
Amazon SageMaker HyperPod is a purpose-built infrastructure for optimizing foundation model (FM) training and inference at scale. SageMaker HyperPod removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training FMs, reducing training time by up to 40%.
SageMaker HyperPod offers persistent clusters with built-in resiliency, while also offering deep infrastructure control by allowing users to SSH into the underlying Amazon Elastic Compute Cloud (Amazon EC2) instances. It helps efficiently scale model development and deployment tasks such as training, fine-tuning, or inference across a cluster of hundreds or thousands of AI accelerators, while reducing the operational heavy lifting involved in managing such clusters. As AI moves towards deployment adopting to a multitude of domains and use cases, the need for flexibility and control is becoming more pertinent. Large enterprises want to make sure the GPU clusters follow the organization-wide policies and security rules. Mission-critical AI/ML workloads often require specialized environments that align with the organization’s software stack and operational standards.
SageMaker HyperPod supports Amazon Elastic Kubernetes Service (Amazon EKS) and offers two new features that enhance this control and flexibility to enable production deployment of large-scale ML workloads:
Continuous provisioning – SageMaker HyperPod now supports continuous provisioning, which enhances cluster scalability through features like partial provisioning, rolling updates, concurrent scaling operations, and continuous retries when launching and configuring your HyperPod cluster.
Custom AMIs – You can now use custom Amazon Machine Images (AMIs), which enables the preconfiguration of software stacks, security agents, and proprietary dependencies that would otherwise require complex post-launch bootstrapping. Customers can create custom AMIs using the HyperPod public AMI as a base and install additional software required to meet their organization’s specific security and compliance requirements.
In this post, we dive deeper into each of these features.
Continuous provisioning
The new continuous provisioning feature in SageMaker HyperPod represents a transformative advancement for organizations running intensive ML workloads, delivering unprecedented flexibility and operational efficiency that accelerates AI innovation. This feature provides the following benefits:
Partial provisioning – SageMaker HyperPod prioritizes delivering the maximum possible number of instances without failure. You can start running your workload while your cluster will attempt to provision the remaining instances.
Concurrent operations – SageMaker HyperPod supports simultaneous scaling and maintenance activities (such as scale up, scale down, and patching) on a single instance group waiting for previous operations to complete.
Continuous retries – SageMaker HyperPod persistently attempts to fulfill the user’s request until it encounters a NonRecoverable error from where recovery is not possible.
Increased customer visibility – SageMaker HyperPod maps customer-initiated and service-initiated operations to structured activity streams, providing real-time status updates and detailed progress tracking.
For ML teams facing tight deadlines and resource constraints, this means dramatically reduced wait times and the ability to begin model training and deployment with whatever computing power is immediately available, while the system works diligently in the background to provision remaining requested resources.
Implement continuous provisioning in a SageMaker HyperPod cluster
The architecture introduces an intuitive yet powerful parameter that puts scaling strategy control directly in your hands: –node-provisioning-mode. Continuous provisioning maximizes resource utilization and operational agility.
The following code creates a cluster with one instance group and continuous provisioning mode enabled using –node-provisioning-mode:
Additional features are released with continuous provisioning:
Cron job scheduling for instance group software updates:
Rolling updates with safety measures. With rolling deployment, HyperPod gradually shifts traffic from your old fleet to a new fleet. If there is an issue during deployment, it should not affect the whole cluster.
Batch add nodes (add nodes to specific instance groups):
Batch delete nodes (remove specific nodes by ID):
Enable Training Plan capacity for instance provisioning by adding the TrainingPlanArn parameter during instance group creation:
Cluster event observability:
Custom AMIs
To reduce operational overhead, nodes in a SageMaker HyperPod cluster are launched with the AWS Deep Learning AMIs (DLAMIs). AWS DLAMIs are pre-built AMIs that are optimized for running deep learning workloads on EC2 instances. They come pre-installed with popular deep learning frameworks, libraries, and tools to make it straightforward to get started with training and deploying deep learning models.
The new custom AMI feature of SageMaker HyperPod unlocks even greater value for enterprise customers by delivering the granular control and operational excellence you need to accelerate AI initiatives while maintaining security standards. It seamlessly bridges high-performance computing requirements with enterprise-grade security and operational excellence.
Organizations can now build customized AMIs using SageMaker HyperPod performance-tuned public AMIs as a foundation; teams can pre-install security agents, compliance tools, proprietary software, and specialized libraries directly into optimized images.
This feature offers the following benefits:
It accelerates time-to-value by minimizing runtime installation delays and reducing cluster initialization time through pre-built configurations.
From a security standpoint, it enables enterprise-grade centralized control, so security teams can maintain complete oversight while meeting their compliance requirements.
Operationally, the feature promotes excellence through standardized, reproducible environments using version-controlled AMIs, while providing seamless integration with existing workflows.
The following sections outline a step-by-step approach to build your own AMI and use it on your SageMaker HyperPod cluster.
Select and obtain your SageMaker HyperPod base AMI
You can choose from two options to retrieve the SageMaker HyperPod base AMI. To use the Amazon EC2 console, complete the following steps:
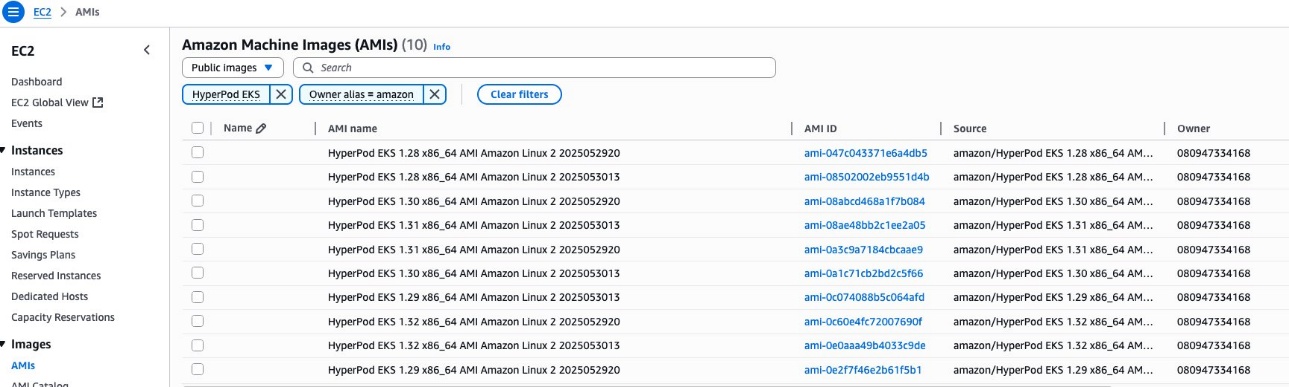
On the Amazon EC2 console, choose AMIs under Images in the navigation pane.
Choose Public images as the image type and set the Owner alias filter to Amazon.
Search for AMIs prefixed with HyperPod EKS.
Choose the appropriate AMI (preferably the latest).
Alternatively, you can use the Amazon Command Line Interface (AWS CLI) with AWS Systems Manager to fetch the latest SageMaker HyperPod base AMI:
Build your custom AMI
After you select a SageMaker HyperPod public AMI, use that as the base AMI to build your own custom AMI using one of the following methods. This is not an exhaustive list for building AMIs; you can use your preferred method. SageMaker HyperPod does not have any strong recommendations.
Amazon EC2 console – Choose your customized EC2 instance, then choose Action, Image and Templates, Create Image.
AWS CLI – Use the aws ec2 create-image command.
HashiCorp Packer – Packer is an open source tool from HashiCorp that you can use to create identical machine images for multiple platforms from a single source configuration. It supports creating AMIs for AWS, as well as images for other cloud providers and virtualization platforms.
EC2 Image Builder – EC2 Image Builder is a fully managed AWS service that makes it straightforward to automate the creation, maintenance, validation, sharing, and deployment of Linux or Windows Server images.
Set up the required permissions
Before you start using custom AMIs, confirm you have the required AWS Identity and Access Management (IAM) policies configured. Make sure you add the following policies to your ClusterAdmin user permissions (IAM policy):
Run cluster management operations
To create a cluster with a custom AMI, use the aws sagemaker create-cluster command. Specify your custom AMI in the ImageId parameter, and include other required cluster configurations:
Scale up an instance group with the following code:
Add an instance group with the following code:
Considerations
When using custom AMIs with your cluster, be aware of the following requirements and limitations:
Snapshot support – Custom AMIs must contain only the root snapshot. Additional snapshots are not supported and will cause cluster creation or update operations to fail with a validation exception if the AMI contains additional snapshots beyond the root volume.
Patching – ImageId in update-cluster is immutable. For patching existing instance groups, you must use UpdateClusterSoftware with ImageId.
AMI versions and deprecation – The public AMI releases page talks about the public AMI versions and deprecation status. Customers are expected to monitor this page for AMI vulnerabilities and deprecation status and patch cluster with updated custom AMI.
Clean up
To clean up your resources to avoid incurring more charges, complete the following steps:
Delete your SageMaker HyperPod cluster.
If you created the networking stack from the SageMaker HyperPod workshop, delete the stack as well to clean up the virtual private cloud (VPC) resources and the FSx for Lustre volume.
Conclusion
In this post, we introduced three features in SageMaker HyperPod that enhance scalability and customizability for ML infrastructure. Continuous provisioning offers flexible resource provisioning to help you start training and deploying your models faster and manage your cluster more efficiently. With custom AMIs, you can align your ML environments with organizational security standards and software requirements. To learn more about these features, see:
About the authors
 Mark Vinciguerra is an Associate Specialist Solutions Architect at Amazon Web Services (AWS) based in New York. He focuses on Generative AI training and inference, with the goal of helping customers architect, optimize, and scale their workloads across various AWS services. Prior to AWS, he went to Boston University and graduated with a degree in Computer Engineering. You can connect with him on LinkedIn.
Mark Vinciguerra is an Associate Specialist Solutions Architect at Amazon Web Services (AWS) based in New York. He focuses on Generative AI training and inference, with the goal of helping customers architect, optimize, and scale their workloads across various AWS services. Prior to AWS, he went to Boston University and graduated with a degree in Computer Engineering. You can connect with him on LinkedIn.
 Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on generative AI model training and inference. He partners with top frontier model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
 Monidipa Chakraborty currently serves as a Senior Software Development Engineer at Amazon Web Services (AWS), specifically within the SageMaker HyperPod team. She is committed to assisting customers by designing and implementing robust and scalable systems that demonstrate operational excellence. Bringing nearly a decade of software development experience, Monidipa has contributed to various sectors within Amazon, including Video, Retail, Amazon Go, and AWS SageMaker.
Monidipa Chakraborty currently serves as a Senior Software Development Engineer at Amazon Web Services (AWS), specifically within the SageMaker HyperPod team. She is committed to assisting customers by designing and implementing robust and scalable systems that demonstrate operational excellence. Bringing nearly a decade of software development experience, Monidipa has contributed to various sectors within Amazon, including Video, Retail, Amazon Go, and AWS SageMaker.
 Arun Nagpal is a Sr Technical Account Manager & Enterprise Support Lead at Amazon Web Services (AWS), specializing in driving generative AI and supporting startups through enterprise-wide cloud transformations. He focuses on adopting AI services within AWS and aligning technology strategies with business objectives to achieve impactful results.
Arun Nagpal is a Sr Technical Account Manager & Enterprise Support Lead at Amazon Web Services (AWS), specializing in driving generative AI and supporting startups through enterprise-wide cloud transformations. He focuses on adopting AI services within AWS and aligning technology strategies with business objectives to achieve impactful results.
 Daiming Yang is a technical leader at AWS, working on machine learning infrastructure that enables large-scale training and inference workloads. He has contributed to multiple AWS services and is proficient in various AWS technologies, with expertise in distributed systems, Kubernetes, and cloud-native architecture. Passionate about building reliable, customer-focused solutions, he specializes in transforming complex technical challenges into simple, robust systems that scale globally.
Daiming Yang is a technical leader at AWS, working on machine learning infrastructure that enables large-scale training and inference workloads. He has contributed to multiple AWS services and is proficient in various AWS technologies, with expertise in distributed systems, Kubernetes, and cloud-native architecture. Passionate about building reliable, customer-focused solutions, he specializes in transforming complex technical challenges into simple, robust systems that scale globally.
 Kunal Jha is a Principal Product Manager at AWS, where he focuses on building Amazon SageMaker HyperPod to enable scalable distributed training and fine-tuning of foundation models. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can connect with him on LinkedIn.
Kunal Jha is a Principal Product Manager at AWS, where he focuses on building Amazon SageMaker HyperPod to enable scalable distributed training and fine-tuning of foundation models. In his spare time, Kunal enjoys skiing and exploring the Pacific Northwest. You can connect with him on LinkedIn.
 Sai Kiran Akula is an engineering leader at AWS, working on the HyperPod team focused on improving infrastructure for machine learning training/inference jobs. He has contributed to core AWS services like EC2, ECS, Fargate, and SageMaker partner AI apps. With a background in distributed systems, he focuses on building reliable and scalable solutions across teams.
Sai Kiran Akula is an engineering leader at AWS, working on the HyperPod team focused on improving infrastructure for machine learning training/inference jobs. He has contributed to core AWS services like EC2, ECS, Fargate, and SageMaker partner AI apps. With a background in distributed systems, he focuses on building reliable and scalable solutions across teams.