
Alibaba Cloud has announced the launch of its next-generation base model architecture, Qwen3-Next, and has open-sourced the Qwen3-Next-80B-A3B series models (Instruct and Thinking) based on this architecture.
The Qwen team stated that Context Length Scaling and Total Parameter Scaling are two major trends in the future development of large models. To further enhance the training and inference efficiency of models under long contexts and large total parameters, they have designed a completely new model structure for Qwen3-Next.
This structure includes the following core improvements compared to the MoE model structure of Qwen3: a hybrid attention mechanism, a high sparsity MoE structure, a series of training stability-friendly optimizations, and a multi-token prediction mechanism that improves inference efficiency.
Based on the Qwen3-Next model structure, the team trained the Qwen3-Next-80B-A3B-Base model, which has 80 billion parameters (activating only 3 billion parameters), a 3B activated ultra-sparse MoE architecture (512 experts, routing 10 + 1 shared), combined with Hybrid Attention (Gated DeltaNet + Gated Attention) and multi-token prediction (MTP).
According to IT Home, this Base model achieves performance comparable to or slightly better than the Qwen3-32B dense model, while its training cost is less than one-tenth of that of Qwen3-32B. Its inference throughput under contexts exceeding 32k is more than ten times that of Qwen3-32B, achieving an exceptional cost-performance ratio in training and inference.
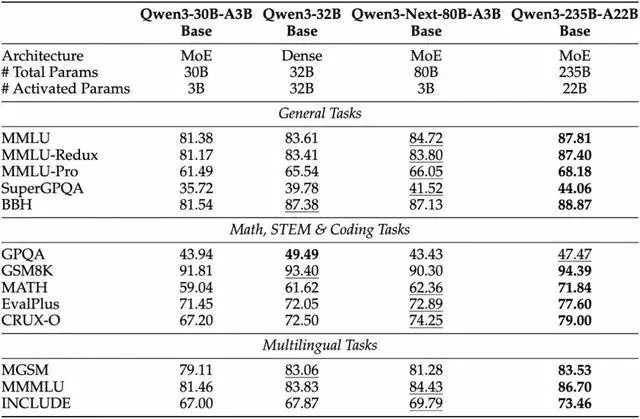
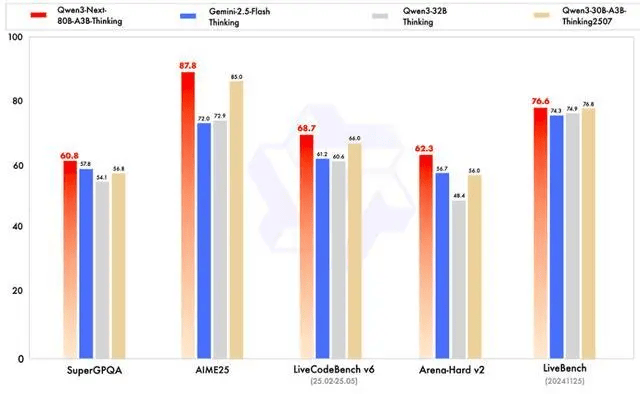
This model natively supports a context of 262K and is claimed to extrapolate to approximately 1.01 million tokens. The Instruct version is reported to be close to Qwen3-235B in several evaluations, while the Thinking version surpasses Gemini-2.5-Flash-Thinking in some inference tasks.
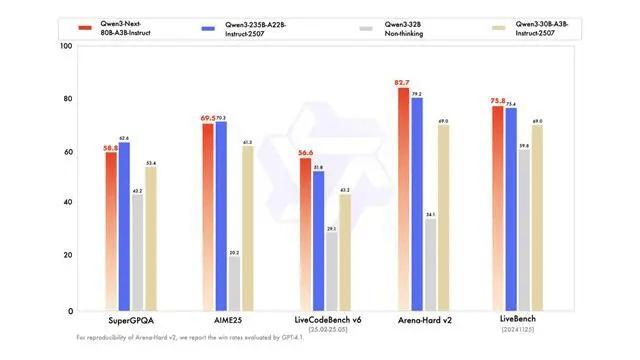
Its breakthrough lies in achieving large-scale parameter capacity, low activation overhead, long context processing, and parallel inference acceleration simultaneously, making it a representative model among similar architectures.
The model weights have been released on Hugging Face under the Apache-2.0 license and can be deployed through frameworks such as Transformers, SGLang, and vLLM; the third-party platform OpenRouter is also now online.
[Source: IT Home]返回搜狐,查看更多