
The Tencent Hunyuan Laboratory team has just open-sourced a new generation AI audio generation system called “Hunyuan Video-Foley,” which provides realistic sound effects for AI-generated videos. It is said that the system can “listen” to video content and generate high-quality soundtracks perfectly synchronized with the visual actions. Let’s take a look.
Have you ever felt something was missing while watching an AI-generated video? The visuals might be stunning, but the eerie silence can break the immersion. In the film industry, the sounds that fill this silence—rustling leaves, booming thunder, the crisp sound of glass clinking—are known as Foley art, a meticulous craft performed by professionals.
Achieving such detail restoration with AI is a significant challenge. For years, automated systems have struggled to generate convincing audio for videos.
Detailed Introduction of Model Capabilities
Part.1
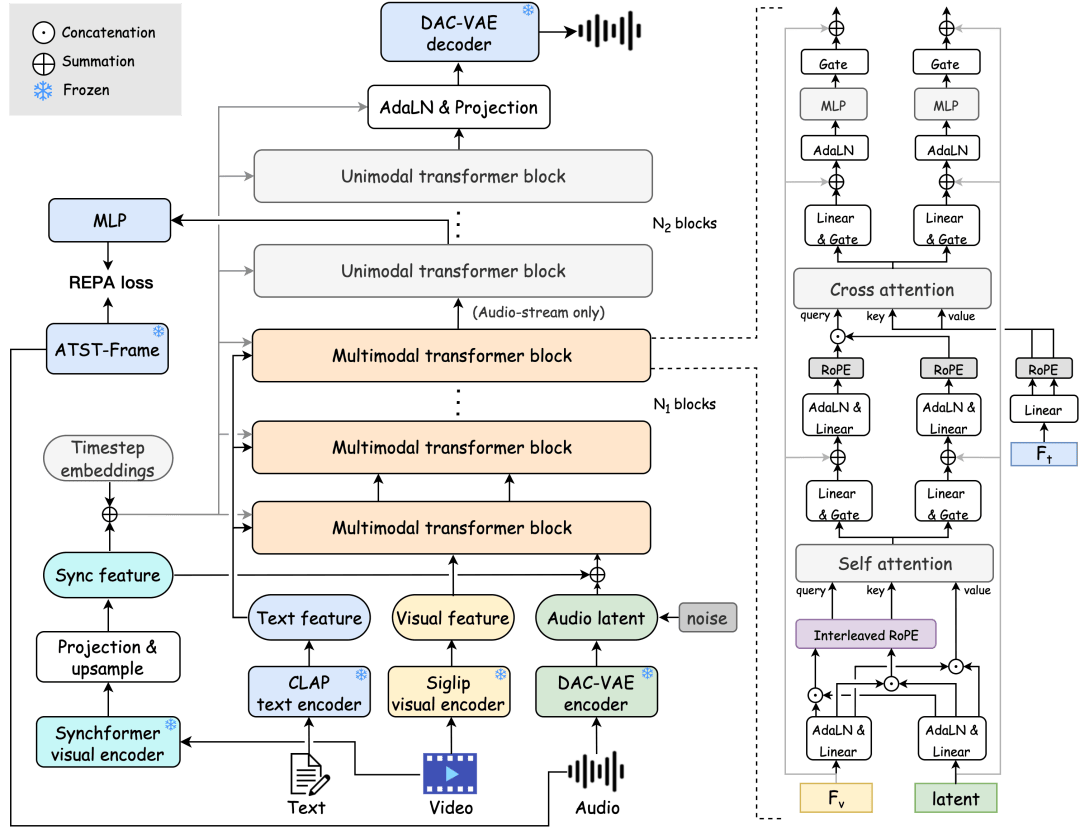
Hunyuan Video-Foley is an end-to-end multimodal audio generation framework capable of producing high-fidelity audio that is consistent with the input video and text semantics, tightly aligned in timing. To achieve multimodal conditional balanced responses, the framework employs a multimodal audio generation architecture that includes dual-stream MMDiT and single-stream audio DiT. The MMDiT module enhances the temporal dependencies between video and audio through an interleaved RoPE joint self-attention mechanism and injects text semantic information using a cross-attention mechanism.
By aligning the hidden layer embeddings of the single-stream audio DiT module with audio features extracted from a pre-trained self-supervised model through representation alignment loss, the quality of the generated audio is significantly improved. Additionally, an improved DAC-VAE has been designed based on the DAC structure, replacing its discrete tokens with 128-dimensional continuous representations, greatly enhancing audio reconstruction capabilities.
Hunyuan Video-Foley has been trained on a high-quality multimodal dataset of 100,000 hours, covering the vast majority of video scenarios, and has demonstrated exceptional performance on multiple authoritative evaluation benchmarks, achieving the most powerful video sound effect generation results to date.
How Did Tencent Solve the Challenge of AI Sound Effect Generation for Videos?
Part.2
The core reason for the poor performance of past video-to-audio (V2A) models has been termed “modal imbalance” by researchers. Essentially, AI has focused more on parsing textual instructions rather than analyzing the actual content of the video.
For example, if a model is given a video showing a bustling beach (with pedestrians strolling and seagulls soaring), but the text prompt only requests “sound of waves,” the system often only generates wave sounds. The AI completely ignores the sounds of footsteps on the sand and birds chirping, resulting in a lifeless scene.
Moreover, the generated audio quality is often unsatisfactory, and there is a severe lack of high-quality audio-video training data.

The Tencent Hunyuan team tackled these challenges from three dimensions:
Constructing a database of video-audio-text deion triplets spanning 100,000 hours, filtering out low-quality content from the internet through an automated pipeline, removing segments with long periods of silence or compressed, blurry audio to ensure the model learns from optimal material.
Designing an intelligent multi-task architecture. The system first focuses intensely on the audiovisual temporal correlation—such as precisely matching the sound of footsteps with the moment the shoe sole contacts the ground. Once the timing is locked, it integrates text prompts to understand the overall atmosphere of the scene. This dual mechanism ensures that no video detail is overlooked.
Employing a Representation Alignment (REPA) training strategy to ensure audio quality. By comparing AI outputs with features from pre-trained professional audio models, it guides the generation of clearer, fuller, and more stable sound effects.
Constructing a database of video-audio-text deion triplets spanning 100,000 hours, filtering out low-quality content from the internet through an automated pipeline, removing segments with long periods of silence or compressed, blurry audio to ensure the model learns from optimal material.
Designing an intelligent multi-task architecture. The system first focuses intensely on the audiovisual temporal correlation—such as precisely matching the sound of footsteps with the moment the shoe sole contacts the ground. Once the timing is locked, it integrates text prompts to understand the overall atmosphere of the scene. This dual mechanism ensures that no video detail is overlooked.
Employing a Representation Alignment (REPA) training strategy to ensure audio quality. By comparing AI outputs with features from pre-trained professional audio models, it guides the generation of clearer, fuller, and more stable sound effects.
Measured Results Showcase Advantages
Part.3
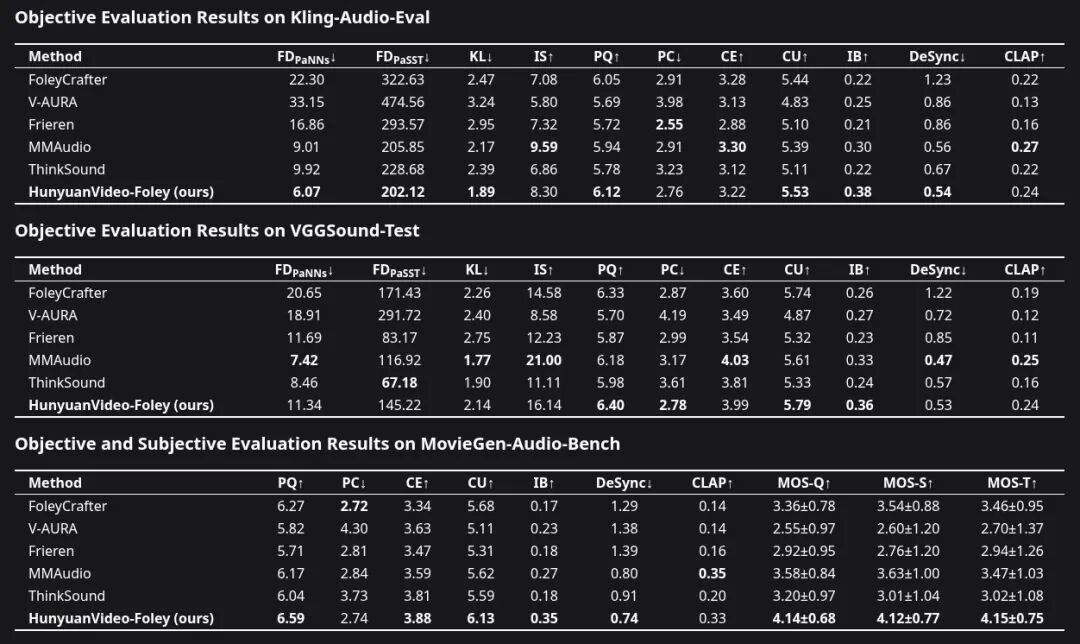
In comparative tests with mainstream AI models, the audio generation advantages of Hunyuan Video-Foley are evident. Not only are the computational evaluation metrics superior, but human listeners also unanimously agree that its output sound quality is better, more closely matches the video, and has more precise timing.
Official Examples:
In terms of synchronizing audio with visual content and timing alignment, the system has achieved significant improvements across all evaluation dimensions. Results from multiple authoritative datasets confirm this:
This research effectively bridges the gap between silent AI videos and immersive viewing experiences. It brings the magic of professional Foley sound effects into the realm of automated content creation, providing powerful support for filmmakers, animators, and creators worldwide.
In this regard, we have evaluated several outstanding videos presented officially from a professional perspective; please see the specific content:
01
Coffee Pouring Video Prompt: Soft sound of pouring coffee
First, regarding the video generation issue, the coffee cup is too large, and the proportion of the hand and the cup being poured is very strange, so when the video has issues, the generated audio will feel inappropriate no matter what; it is recommended to replace this video first.
Returning to the audio, the sound itself also has issues; it does not resemble the sound of pouring into a white porcelain coffee cup. Additionally, the sound of the water has no variation; there is no sound change from an empty cup to a full cup. It is commendable that background sounds were still generated even without prompts. Overall, the sound does not reach a professional level.
02
Stream Surface Flying Video Prompt: The gentle sound of the stream flowing, with a background of a melodious piano solo carrying a serene classical melody that brings peace and tranquility
Although the name and function highlight the Foley sound effects, it is actually a comprehensive AI model for generating audio for videos that includes music generation. If evaluated by more professional standards, the sound of the stream is a bit thin; the water sound is much quieter and subtler than what is presented in the video, and the stream does not change with the camera’s movement. This sound effect can only be considered quite average and somewhat amateurish as background sound. Considering the music generation and the mixing ratio of music with stream sounds, it is still noteworthy.
03
A Girl Walking Through a Forest Video Prompt: The sound of vines and leaves rustling, curtains being lifted, accompanied by the gentle footsteps of a person entering a clearing in the woods
Looking at the audio from the arrangement of the prompts, the sound of green vines and leaves is too dry and does not accurately match the sound of hands brushing against the vines. If one does not look at the prompts, they might completely overlook the sound of the vines. The most peculiar thing is the footsteps; the sounds of going and returning footsteps clearly occur on the same ground, but for some reason, they differ greatly, possibly due to the prompt “gentle footsteps on the forest floor” limiting the output. Lastly, the sound of dry leaves crunching is very harsh and does not correspond with the season and overall feeling depicted in the video.
04
Light Rain Car Departure Prompt: Wheels rolling over a wet surface
This video’s sound is the best among the four, with the soft sound of rain and the background noise of city streets as the car drives out onto the wet road. Overall, it is quite good, especially the distant sound of a car coming from afar, which was recognized and provided the sound effect of a car driving on a wet road from a distance, which is very nice.
However, according to professional standards, the foreground sound of the car driving out shows a noticeable up-and-down fluctuation, and the details of the rear tires rolling over small puddles are missing; these details are what define professionalism.
In summary, this video-generated audio model shows improvements over other similar models in certain details but does not represent a qualitative leap, nor does it provide us with a markedly different experience. Its approach of generating audio based on prompts is also quite common at present.
From the audio perspective, these so-called professional-level generated sound effects are still somewhat distant from true professionalism, especially when paired with already problematic AI-generated visuals. Considering that these more vertical large models are still in their infancy, we remain very curious about the future.
As various AI manufacturers increasingly attach terms like “professional” and “cinema-level” to AIGC, the actual results often fall far short of the high expectations set, and we hope these models can truly engage in more communication with professionals.
What do you think? Feel free to leave a comment!
The Tencent Hunyuan Laboratory team has just open-sourced a new generation AI audio generation system called “Hunyuan Video-Foley,” which provides realistic sound effects for AI-generated videos.返回搜狐,查看更多