
As organizations seek to derive greater value from their AWS Support data, operational teams are looking for ways to transform raw support cases and health events into actionable insights. While traditional analytics tools can provide basic reporting capabilities, teams need more sophisticated solutions that can understand and process natural language queries about their operational data. Retrieval-Augmented Generation (RAG) architecture forms the foundation for optimizing large language model outputs by referencing authoritative knowledge bases outside of their training data before generating responses. This architecture uses the power of semantic search and information retrieval capabilities to enhance accuracy.
In our previous blog post, Derive meaningful and actionable operational insights from AWS Using Amazon Q Business, we introduced a RAG-based solution using Amazon Q Business. However, while this approach excels at semantic search, it can face challenges with precise numerical analysis and aggregations. In this post, we address these limitations by showing how you can enhance Amazon Q with custom plugins to improve support analytics and incident response. Our solution combines the strengths of RAG with structured data querying, enabling more accurate answers to analytical questions about your AWS Support data. Detailed deployment instructions for the solution in this post are available in our AWS Samples GitHub repository.
Understanding RAG’s design for analytics
RAG architecture excels at finding relevant information through context-based matching, enabling natural language interactions with external data. However, the fundamental architecture of vector similarity search, which prioritizes semantic relevance over analytical aggregation capabilities, can introduce significant inaccuracies. Let’s examine this limitation with a simple query:
The following is a RAG-only response indicating that the system attempts to piece together information from various documents, reporting 190 cases through potentially hallucinated aggregations.
However, when enhanced with structured data querying capabilities, the same query yields 958 support cases, the accurate count verified against the actual dataset:
This limitation becomes even more apparent with moderately complex queries that require categorical analysis:
The following is a RAG-only response showing limited or inaccurate categorical breakdown:
With structured data querying, we get precise severity distributions:
The gap widens further when dealing with multi-dimensional analysis. Consider the following multi-dimensional query expecting detailed analysis with account-service combinations and temporal patterns.
Query:
Response:
The following is a RAG-only response showing inability to process the same complex query:
These examples demonstrate how RAG alone struggles with analytical queries of increasing complexity, while our plugin-enhanced solution delivers precise, structured analysis at every level. When working with scenarios requiring precise numerical analysis, we can enhance RAG’s capabilities through structured approaches:
Aggregation and pattern analysis: When user prompts include aggregation queries (such as counts, totals, or distributions), they require exact numerical computation through structured querying to provide precise results. Vector similarity search alone cannot guarantee accurate numerical aggregations, making structured metadata querying essential for these analytical use cases.
Context and correlation analysis: External unstructured data requires thoughtful data engineering to extract and maintain structured metadata (such as creation dates, categories, severity levels, and service types). While RAG excels at finding semantically similar content, having well-defined metadata enables precise filtering and querying capabilities. For example, when analyzing system performance issues, structured metadata about incident timing, affected services, and their dependencies enables comprehensive impact analysis through exact querying rather than relying solely on semantic matching.
Enhancing Q Support-Insights with agentic AI
Building on the Q Support-Insights (QSI) solution introduced in Derive meaningful and actionable operational insights from AWS Using Amazon Q Business, we’ll demonstrate how to enhance analytical capabilities through agentic AI by creating custom plugins. This enhancement preserves QSI’s base implementation while adding precise analytical processing through structured metadata querying.
QSI overview
The Amazon Q Support Insights (QSI) solution consists of two main components:
Data collection Pipeline
Support Collector module using AWS Lambda functions
The Support data consists of AWS Support cases, Health events, and Trusted Advisor checks
Amazon EventBridge for automated data collection. The data pipeline enables two synchronization mechanisms:
Real-time case updates: Processes AWS Support cases through event-based triggers (CreateCase, AddCommunicationToCase, ResolveCase, ReopenCase).
Historical and daily sync: Performs initial historical data sync and refreshes AWS Trusted Advisor data daily.
Stores data in JSON format in centralized Amazon Simple Storage Service (Amazon S3) bucket
Supports multi-account data aggregation through AWS Organizations
Amazon Q Business application environment
Amazon Q Business application deployment
Amazon S3 connector for data source integration
Web experience configuration for user interaction
Authentication through AWS IAM Identity Center
Enabling query aggregation with custom plugins for Amazon Q Business
Custom plugins extend Amazon Q Business to combine semantic search with precise analytics capabilities. The following implementation details outline how we’ve augmented the base QSI solution:
Augments QSI’s natural language processing with structured query capabilities
Converts analytical requests into precise Amazon Athena SQL using an Amazon Bedrock large language model (LLM)
Executes queries against structured metadata tables
Provides exact numerical results alongside semantic search responses
Metadata processing
To enable precise querying capabilities, we’ve implemented a robust metadata processing framework that structures and indexes support data:
Using QSI’s existing data collection in Amazon S3
Extracts structured metadata from support cases into two queryable tables
Maintains critical fields like dates, categories, severity levels
Enables precise filtering and aggregation capabilities
Cross-source analysis
The solution enables comprehensive analysis across multiple data sources through intelligent correlation capabilities:
Correlates support cases with health events
Enables comprehensive operational assessment
Supports pattern detection across multiple data sources
Architecture overview
The following illustration shows how the enhanced Amazon Q Business solution integrates custom plugins with the existing QSI architecture. The diagram demonstrates the flow from user query through analytical processing to response generation, highlighting how structured data querying complements the RAG-based semantic search capabilities.
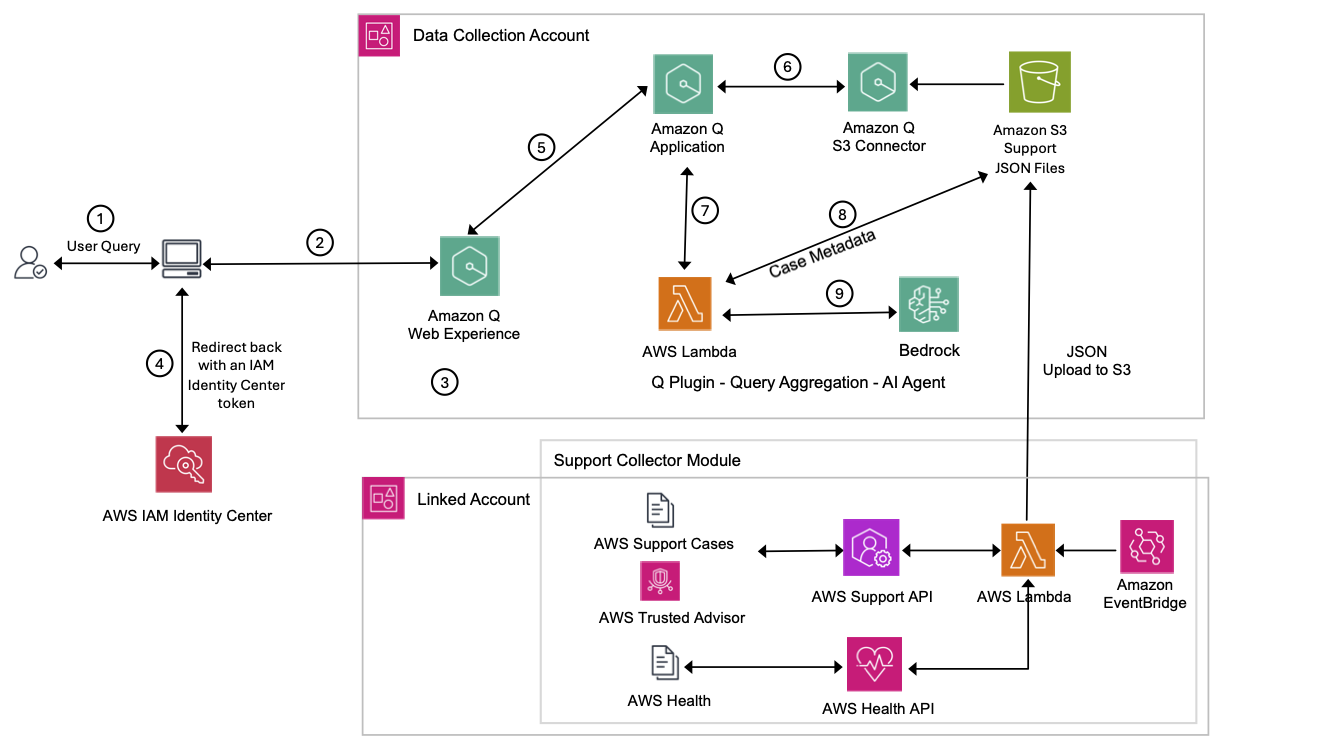
When a user submits an analytical query like Show me OpenSearch case distribution based on severity, the following process occurs:
The custom plugin detects the analytical intent and triggers a Lambda function
The Lambda function uses an Amazon Bedrock LLM to transform the natural language query into precise Athena SQL
The query executes against structured metadata in Athena
Results are synthesized back into natural language and presented alongside traditional RAG responses
This approach enables precise analytics while maintaining the conversational interface users expect.
Implementation example
Here’s a sample interaction demonstrating the enhanced capabilities. Let’s start with a basic query to understand the overall OpenSearch case volume, using structured data querying:
Query:
Response:
Now, using RAG capabilities to analyze unstructured case content for architectural insights:
Query:
Response:
Continuing with RAG-based analysis of case details to evaluate implementation patterns:
Query:
Response:
Finally, here’s another example of structured data analysis with a complex query demonstrating multi-dimensional aggregation capabilities:
Query:
Response:
The response combines precise numerical analysis with semantic understanding, providing actionable insights for operational reviews.
Benefits and impact
This plugin architecture delivers several key improvements:
Precise analytics: Exact counts and distributions replace approximate semantic matching
Contextual analysis: Maintains analytical context across conversation threads
Architectural understanding: Better correlation of related issues through structured analysis
Deploy the Amazon Q Business application
The following is a simplified deployment process. For detailed instructions, see the Amazon Q Business application creation module.
Prerequisites
AWS CloudShell is recommended since, it comes pre-installed with the required libraries and tools. Alternatively, you can use a local machine with the AWS Command Line Interface (AWS CLI) installed and configured with valid credentials.
Two S3 buckets:
Support data bucket for storing AWS Support case data
Resource bucket as temporary storage for Lambda resources for deployment (can be deleted after deployment)
IAM Identity Center instance configured
The solution needs AWS Support data collected using the Support Data Pipeline. You can deploy now and add data later, but functionality depends on data availability in your S3 bucket.
Access to Anthropic’s Cloud 3-5 Sonnet through Amazon Bedrock. See Add or remove access to Amazon Bedrock foundation models
The default database should exist in Athena. If not, you can create one using Athena Query Editor to create the database.
Deployment steps
You can us the following script to deploy the Q solution. No manual steps are needed—the script handles stack creation and configuration automatically.
Clean up
To remove the resources, delete the S3 buckets and CloudFormation stacks. Delete the CloudFormation stacks in the following order:
case-metadata-stack
amazon-q-stack
custom-plugin-stack
Note that this won’t delete the existing S3 buckets, you must manually delete the S3 buckets.
Conclusion
By combining RAG’s semantic understanding with precise analytical capabilities through plugins, we’ve transformed Amazon Q Business into a powerful operational analytics platform. In the examples in this post, you can see how organizations can use this enhancement to derive more accurate and actionable insights from their AWS Support data, supporting better operational decision-making and proactive issue resolution. While demonstrated through support data analytics for operational improvements, these patterns apply across domains that combine structured and unstructured data sources.
Learn more
Explore the Amazon Q documentation to understand more about building custom plugins
Check out these related resources:
For questions and feedback, visit the AWS re:Post or contact AWS Support.
About the authors
 Chitresh Saxena is a Sr. AI/ML specialist TAM specializing in generative AI solutions and dedicated to helping customers successfully adopt AI/ML on AWS. He excels at understanding customer needs and provides technical guidance to build, launch, and scale AI solutions that solve complex business problems.
Chitresh Saxena is a Sr. AI/ML specialist TAM specializing in generative AI solutions and dedicated to helping customers successfully adopt AI/ML on AWS. He excels at understanding customer needs and provides technical guidance to build, launch, and scale AI solutions that solve complex business problems.
 Kevin Morgan is a Sr. Enterprise Support Manager at AWS who helps customers accelerate their cloud adoption journey through hands-on leadership and technical guidance. As a member of the NextGen Developer Experience TFC, he specializes in Builder Experience, CloudOps and DevOps. Outside of work, Kevin enjoys being a Game Master for D&D and is a retro computing enthusiast.
Kevin Morgan is a Sr. Enterprise Support Manager at AWS who helps customers accelerate their cloud adoption journey through hands-on leadership and technical guidance. As a member of the NextGen Developer Experience TFC, he specializes in Builder Experience, CloudOps and DevOps. Outside of work, Kevin enjoys being a Game Master for D&D and is a retro computing enthusiast.