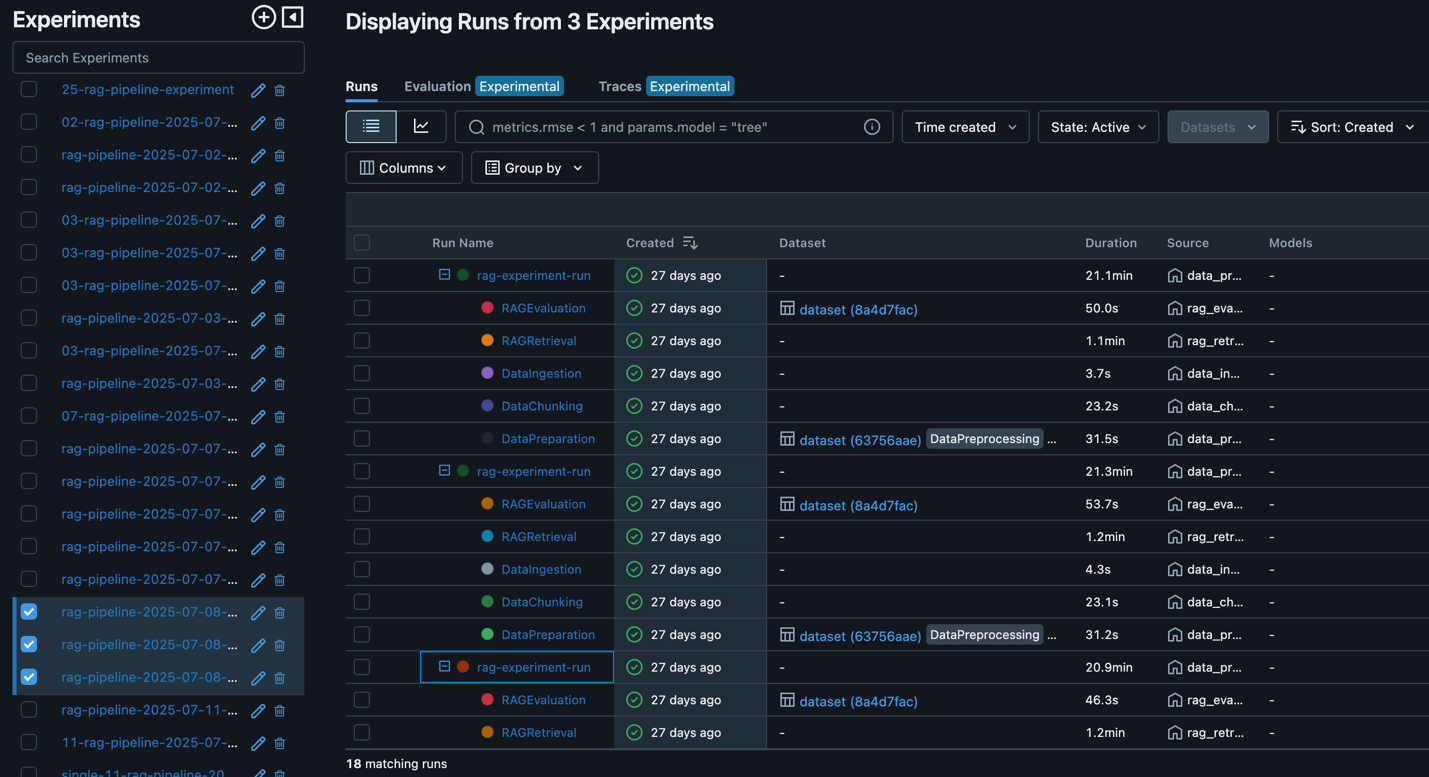
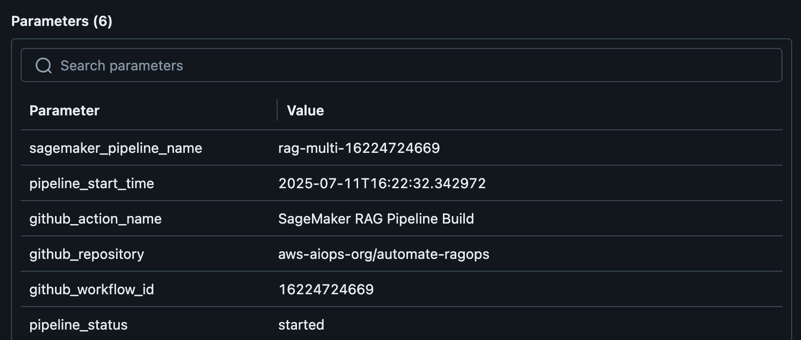
After an optimal RAG pipeline configuration is determined, the new desired configuration (Git version tracking captured in MLflow as shown in the following screenshot) can be promoted to higher stages or environments directly through an automated workflow, minimizing manual intervention and reducing risk.
Clean up
To avoid unnecessary costs, delete resources such as the SageMaker managed MLflow tracking server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is complete. You can visit the SageMaker Studio console to destroy resources that aren’t needed anymore or call appropriate AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you can build, evaluate, and deploy RAG pipelines at scale. This approach provides the following benefits:
Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing manual steps and reducing the risk of human error
Advanced experiment tracking and comparison for different chunking strategies, embedding models, and LLMs, so every configuration is logged, analyzed, and reproducible
Actionable insights from both traditional and LLM-based evaluation metrics, helping teams make data-driven improvements at every stage
Seamless deployment to production environments, with automated promotion of validated pipelines and robust governance throughout the workflow
Automating your RAG pipeline with SageMaker Pipelines brings additional benefits: it enables consistent, version-controlled deployments across environments, supports collaboration through modular, parameterized workflows, and supports full traceability and auditability of data, models, and results. With built-in CI/CD capabilities, you can confidently promote your entire RAG solution from experimentation to production, knowing that each stage meets quality and compliance standards.
Now it’s your turn to operationalize RAG workflows and accelerate your AI initiatives. Explore SageMaker Pipelines and managed MLflow using the solution from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG solutions.
About the authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customers through their AIOps journey across model training, generative AI applications like agents, and scaling generative AI use cases. He also focuses on Go-To-Market strategies, helping AWS build and align products to solve industry challenges in the generative AI space. You can find Sandeep on LinkedIn.
 Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.
Blake Shin is an Associate Specialist Solutions Architect at AWS who enjoys learning about and working with new AI/ML technologies. In his free time, Blake enjoys exploring the city and playing music.