Creating high-quality audio for video content presents numerous technical and creative challenges, impacting both novices and experienced audio professionals. Producers often grapple with issues like noise management, balancing dialogue with sound effects, meeting budgetary and time constraints, and maintaining creative consistency. Translating artistic vision into a cohesive final product that accurately reflects visual dynamics, acoustic environments, and timing also remains challenging.
To address these challenges, Alibaba’s Tongyi Speech Lab has introduced ThinkSound, a novel open-source multimodal LLM utilizing Chain-of-Thought (CoT) reasoning for advanced audio generation and editing. ThinkSound offers a structured, interactive approach to audio production, specifically tailored for video content. The model, available in three compact sizes – 1.3B, 724M, and 533M parameters – supports video-to-audio generation, text-based audio editing, and interactive audio creation, even on edge devices.
ThinkSound mimics the multi-stage workflow of human sound designers, ensuring generated audio remains contextually accurate, cohesive, and high quality throughout production. The model first analyzes a video’s visual dynamics, logically interprets corresponding acoustic attributes, and then synthesizes contextually appropriate audio.
Through its innovative approach, ThinkSound enables users to create detailed and coherent soundscapes, refine generated audio through intuitive user interactions, and edit specific audio segments using natural language instructions, effectively bridging the gap between creative intention and automated audio production.
Additionally, Alibaba’s research team introduced AudioCoT, a large-scale multimodal dataset featuring audio-specific CoT annotations, enhancing the alignment between visual content, textual descriptions, and sound synthesis.
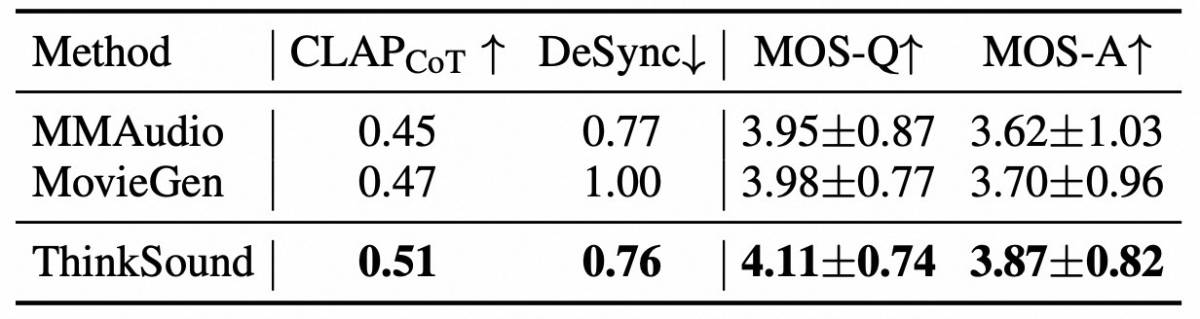
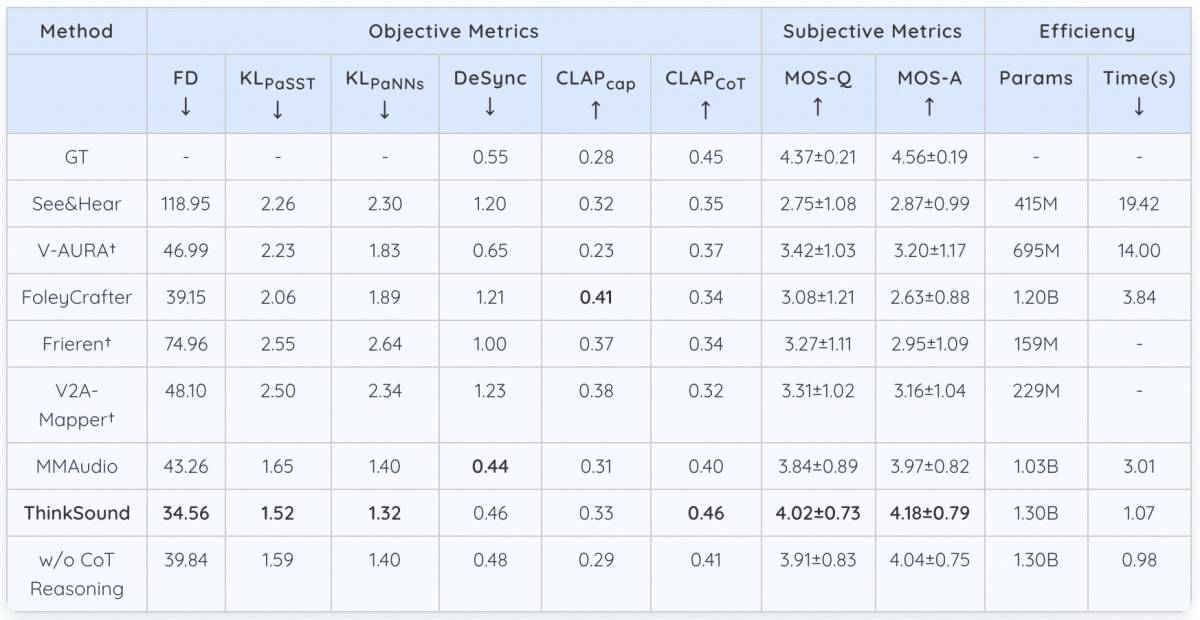
Extensive evaluations have demonstrated that ThinkSound achieves state-of-the-art performance in video-to-audio generation, delivering contextually accurate and precisely timed soundscapes. The model excels in traditional audio quality metrics and CoT-based evaluations. Furthermore, on the MovieGen Audio Bench – a benchmark assessing video audio-generation capabilities – ThinkSound significantly outperforms other leading models.
ThinkSound can seamlessly integrate with various video-generation models to provide realistic voiceovers and soundtracks for synthesized videos. Its sophisticated audio-generation capabilities offer significant potential applications in film and television sound design, audio post-production, and immersive sound experiences for gaming and virtual reality.
ThinkSound is now available open source on Hugging Face, GitHub and Alibaba’s Model Studio.