
On the night of September 9, Tencent released and open-sourced the latest image model “Hunyuan Image 2.1”. This model boasts industry-leading capabilities and supports native 2K high-definition images.
After its open-source release, the Hunyuan Image 2.1 model quickly climbed the popularity charts on Hugging Face, becoming the third most popular model globally. Among the top eight models on the list, the Tencent Hunyuan model family occupies three spots.
At the same time, the Tencent Hunyuan team revealed that they will soon release a native multimodal image generation model.
Hunyuan Image 2.1 is a comprehensive upgrade based on the 2.0 architecture, focusing more on balancing generation effects and performance. The new version supports native input in both Chinese and English and can generate high-quality outputs from complex semantics in both languages. Furthermore, there have been significant improvements in the overall aesthetic quality of generated images and the diversity of applicable scenarios.
This means that designers, illustrators, and other visual creators can more efficiently and conveniently translate their ideas into images. Whether generating high-fidelity creative illustrations, producing posters and packaging designs with Chinese and English slogans, or creating complex four-panel comics and graphic novels, Hunyuan Image 2.1 can provide fast, high-quality support for creators.
Hunyuan Image 2.1 is a fully open-source foundational model that not only offers industry-leading generation effects but is also flexible enough to adapt to the diverse derivative needs of the community. Currently, the model weights and code for Hunyuan Image 2.1 have been officially released in open-source communities such as Hugging Face and GitHub, allowing individual and corporate developers to conduct research or develop various derivative models and plugins based on this foundational model.
Thanks to a larger-scale dataset for text-image alignment, Hunyuan Image 2.1 has made significant advancements in complex semantic understanding and cross-domain generalization capabilities. It supports prompts of up to 1000 tokens, allowing for precise generation of scene details, character expressions, and actions, enabling distinct deions and controls for multiple objects. Additionally, Hunyuan Image 2.1 can finely control text within images, ensuring that textual information naturally integrates with visuals.

Highlight 1 of Hunyuan Image 2.1: Strong capability in understanding complex semantics, supporting distinct deions and precise generation of multiple subjects.

Highlight 2 of Hunyuan Image 2.1: More stable control over text and scene details within images.

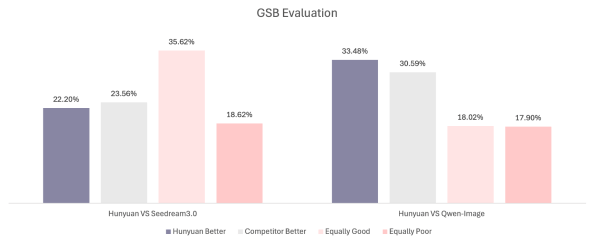
Tencent’s Hunyuan Image Model 2.1 is at the SOTA level among open-source models.
According to the evaluation results from SSAE (Structured Semantic Alignment Evaluation), Tencent’s Hunyuan Image Model 2.1 has achieved optimal performance in semantic alignment among open-source models and is very close to the performance of closed-source commercial models (GPT-Image).

Meanwhile, the GSB (Good Same Bad) evaluation results indicate that the image generation quality of Hunyuan Image 2.1 is comparable to the closed-source commercial model Seedream 3.0, while slightly outperforming similar open-source models like Qwen-Image.
The Hunyuan Image 2.1 model not only utilizes massive training data but also employs structured, varied-length, and diverse content captions, significantly enhancing its understanding of textual deions. The caption model incorporates OCR and IP RAG expert models, effectively improving its response capabilities for complex text recognition and world knowledge.
To greatly reduce computational load and enhance training and inference efficiency, the model employs a VAE with a 32-fold ultra-high compression ratio and uses dinov2 alignment and repa loss to simplify training difficulties. As a result, the model can efficiently generate native 2K images.
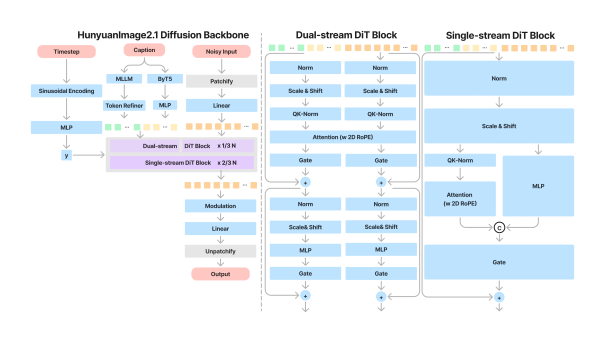
In terms of text encoding, Hunyuan Image 2.1 is equipped with dual text encoders: one MLLM module to further enhance text-image alignment capabilities, and another ByT5 model to boost text generation expressiveness. The overall architecture consists of a 17B parameter single/dual-flow DiT model.
Additionally, Hunyuan Image 2.1 addresses the training stability issues of average flow models (meanflow) at the 17B parameter level, reducing the number of inference steps from 100 to 8, significantly improving inference speed while ensuring the model’s original effectiveness.
The simultaneously open-sourced Hunyuan text rewriting model (PromptEnhancer) is the industry’s first systematic, industrial-grade Chinese-English rewriting model, capable of structurally optimizing user text instructions and enriching visual expressions, greatly enhancing the semantic representation of images generated from the rewritten text.
Tencent Hunyuan continues to delve into the field of image generation, having previously released the first open-source Chinese native DiT architecture image model—Hunyuan DiT—and the industry’s first commercial-grade real-time image model—Hunyuan Image 2.0. The newly launched native 2K model Hunyuan Image 2.1 strikes a better balance between effect and performance, meeting the diverse needs of users and enterprises in various visual scenarios.
At the same time, Tencent Hunyuan is firmly embracing open-source, gradually releasing various sized language models, complete multimodal generation capabilities and toolset plugins for images, videos, and 3D, providing an open-source foundation close to commercial model performance. The total number of image and video derivative models has reached 3000, and the Hunyuan 3D series model community download count has exceeded 2.3 million, making it the most popular 3D open-source model globally.返回搜狐,查看更多