
OpenAI hasn’t released an open-weight language model since GPT-2 back in 2019. Six years later, they surprised everyone with two: gpt-oss-120b and the smaller gpt-oss-20b.
Naturally, we wanted to know — how do they actually perform?
To find out, we ran both models through our open-source workflow optimization framework, syftr. It evaluates models across different configurations — fast vs. cheap, high vs. low accuracy — and includes support for OpenAI’s new “thinking effort” setting.
In theory, more thinking should mean better answers. In practice? Not always.
We also use syftr to explore questions like “is LLM-as-a-Judge actually working?” and “what workflows perform well across many datasets?”.
Our first results with GPT-OSS might surprise you: the best performer wasn’t the biggest model or the deepest thinker.
Instead, the 20b model with low thinking effort consistently landed on the Pareto frontier, even rivaling the 120b medium configuration on benchmarks like FinanceBench, HotpotQA, and MultihopRAG. Meanwhile, high thinking effort rarely mattered at all.
How we set up our experiments
We didn’t just pit GPT-OSS against itself. Instead, we wanted to see how it stacked up against other strong open-weight models. So we compared gpt-oss-20b and gpt-oss-120b with:
qwen3-235b-a22b
glm-4.5-air
nemotron-super-49b
qwen3-30b-a3b
gemma3-27b-it
phi-4-multimodal-instruct
To test OpenAI’s new “thinking effort” feature, we ran each GPT-OSS model in three modes: low, medium, and high thinking effort. That gave us six configurations in total:
gpt-oss-120b-low / -medium / -high
gpt-oss-20b-low / -medium / -high
For evaluation, we cast a wide net: five RAG and agent modes, 16 embedding models, and a range of flow configuration options. To judge model responses, we used GPT-4o-mini and compared answers against known ground truth.
Finally, we tested across four datasets:
FinanceBench (financial reasoning)
HotpotQA (multi-hop QA)
MultihopRAG (retrieval-augmented reasoning)
PhantomWiki (synthetic Q&A pairs)
We optimized workflows twice: once for accuracy + latency, and once for accuracy + cost—capturing the tradeoffs that matter most in real-world deployments.
Optimizing for latency, cost, and accuracy
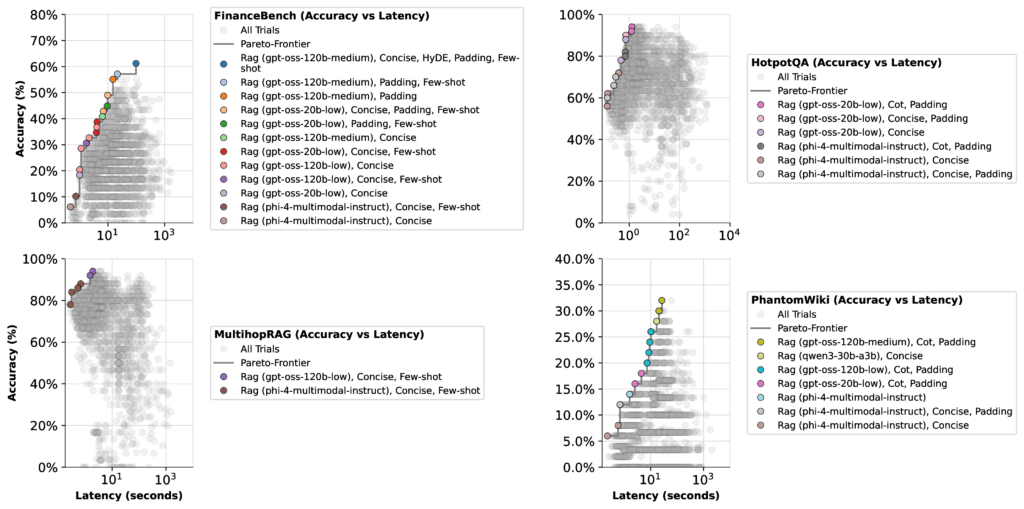
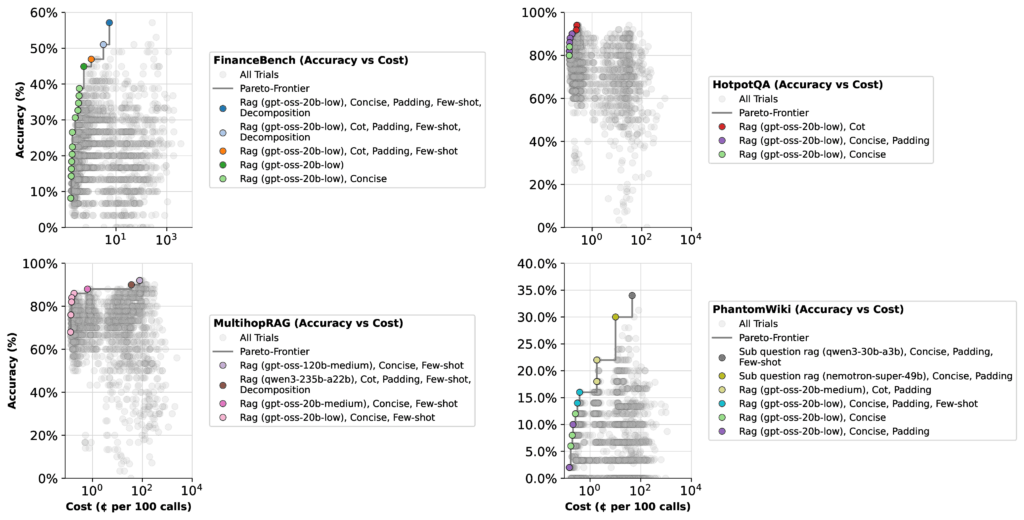
When we optimized the GPT-OSS models, we looked at two tradeoffs: accuracy vs. latency and accuracy vs. cost. The results were more surprising than we expected:
GPT-OSS 20b (low thinking effort):
Fast, inexpensive, and consistently accurate. This setup appeared on the Pareto frontier repeatedly, making it the best default choice for most non-scientific tasks. In practice, that means quicker responses and lower bills compared to higher thinking efforts.
GPT-OSS 120b (medium thinking effort):
Best suited for tasks that demand deeper reasoning, like financial benchmarks. Use this when accuracy on complex problems matters more than cost.
GPT-OSS 120b (high thinking effort):
Expensive and usually unnecessary. Keep it in your back pocket for edge cases where other models fall short. For our benchmarks, it didn’t add value.
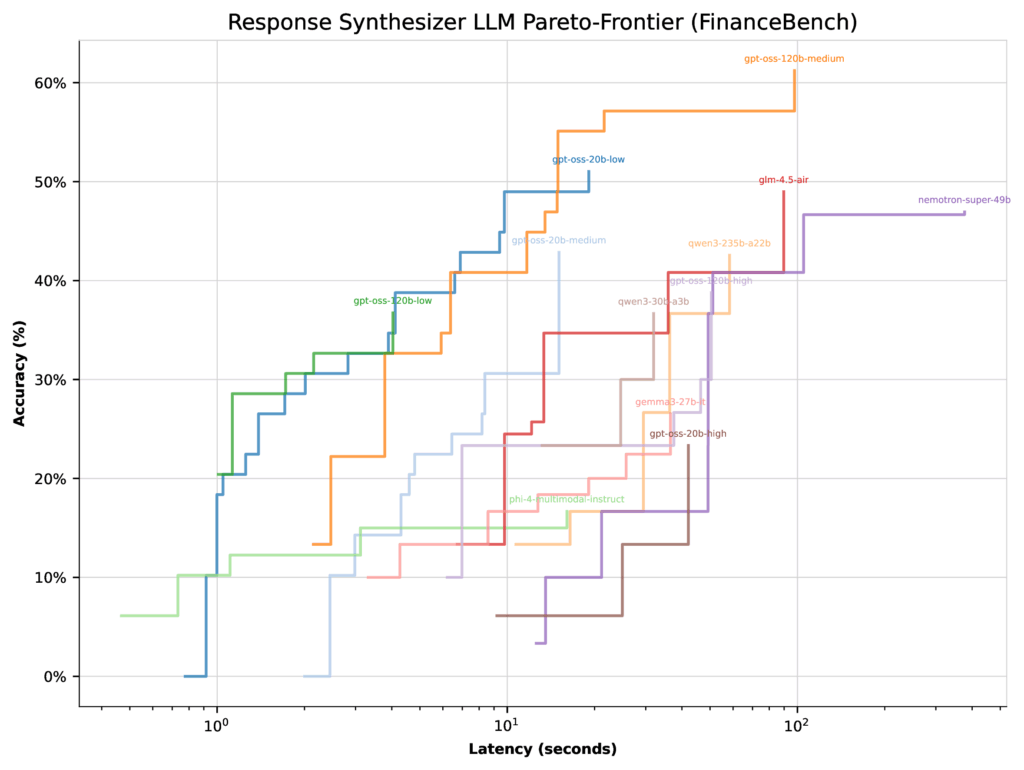
Reading the results more carefully
At first glance, the results look straightforward. But there’s an important nuance: an LLM’s top accuracy score depends not just on the model itself, but on how the optimizer weighs it against other models in the mix. To illustrate, let’s look at FinanceBench.
When optimizing for latency, all GPT-OSS models (except high thinking effort) landed with similar Pareto-frontiers. In this case, the optimizer had little reason to concentrate on the 20b low thinking configuration—its top accuracy was only 51%.
When optimizing for cost, the picture shifts dramatically. The same 20b low thinking configuration jumps to 57% accuracy, while the 120b medium configuration actually drops 22%. Why? Because the 20b model is far cheaper, so the optimizer shifts more weight toward it.
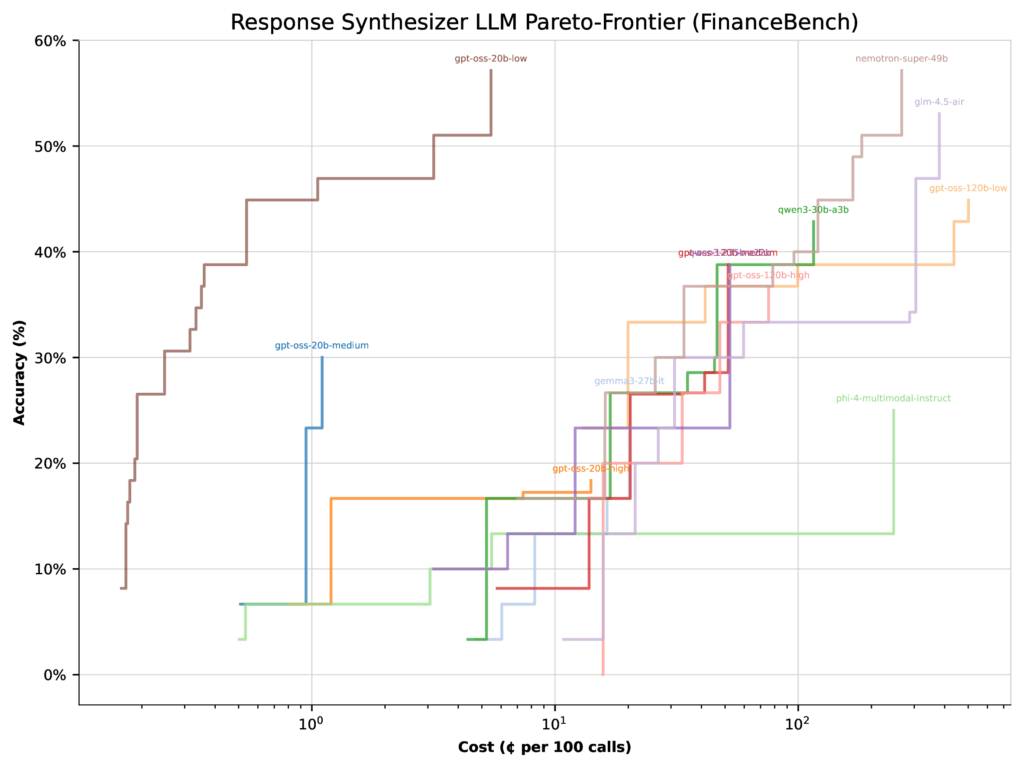
The takeaway: Performance depends on context. Optimizers will favor different models depending on whether you’re prioritizing speed, cost, or accuracy. And given the huge search space of possible configurations, there may be even better setups beyond the ones we tested.
Finding agentic workflows that work well in your setup
The new GPT-OSS models performed strongly in our tests — especially the 20b with low thinking effort, which often outpaced more expensive competitors. The bigger lesson? More model and more effort doesn’t always mean more accuracy. Sometimes, paying more just gets you less.
This is exactly why we built syftr and made it open-source. Every use case is different, and the best workflow for you depends on the tradeoffs you care about most. Want lower costs? Faster responses? Maximum accuracy?
Run your own experiments and find the Pareto sweet spot that balances those priorities for your setup.