
Quoth Josh Wolfe, well-respected venture capitalist at Lux Capital:

Ha ha ha. But What’s the fuss about?
Apple has a new paper; it’s pretty devastating to LLMs, a powerful followup to one from many of the same authors last year.
There’s actually an interesting weakness in the new argument—which I will get to below—but the overall force of the argument is undeniably powerful. So much so that LLM advocates are already partly conceding the blow while hinting at, or at least hoping for, happier futures ahead.
Wolfe lays out the essentials in a thread:
§
In fairness, the paper both GaryMarcus’d and Subbarao (Rao) Kambhampati’d LLMs.
On the one hand, it echoes and amplifies the training distribution argument that I have been making since 1998: neural networks of various kinds can generalize within a training distribution of data they are exposed to, but their generalizations tend to break down outside that distribution. That was the crux of my 1998 paper skewering multilayer perceptrons, the ancestors of current LLM, by showing out-of-distribution failures on simple math and sentence prediction tasks, and the crux in 2001 of my first book (The Algebraic Mind) which did the same, in a broader way, and central to my first Science paper (a 1999 experiment which demonstrated that seven-month-old infants could extrapolate in a way that then-standard neural networks could not). It was also the central motivation of my 2018 Deep Learning: Critical Appraisal, and my 2022 Deep Learning is Hitting a Wall. I singled it out here last year as the single most important — and important to understand — weakness in LLMs. (As you can see, I have been at this for a while.)
On the other hand it also echoes and amplifies a bunch of arguments that Arizona State University computer scientist Subbarao (Rao) Kambhampati has been making for a few years about so-called “chain of thought” and “reasoning models” and their “reasoning traces” being less than they are cracked up to be. For those not familiar a “chain of thought” is (roughly) the stuff a system says it “reasons” its way to answer, in cases where the system takes multiple steps; “reasoning models” are the latest generation of attempts to rescue the inherent limitations of LLMs, by forcing them to “reason” over time, with a technique called “inference-time compute”. (Regular readers will remember that when Satya Nadella waved the flag of concession in November on pure pretraining scaling – the hypothesis that my deep learning is a hitting a wall paper critique addressed – he suggested we might find a new set of scaling laws for inference time compute.)
Rao, as everyone calls him, has been having none of it, writing a clever series of papers that show, among other things that the chains of thoughts that LLMs produce don’t always correspond to what they actually do. Recently, for example, he observed that people tend to overanthromorphize the reasoning traces of LLMs, calling it “thinking” when it perhaps doesn’t deserve that name. Another of his recent papers showed that even when reasoning traces appear to be correct, final answers sometimes aren’t. Rao was also perhaps the first to show that a “reasoning model”, namely o1, had the kind of problem that Apple documents, ultimately publishing his initial work online here, with followup work here.
The new Apple paper adds to the force of Rao’s critique (and my own) by showing that even the latest of these new-fangled “reasoning models” still —even having scaled beyond o1 — fail to reason beyond the distribution reliably, on a whole bunch of classic problems, like the Tower of Hanoi. For anyone hoping that “reasoning” or “inference time compute” would get LLMs back on track, and take away the pain of m mutiple failures at getting pure scaling to yield something worthy of the name GPT-5, this is bad news.
§
Hanoi is a classic game with three pegs and multiple discs in which you need to move all the discs on the left peg to the right peg, never stacking a larger disc on top of a smaller one.

(You can try a digital version at mathisfun.com.)
If you have never seen it before, it takes a moment or to get the hang of it. (Hint, start with just a few discs).
With practice, a bright (and patient) seven-year-old can do it. And it’s trivial for a computer. Here’s a computer solving the seven-disc version, using an algorithm that any intro computer science student should be able to write:
Claude, on the other hand, can barely do 7 discs, getting less than 80% accuracy, left bottom panel below, and pretty much can’t get 8 correct at all.
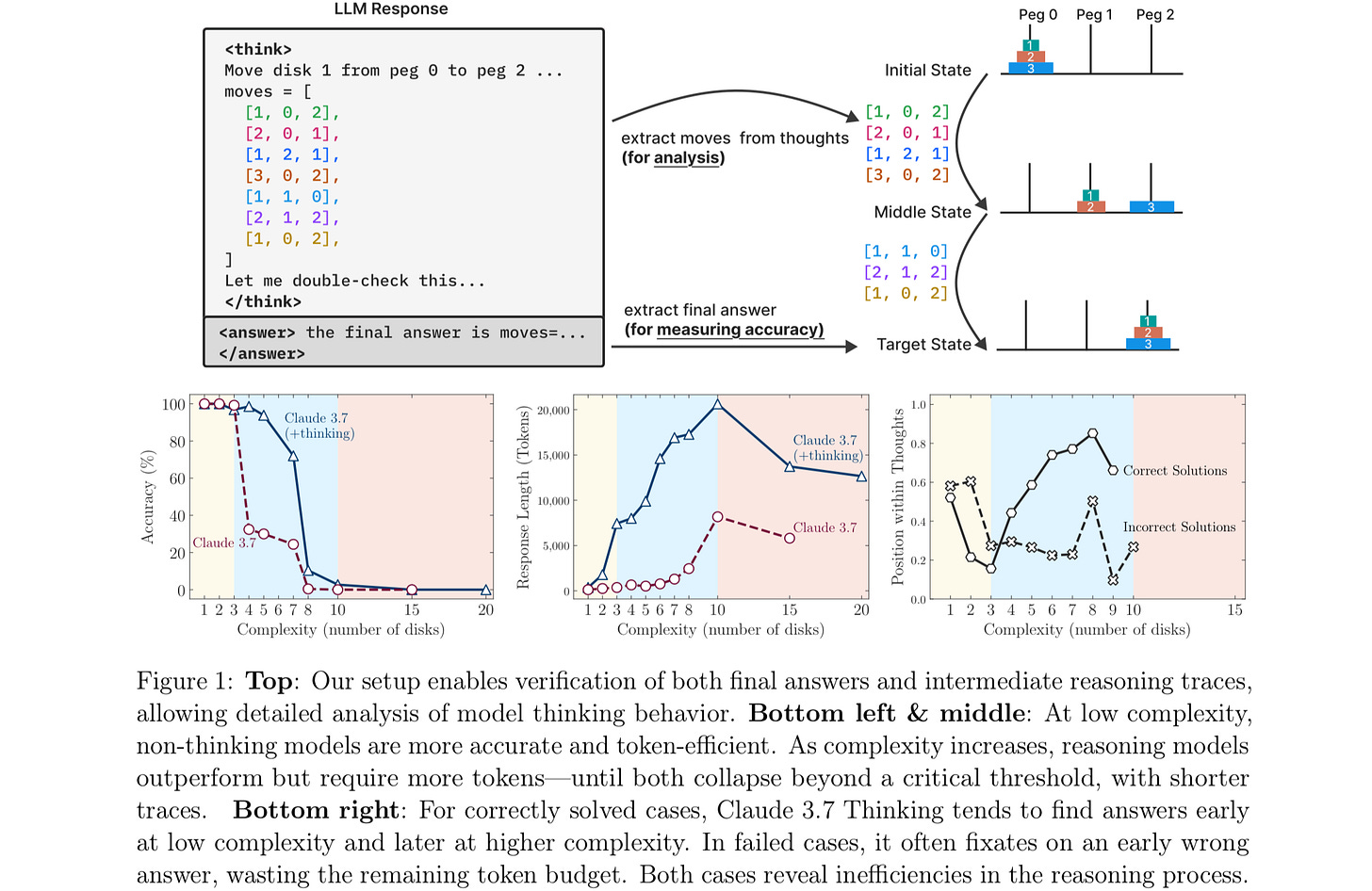
Apple found that the widely praised o3-min (high) was no better (see accuracy, top left panel, legend at bottom), and they found similar results for multiple tasks:
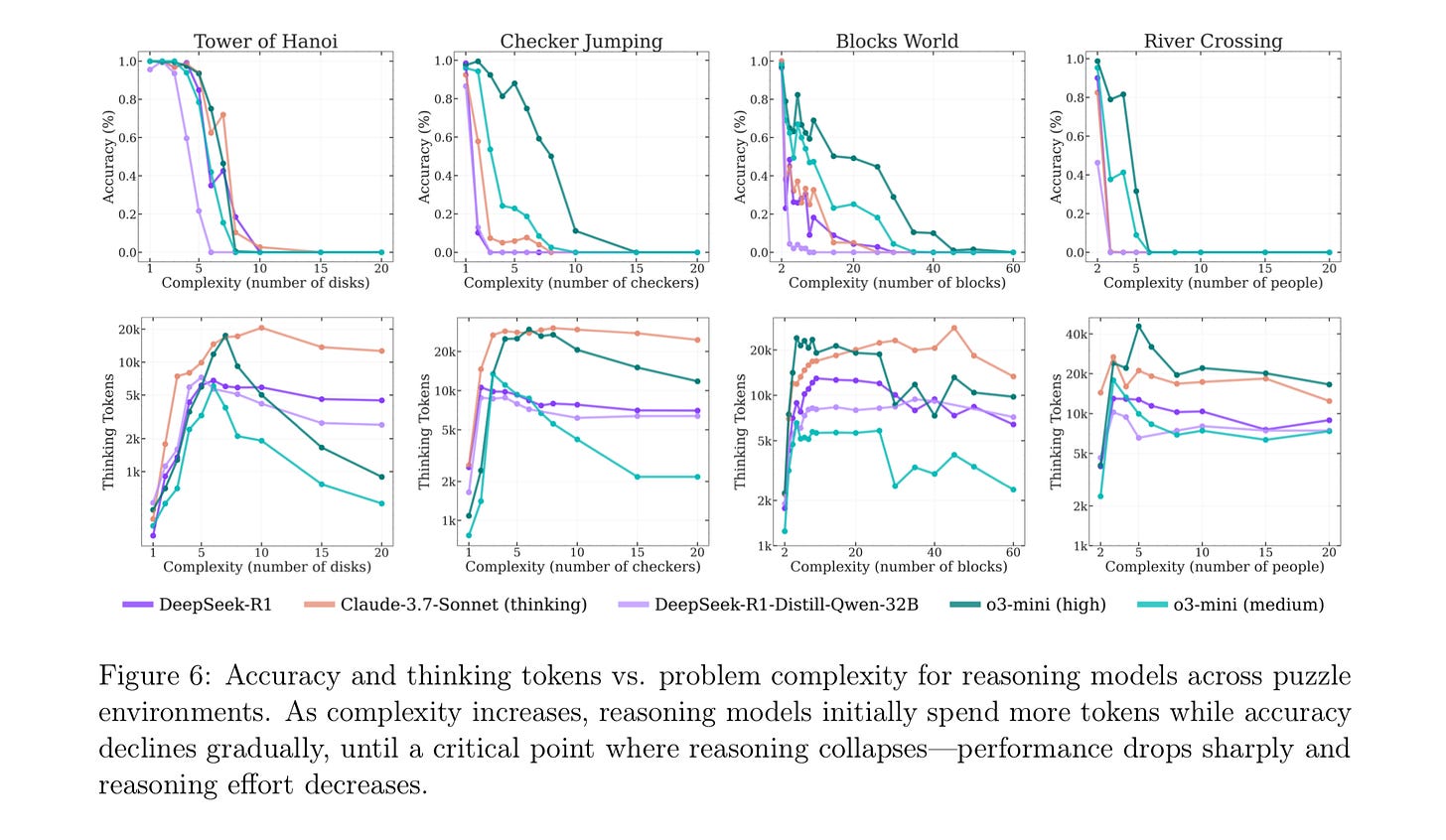
It is truly embarrassing that LLMs cannot reliably solve Hanoi. (Even with many libraries of source code to do it freely available on the web!)
An, as the paper’s co-lead-author Iman Mirzadeh told me via DM,
it’s not just about “solving” the puzzle. In section 4.4 of the paper, we have an experiment where we give the solution algorithm to the model, and all it has to do is follow the steps. Yet, this is not helping their performance at all.
So, our argument is NOT “humans don’t have any limits, but LRMs do, and that’s why they aren’t intelligent”. But based on what we observe from their thoughts, their process is not logical and intelligent.
If you can’t use a billion dollar AI system to solve a problem that Herb Simon one of the actual “godfathers of AI”, current hype aside) solved with AI in 1957, and that first semester AI students solve routinely, the chances that models like Claude or o3 are going to reach AGI seem truly remote.
§
That said, I warned you that there was a weakness in the new paper’s argument. Let’s discuss.
The weakness, which was well-laid out by anonymous account on X (usually not the source of good arguments) was this: (ordinary) humans actually have a bunch of (well-known) limits that parallel what the Apple team discovered. Many (not all) humans screw up on versions of the Tower of Hanoi with 8 discs.
But look, that’s why we invented computers and for that matter calculators: to compute solutions large, tedious problems reliably. AGI shouldn’t be about perfectly replicating a human, it should (as I have often said) be about combining the best of both worlds, human adaptiveness with computational brute force and reliability. We don’t want an “AGI” that fails to “carry the one” in basic arithmetic just because sometimes humans do. And good luck getting to “alignment” or “safety” without reliabilty.
The vision of AGI I have always had is one that combines the strengths of humans with the strength of machines, overcoming the weaknesses of humans. I am not interested in a “AGI” that can’t do arithmetic, and I certainly wouldn’t want to entrust global infrastructure or the future of humanity to such a system.
Whenever people ask me why I (contrary to widespread myth) actually like AI, and think that AI (though not GenAI) may ultimately be of great benefit to humanity, I invariably point to the advances in science and technology we might make if we could combine the causal reasoning abilities of our best scientists with the sheer compute power of modern digital computers.
We are not going to be “extract the light cone” of the earth or “solve physics” [whatever those Altman claims even mean] with systems that can’t play Tower of Hanoi on a tower of 8 pegs. [Aside from this, models like o3 actually hallucinate a bunch more than attentive humans, struggle heavily with drawing reliable diagrams, etc; they happen to share a few weakness with humans, but on a bunch of dimensions they actually fall short.]
And humans, to the extent that they fail, often fail because of a lack of memory; LLMs, with gigabytes of memory, shouldn’t have the same excuse.
§
What the Apple paper shows, most fundamentally, regardless of how you define AGI, is that LLMs are no substitute for good well-specified conventional algorithms. (They also can’t play chess as well as conventional algorithms, can’t fold proteins like special-purpose neurosymbolic hybrids, can’t run databases as well as conventional databases, etc.)
In the best case (not always reached) they can write python code, supplementing their own weaknesses with outside symbolic code, but even this is not reliable. What this means for business and society is that you can’t simply drop o3 or Claude into some complex problem and expect it to work reliably.
Worse, as the latest Apple papers shows, LLMs may well work on your easy test set (like Hanoi with 4 discs) and seduce you into thinking it has built a proper, generalizable solution when it does not.
At least for the next decade, LLMs (with and without inference time “reasoning”) will continue have their uses, especially for coding and brainstorming and writing. And as Rao told me in a message this morning, “the fact that LLMs/LRMs don’t reliably learn any single underlying algorithm is not a complete deal killer on their use. I think of LRMs basically making learning to approximate the unfolding of an algorithm over increasing inference lengths.” In some contexts that will be perfectly fine (in others not so much).
But anybody who thinks LLMs are a direct route to the sort AGI that could fundamentally transform society for the good is kidding themselves. This does not mean that the field of neural networks is dead, or that deep learning is dead. LLMs are just one form of deep learning, and maybe others — especially those that play nicer with symbols – will eventually thrive. Time will tell. But this particular approach has limits that are clearer by the day.
§
I have said it before, and I will say it again:

Gary Marcus never thought he would live to become a verb. For an entertaining definition of that verb, follow this link.