
Site reliability engineers (SREs) face an increasingly complex challenge in modern distributed systems. During production incidents, they must rapidly correlate data from multiple sources—logs, metrics, Kubernetes events, and operational runbooks—to identify root causes and implement solutions. Traditional monitoring tools provide raw data but lack the intelligence to synthesize information across these diverse systems, often leaving SREs to manually piece together the story behind system failures.
With a generative AI solution, SREs can ask their infrastructure questions in natural language. For example, they can ask “Why are the payment-service pods crash looping?” or “What’s causing the API latency spike?” and receive comprehensive, actionable insights that combine infrastructure status, log analysis, performance metrics, and step-by-step remediation procedures. This capability transforms incident response from a manual, time-intensive process into a time-efficient, collaborative investigation.
In this post, we demonstrate how to build a multi-agent SRE assistant using Amazon Bedrock AgentCore, LangGraph, and the Model Context Protocol (MCP). This system deploys specialized AI agents that collaborate to provide the deep, contextual intelligence that modern SRE teams need for effective incident response and infrastructure management. We walk you through the complete implementation, from setting up the demo environment to deploying on Amazon Bedrock AgentCore Runtime for production use.
Solution overview
This solution uses a comprehensive multi-agent architecture that addresses the challenges of modern SRE operations through intelligent automation. The solution consists of four specialized AI agents working together under a supervisor agent to provide comprehensive infrastructure analysis and incident response assistance.
The examples in this post use synthetically generated data from our demo environment. The backend servers simulate realistic Kubernetes clusters, application logs, performance metrics, and operational runbooks. In production deployments, these stub servers would be replaced with connections to your actual infrastructure systems, monitoring services, and documentation repositories.
The architecture demonstrates several key capabilities:
Natural language infrastructure queries – You can ask complex questions about your infrastructure in plain English and receive detailed analysis combining data from multiple sources
Multi-agent collaboration – Specialized agents for Kubernetes, logs, metrics, and operational procedures work together to provide comprehensive insights
Real-time data synthesis – Agents access live infrastructure data through standardized APIs and present correlated findings
Automated runbook execution – Agents retrieve and display step-by-step operational procedures for common incident scenarios
Source attribution – Every finding includes explicit source attribution for verification and audit purposes
The following diagram illustrates the solution architecture.
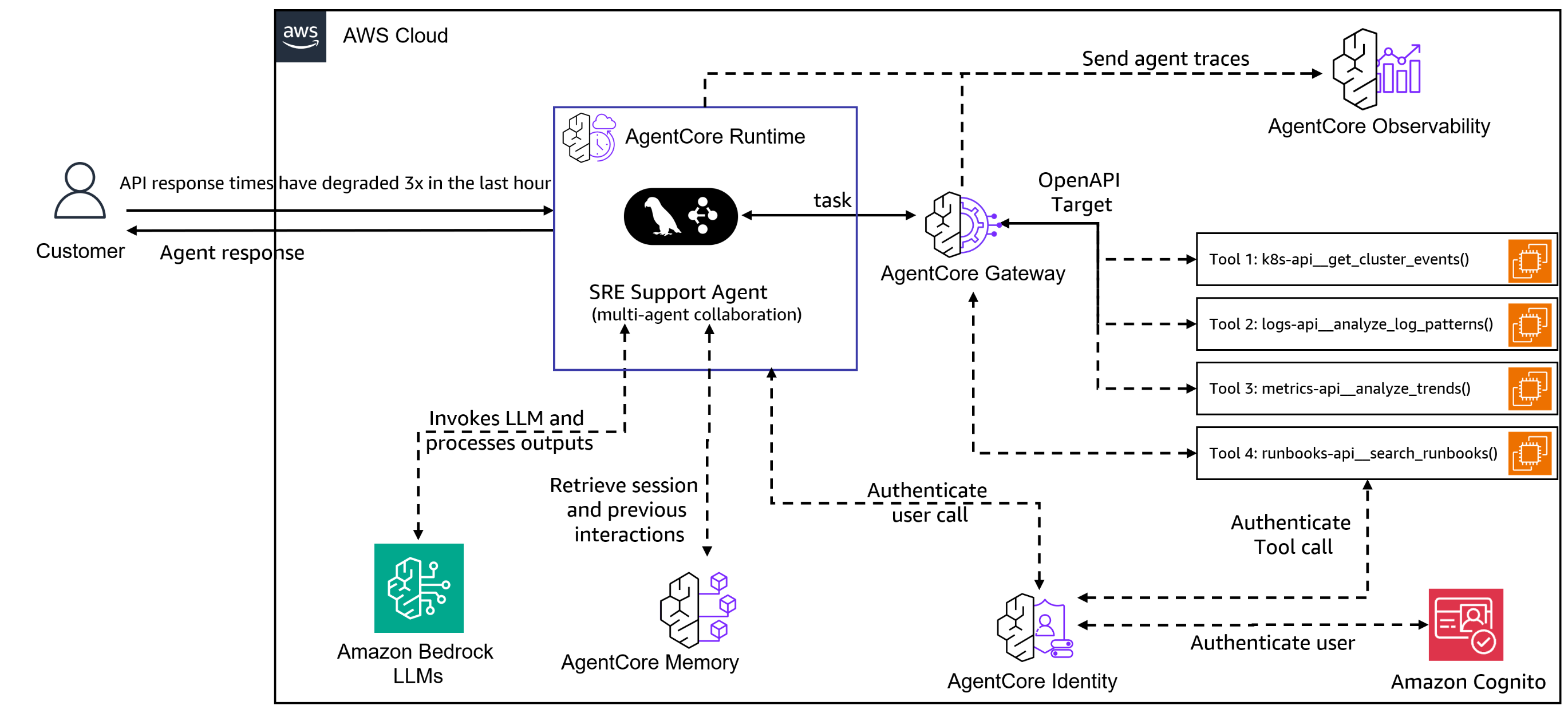
The architecture demonstrates how the SRE support agent integrates seamlessly with Amazon Bedrock AgentCore components:
Customer interface – Receives alerts about degraded API response times and returns comprehensive agent responses
Amazon Bedrock AgentCore Runtime – Manages the execution environment for the multi-agent SRE solution
SRE support agent – Multi-agent collaboration system that processes incidents and orchestrates responses
Amazon Bedrock AgentCore Gateway – Routes requests to specialized tools through OpenAPI interfaces:
Kubernetes API for getting cluster events
Logs API for analyzing log patterns
Metrics API for analyzing performance trends
Runbooks API for searching operational procedures
Amazon Bedrock AgentCore Memory – Stores and retrieves session context and previous interactions for continuity
Amazon Bedrock AgentCore Identity – Handles authentication for tool access using Amazon Cognito integration
Amazon Bedrock AgentCore Observability – Collects and visualizes agent traces for monitoring and debugging
Amazon Bedrock LLMs – Powers the agent intelligence through Anthropic’s Claude large language models (LLMs)
The multi-agent solution uses a supervisor-agent pattern where a central orchestrator coordinates five specialized agents:
Supervisor agent – Analyzes incoming queries and creates investigation plans, routing work to appropriate specialists and aggregating results into comprehensive reports
Kubernetes infrastructure agent – Handles container orchestration and cluster operations, investigating pod failures, deployment issues, resource constraints, and cluster events
Application logs agent – Processes log data to find relevant information, identifies patterns and anomalies, and correlates events across multiple services
Performance metrics agent – Monitors system metrics and identifies performance issues, providing real-time analysis and historical trending
Operational runbooks agent – Provides access to documented procedures, troubleshooting guides, and escalation procedures based on the current situation
Using Amazon Bedrock AgentCore primitives
The solution showcases the power of Amazon Bedrock AgentCore by using multiple core primitives. The solution supports two providers for Anthropic’s LLMs. Amazon Bedrock supports Anthropic’s Claude 3.7 Sonnet for AWS integrated deployments, and Anthropic API supports Anthropic’s Claude 4 Sonnet for direct API access.
The Amazon Bedrock AgentCore Gateway component converts the SRE agent’s backend APIs (Kubernetes, application logs, performance metrics, and operational runbooks) into Model Context Protocol (MCP) tools. This enables agents built with an open-source framework supporting MCP (such as LangGraph in this post) to seamlessly access infrastructure APIs.
Security for the entire solution is provided by Amazon Bedrock AgentCore Identity. It supports ingress authentication for secure access control for agents connecting to the gateway, and egress authentication to manage authentication with backend servers, providing secure API access without hardcoding credentials.
The serverless execution environment for deploying the SRE agent in production is provided by Amazon Bedrock AgentCore Runtime. It automatically scales from zero to handle concurrent incident investigations while maintaining complete session isolation. Amazon Bedrock AgentCore Runtime supports both OAuth and AWS Identity and Access Management (IAM) for agent authentication. Applications that invoke agents must have appropriate IAM permissions and trust policies. For more information, see Identity and access management for Amazon Bedrock AgentCore.
Amazon Bedrock AgentCore Memory transforms the SRE agent from a stateless system into an intelligent learning assistant that personalizes investigations based on user preferences and historical context. The memory component provides three distinct strategies:
User preferences strategy (/sre/users/{user_id}/preferences) – Stores individual user preferences for investigation style, communication channels, escalation procedures, and report formatting. For example, Alice (a technical SRE) receives detailed systematic analysis with troubleshooting steps, whereas Carol (an executive) receives business-focused summaries with impact analysis.
Infrastructure knowledge strategy (/sre/infrastructure/{user_id}/{session_id}) – Accumulates domain expertise across investigations, enabling agents to learn from past discoveries. When the Kubernetes agent identifies a memory leak pattern, this knowledge becomes available for future investigations, enabling faster root cause identification.
Investigation memory strategy (/sre/investigations/{user_id}/{session_id}) – Maintains historical context of past incidents and their resolutions. This enables the solution to suggest proven remediation approaches and avoid anti-patterns that previously failed.
The memory component demonstrates its value through personalized investigations. When both Alice and Carol investigate “API response times have degraded 3x in the last hour,” they receive identical technical findings but completely different presentations.
Alice receives a technical analysis:
Carol receives an executive summary:
Adding observability to the SRE agent
Adding observability to an SRE agent deployed on Amazon Bedrock AgentCore Runtime is straightforward using the Amazon Bedrock AgentCore Observability primitive. This enables comprehensive monitoring through Amazon CloudWatch with metrics, traces, and logs. Setting up observability requires three steps:
Add the OpenTelemetry packages to your pyproject.toml:
Configure observability for your agents to enable metrics in CloudWatch.
Start your container using the opentelemetry-instrument utility to automatically instrument your application.
The following command is added to the Dockerfile for the SRE agent:
As shown in the following screenshot, with observability enabled, you gain visibility into the following:
LLM invocation metrics – Token usage, latency, and model performance across agents
Tool execution traces – Duration and success rates for each MCP tool call
Memory operations – Retrieval patterns and storage efficiency
End-to-end request tracing – Complete request flow from user query to final response
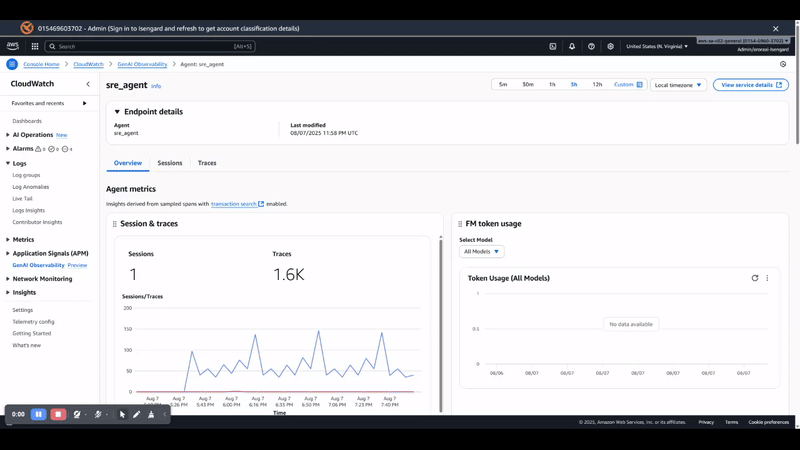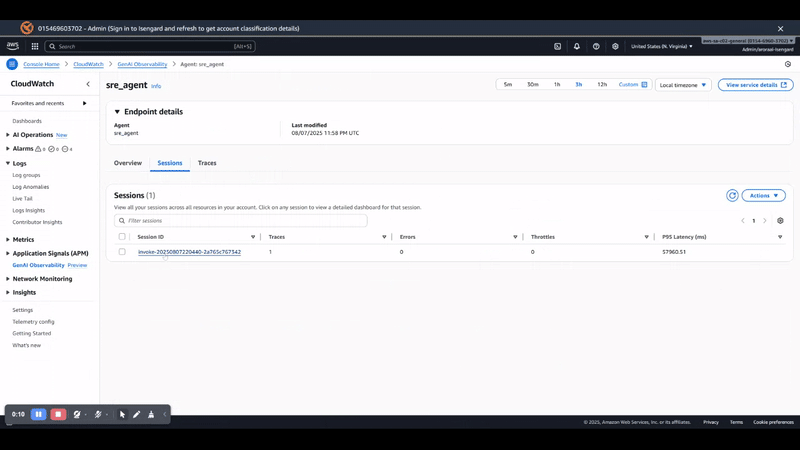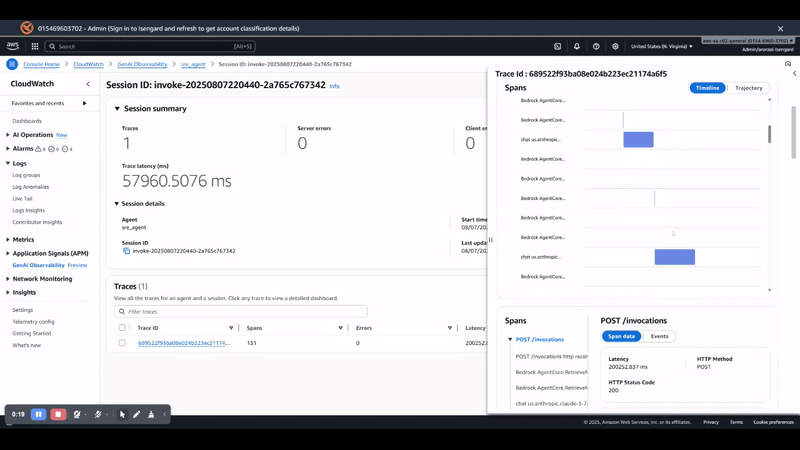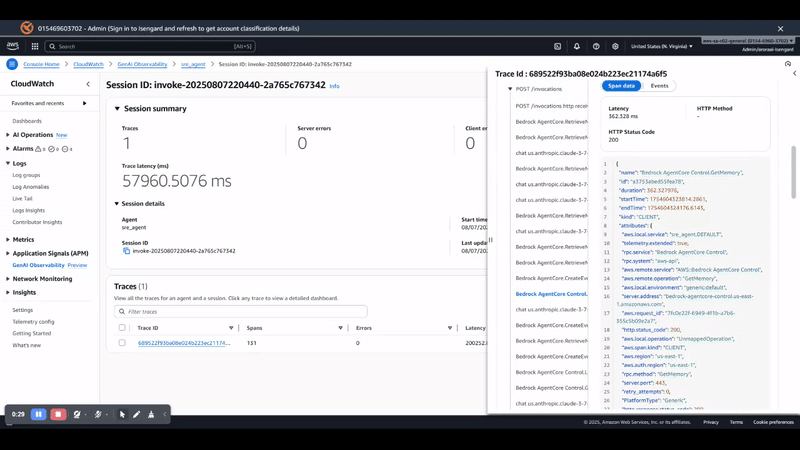
The observability primitive automatically captures these metrics without additional code changes, providing production-grade monitoring capabilities out of the box.
Development to production flow
The SRE agent follows a four-step structured deployment process from local development to production, with detailed procedures documented in Development to Production Flow in the accompanying GitHub repo:

The deployment process maintains consistency across environments: the core agent code (sre_agent/) remains unchanged, and the deployment/ folder contains deployment-specific utilities. The same agent works locally and in production through environment configuration, with Amazon Bedrock AgentCore Gateway providing MCP tools access across different stages of development and deployment.
Implementation walkthrough
In the following section, we focus on how Amazon Bedrock AgentCore Gateway, Memory, and Runtime work together to build this multi-agent collaboration solution and deploy it end-to-end with MCP support and persistent intelligence.
We start by setting up the repository and establishing the local runtime environment with API keys, LLM providers, and demo infrastructure. We then bring core AgentCore components online by creating the gateway for standardized API access, configuring authentication, and establishing tool connectivity. We add intelligence through AgentCore Memory, creating strategies for user preferences and investigation history while loading personas for personalized incident response. Finally, we configure individual agents with specialized tools, integrate memory capabilities, orchestrate collaborative workflows, and deploy to AgentCore Runtime with full observability.
Detailed instructions for each step are provided in the repository:
Prerequisites
You can find the port forwarding requirements and other setup instructions in the README file’s Prerequisites section.
Convert APIs to MCP tools with Amazon Bedrock AgentCore Gateway
Amazon Bedrock AgentCore Gateway demonstrates the power of protocol standardization by converting existing backend APIs into MCP tools that agent frameworks can consume. This transformation happens seamlessly, requiring only OpenAPI specifications.
Upload OpenAPI specifications
The gateway process begins by uploading your existing API specifications to Amazon Simple Storage Service (Amazon S3). The create_gateway.sh script automatically handles uploading the four API specifications (Kubernetes, Logs, Metrics, and Runbooks) to your configured S3 bucket with proper metadata and content types. These specifications will be used to create API endpoint targets in the gateway.
Create an identity provider and gateway
Authentication is handled seamlessly through Amazon Bedrock AgentCore Identity. The main.py script creates both the credential provider and gateway:
Deploy API endpoint targets with credential providers
Each API becomes an MCP target through the gateway. The solution automatically handles credential management:
Validate MCP tools are ready for agent framework
Post-deployment, Amazon Bedrock AgentCore Gateway provides a standardized /mcp endpoint secured with JWT tokens. Testing the deployment with mcp_cmds.sh reveals the power of this transformation:
Universal agent framework compatibility
This MCP-standardized gateway can now be configured as a Streamable-HTTP server for MCP clients, including AWS Strands, Amazon’s agent development framework, LangGraph, the framework used in our SRE agent implementation, and CrewAI, a multi-agent collaboration framework.
The advantage of this approach is that existing APIs require no modification—only OpenAPI specifications. Amazon Bedrock AgentCore Gateway handles the following:
Protocol translation – Between REST APIs to MCP
Authentication – JWT token validation and credential injection
Security – TLS termination and access control
Standardization – Consistent tool naming and parameter handling
This means you can take existing infrastructure APIs (Kubernetes, monitoring, logging, documentation) and instantly make them available to AI agent frameworks that support MCP—through a single, secure, standardized interface.
Implement persistent intelligence with Amazon Bedrock AgentCore Memory
Whereas Amazon Bedrock AgentCore Gateway provides seamless API access, Amazon Bedrock AgentCore Memory transforms the SRE agent from a stateless system into an intelligent, learning assistant. The memory implementation demonstrates how a few lines of code can enable sophisticated personalization and cross-session knowledge retention.
Initialize memory strategies
The SRE agent memory component is built on Amazon Bedrock AgentCore Memory’s event-based model with automatic namespace routing. During initialization, the solution creates three memory strategies with specific namespace patterns:
The three strategies each serve distinct purposes:
User preferences (/sre/users/{user_id}/preferences) – Individual investigation styles and communication preferences
Infrastructure Knowledge: /sre/infrastructure/{user_id}/{session_id} – Domain expertise accumulated across investigations
Investigation Summaries: /sre/investigations/{user_id}/{session_id} – Historical incident patterns and resolutions
Load user personas and preferences
The solution comes preconfigured with user personas that demonstrate personalized investigations. The manage_memories.py script loads these personas:
Automatic namespace routing in action
The power of Amazon Bedrock AgentCore Memory lies in its automatic namespace routing. When the SRE agent creates events, it only needs to provide the actor_id—Amazon Bedrock AgentCore Memory automatically determines which namespaces the event belongs to:
Validate the personalized investigation experience
The memory component’s impact becomes clear when both Alice and Carol investigate the same issue. Using identical technical findings, the solution produces completely different presentations of the same underlying content.
Alice’s technical report contains detailed systematic analysis for technical teams:
Carol’s executive summary contains business impact focused for executive stakeholders:
The memory component enables this personalization while continuously learning from each investigation, building organizational knowledge that improves incident response over time.
Deploy to production with Amazon Bedrock AgentCore Runtime
Amazon Bedrock AgentCore makes it straightforward to deploy existing agents to production. The process involves three key steps: containerizing your agent, deploying to Amazon Bedrock AgentCore Runtime, and invoking the deployed agent.
Containerize your agent
Amazon Bedrock AgentCore Runtime requires ARM64 containers. The following code shows the complete Dockerfile:
Existing agents just need a FastAPI wrapper (agent_runtime:app) to become compatible with Amazon Bedrock AgentCore, and we add opentelemetry-instrument to enable observability through Amazon Bedrock AgentCore.
Deploy to Amazon Bedrock AgentCore Runtime
Deploying to Amazon Bedrock AgentCore Runtime is straightforward with the deploy_agent_runtime.py script:
Amazon Bedrock AgentCore handles the infrastructure, scaling, and session management automatically.
Invoke your deployed agent
Calling your deployed agent is just as simple with invoke_agent_runtime.py:
Key benefits of Amazon Bedrock AgentCore Runtime
Amazon Bedrock AgentCore Runtime offers the following key benefits:
Zero infrastructure management – No servers, load balancers, or scaling to configure
Built-in session isolation – Each conversation is completely isolated
AWS IAM integration – Secure access control without custom authentication
Automatic scaling – Scales from zero to thousands of concurrent sessions
The complete deployment process, including building containers and handling AWS permissions, is documented in the Deployment Guide.
Real-world use cases
Let’s explore how the SRE agent handles common incident response scenarios with a real investigation.
When facing a production issue, you can query the system in natural language. The solution uses Amazon Bedrock AgentCore Memory to personalize the investigation based on your role and preferences:
The supervisor retrieves Alice’s preferences from memory (detailed systematic analysis style) and creates an investigation plan tailored to her role as a Technical SRE:
The agents investigate sequentially according to the plan, each contributing their specialized analysis. The solution then aggregates these findings into a comprehensive executive summary:
This investigation demonstrates how Amazon Bedrock AgentCore primitives work together:
Amazon Bedrock AgentCore Gateway – Provides secure access to infrastructure APIs through MCP tools
Amazon Bedrock AgentCore Identity – Handles ingress and egress authentication
Amazon Bedrock AgentCore Runtime – Hosts the multi-agent solution with automatic scaling
Amazon Bedrock AgentCore Memory – Personalizes Alice’s experience and stores investigation knowledge for future incidents
Amazon Bedrock AgentCore Observability – Captures detailed metrics and traces in CloudWatch for monitoring and debugging
The SRE agent demonstrates intelligent agent orchestration, with the supervisor routing work to specialists based on the investigation plan. The solution’s memory capabilities make sure each investigation builds organizational knowledge and provides personalized experiences based on user roles and preferences.
This investigation showcases several key capabilities:
Multi-source correlation – It connects database configuration issues to API performance degradation
Sequential investigation – Agents work systematically through the investigation plan while providing live updates
Source attribution – Findings include the specific tool and data source
Actionable insights – It provides a clear timeline of events and prioritized recovery steps
Cascading failure detection – It can help show how one failure propagates through the system
Business impact
Organizations implementing AI-powered SRE assistance report significant improvements in key operational metrics. Initial investigations that previously took 30–45 minutes can now be completed in 5–10 minutes, providing SREs with comprehensive context before diving into detailed analysis. This dramatic reduction in investigation time translates directly to faster incident resolution and reduced downtime.The solution improves how SREs interact with their infrastructure. Instead of navigating multiple dashboards and tools, engineers can ask questions in natural language and receive aggregated insights from relevant data sources. This reduction in context switching enables teams to maintain focus during critical incidents and reduces cognitive load during investigations.Perhaps most importantly, the solution democratizes knowledge across the team. All team members can access the same comprehensive investigation techniques, reducing dependency on tribal knowledge and on-call burden. The consistent methodology provided by the solution makes sure investigation approaches remain uniform across team members and incident types, improving overall reliability and reducing the chance of missed evidence.
The automatically generated investigation reports provide valuable documentation for post-incident reviews and help teams learn from each incident, building organizational knowledge over time. Furthermore, the solution extends existing AWS infrastructure investments, working alongside services like Amazon CloudWatch, AWS Systems Manager, and other AWS operational tools to provide a unified operational intelligence system.
Extending the solution
The modular architecture makes it straightforward to extend the solution for your specific needs.
For example, you can add specialized agents for your domain:
Security agent – For compliance checks and security incident response
Database agent – For database-specific troubleshooting and optimization
Network agent – For connectivity and infrastructure debugging
You can also replace the demo APIs with connections to your actual systems:
Kubernetes integration – Connect to your cluster APIs for pod status, deployments, and events
Log aggregation – Integrate with your log management service (Elasticsearch, Splunk, CloudWatch Logs)
Metrics platform – Connect to your monitoring service (Prometheus, Datadog, CloudWatch Metrics)
Runbook repository – Link to your operational documentation and playbooks stored in wikis, Git repositories, or knowledge bases
Clean up
To avoid incurring future charges, use the cleanup script to remove the billable AWS resources created during the demo:
This script automatically performs the following actions:
Stop backend servers
Delete the gateway and its targets
Delete Amazon Bedrock AgentCore Memory resources
Delete the Amazon Bedrock AgentCore Runtime
Remove generated files (gateway URIs, tokens, agent ARNs, memory IDs)
For detailed cleanup instructions, refer to Cleanup Instructions.
Conclusion
The SRE agent demonstrates how multi-agent systems can transform incident response from a manual, time-intensive process into a time-efficient, collaborative investigation that provides SREs with the insights they need to resolve issues quickly and confidently.
By combining the enterprise-grade infrastructure of Amazon Bedrock AgentCore with standardized tool access in MCP, we’ve created a foundation that can adapt as your infrastructure evolves and new capabilities emerge.
The complete implementation is available in our GitHub repository, including demo environments, configuration guides, and extension examples. We encourage you to explore the solution, customize it for your infrastructure, and share your experiences with the community.
To get started building your own SRE assistant, refer to the following resources:
About the authors
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington, D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington, D.C.
 Dheeraj Oruganty is a Delivery Consultant at Amazon Web Services. He is passionate about building innovative Generative AI and Machine Learning solutions that drive real business impact. His expertise spans Agentic AI Evaluations, Benchmarking and Agent Orchestration, where he actively contributes to research advancing the field. He holds a master’s degree in Data Science from Georgetown University. Outside of work, he enjoys geeking out on cars, motorcycles, and exploring nature.
Dheeraj Oruganty is a Delivery Consultant at Amazon Web Services. He is passionate about building innovative Generative AI and Machine Learning solutions that drive real business impact. His expertise spans Agentic AI Evaluations, Benchmarking and Agent Orchestration, where he actively contributes to research advancing the field. He holds a master’s degree in Data Science from Georgetown University. Outside of work, he enjoys geeking out on cars, motorcycles, and exploring nature.