
Every day, countless videos are uploaded and processed online, putting enormous strain on computational resources. The problem isn’t just the sheer volume of data—it’s how this data is structured. Videos consist of raw pixel data, where neighboring pixels often store nearly identical information. This redundancy wastes resources, making it harder for systems to process visual content effectively and efficiently.
To tackle this, we’ve developed a new approach to compress visual data into a more compact and manageable form. In our paper “VidTok: A Versatile and Open-Source Video Tokenizer,” we introduce a method that converts video data into smaller, structured units, or tokens. This technique provides researchers and developers in visual world modeling—a field dedicated to teaching machines to interpret images and videos—with a flexible and efficient tool for advancing their work.
How VidTok works
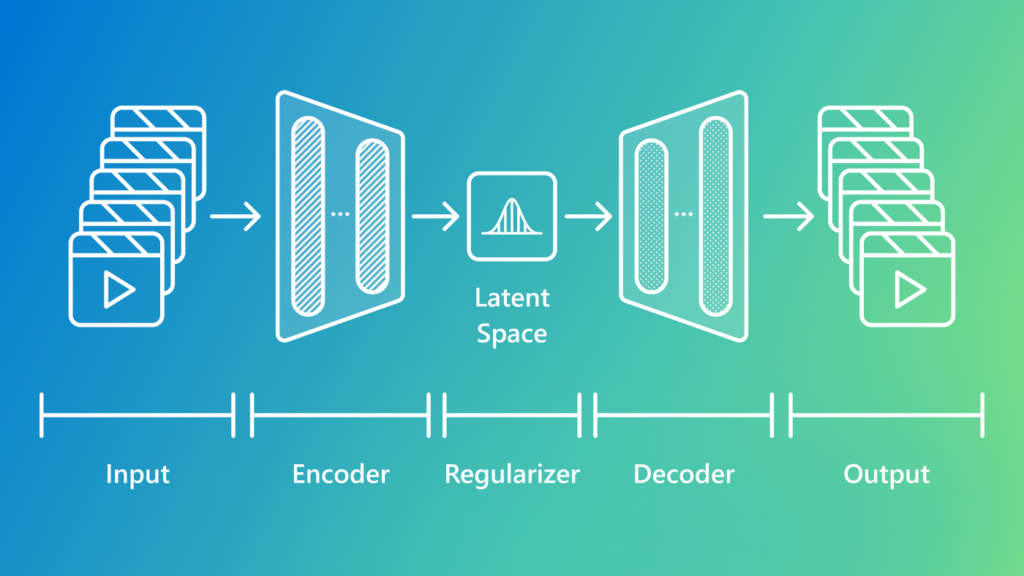
VidTok is a technique that converts raw video footage into a format that AI can easily work with and understand, a process called video tokenization. This process converts complex visual information into compact, structured tokens, as shown in Figure 1.
By simplifying videos into manageable chunks, VidTok can enable AI systems to learn from, analyze, and generate video content more efficiently. VidTok offers several potential advantages over previous solutions:
Supports both discrete and continuous tokens. Not all AI models use the same “language” for video generation. Some perform best with continuous tokens—ideal for high-quality diffusion models—while others rely on discrete tokens, which are better suited for step-by-step generation, like language models for video. VidTok is a tokenizer that has demonstrated seamless support for both, making it adaptable across a range of AI applications.
Operates in both causal and noncausal modes. In some scenarios, video understanding depends solely on past frames (causal), while in others, it benefits from access to both past and future frames (noncausal). VidTok can accommodate both modes, making it suitable for real-time use cases like robotics and video streaming, as well as for high-quality offline video generation.
Efficient training with high performance. AI-powered video generation typically requires substantial computational resources. VidTok can reduce training costs by half through a two-stage training process—delivering high performance and lowering costs.
on-demand event
Microsoft Research Forum Episode 4
Learn about the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization.
Architecture
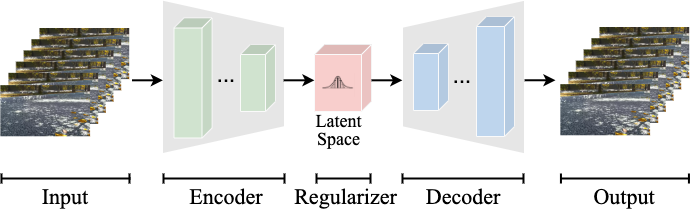
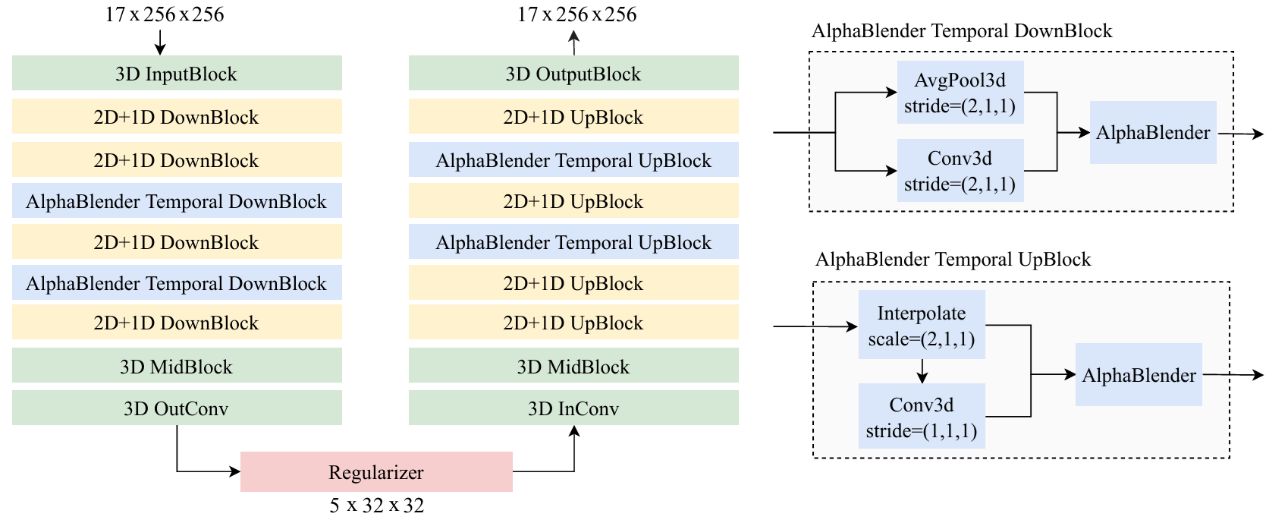
The VidTok framework builds on a classic 3D encoder-decoder structure but introduces 2D and 1D processing techniques to handle spatial and temporal information more efficiently. Because 3D architectures are computationally intensive, VidTok combines them with less resource-intensive 2D and 1D methods to reduce computational costs while maintaining video quality.
Spatial processing. Rather than treating video frames solely as 3D volumes, VidTok applies 2D convolutions—pattern-recognition operations commonly used in image processing—to handle spatial information within each frame more efficiently.
Temporal processing. To model motion over time, VidTok introduces the AlphaBlender operator, which blends frames smoothly using a learnable parameter. Combined with 1D convolutions—similar operations applied over sequences—this approach captures temporal dynamics without abrupt transitions.
Figure 2 illustrates VidTok’s architecture in detail.
Quantization
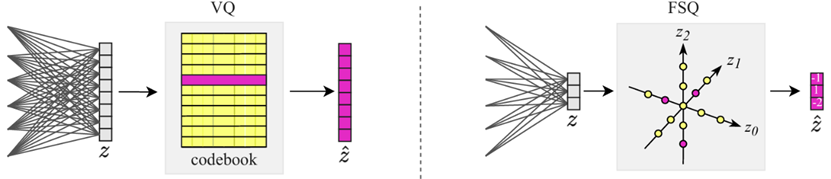
To efficiently compress video data, AI systems often use quantization to reduce the amount of information that needs to be stored or transmitted. A traditional method for doing this is vector quantization (VQ), which groups values together and matches them to a fixed set of patterns (known as a codebook). However, this can lead to an inefficient use of patterns and lower video quality.
For VidTok, we use an approach called finite scalar quantization (FSQ). Instead of grouping values, FSQ treats each value separately. This makes the compression process more flexible and accurate, helping preserve video quality while keeping the file size small. Figure 3 shows the difference between the VQ and FSQ approaches.
Training
Training video tokenizers requires significant computing power. VidTok uses a two-stage process:
It first trains the full model on low-resolution videos.
Then, it fine-tunes only the decoder using high-resolution videos.
This approach cuts training costs in half—from 3,072 to 1,536 GPU hours—while maintaining video quality. Older tokenizers, trained on full-resolution videos from the start, were slower and more computationally intensive.
VidTok’s method allows the model to quickly adapt to new types of videos without affecting its token distribution. Additionally, it trains on lower-frame-rate data to better capture motion, improving how it represents movement in videos.
Evaluating VidTok
VidTok’s performance evaluation using the MCL-JCV benchmark—a comprehensive video quality assessment dataset—and an internal dataset demonstrates its superiority over existing state-of-the-art models in video tokenization. The assessment, which covered approximately 5,000 videos of various types, employed four standard metrics to measure video quality:
Peak Signal-to-Noise Ratio (PSNR)
Structural Similarity Index Measure (SSIM)
Learned Perceptual Image Patch Similarity (LPIPS)
Fréchet Video Distance (FVD)
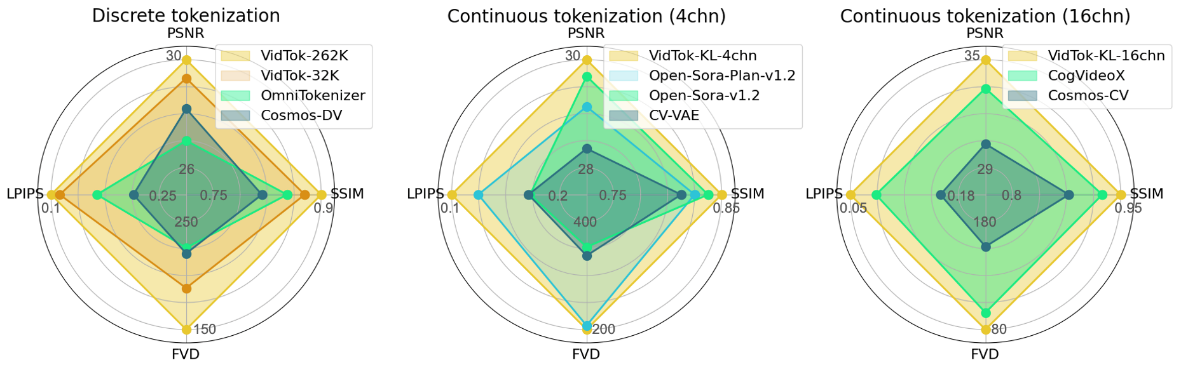
The following table and Figure 4 illustrate VidTok’s performance:
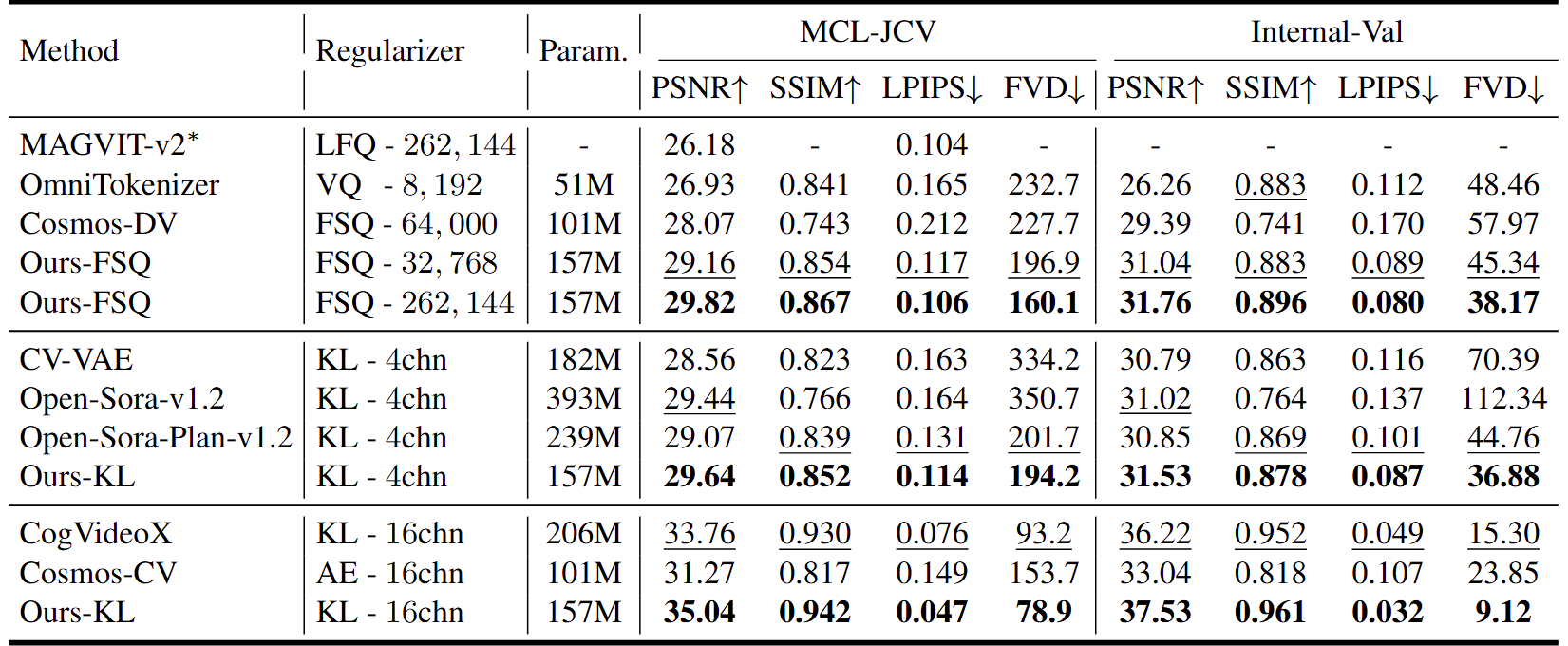
The results indicate that VidTok outperforms existing models in both discrete and continuous tokenization scenarios. This improved performance is achieved even when using a smaller model or a more compact set of reference patterns, highlighting VidTok’s efficiency.
Looking ahead
VidTok represents a significant development in video tokenization and processing. Its innovative architecture and training approach enable improved performance across various video quality metrics, making it a valuable tool for video analysis and compression tasks. Its capacity to model complex visual dynamics could improve the efficiency of video systems by enabling AI processing on more compact units rather than raw pixels.
VidTok serves as a promising foundation for further research in video processing and representation. The code for VidTok is available on GitHub (opens in new tab), and we invite the research community to build on this work and help advance the broader field of video modeling and generation.