
Every day, enterprises process thousands of documents containing critical business information. From invoices and purchase orders to forms and contracts, accurately locating and extracting specific fields has traditionally been one of the most complex challenges in document processing pipelines. Although optical character recognition (OCR) can tell us what text exists in a document, determining where specific information is located has required sophisticated computer vision solutions.
The evolution of this field illustrates the complexity of the challenge. Early object detection approaches like YOLO (You Only Look Once) revolutionized the field by reformulating object detection as a regression problem, enabling real-time detection. RetinaNet advanced this further by addressing class imbalance issues through Focal Loss, and DETR introduced transformer-based architectures to minimize hand-designed components. However, these approaches shared common limitations: they required extensive training data, complex model architectures, and significant expertise to implement and maintain.
The emergence of multimodal large language models (LLMs) represents a paradigm shift in document processing. These models combine advanced vision understanding with natural language processing capabilities, offering several groundbreaking advantages:
Minimized use of specialized computer vision architectures
Zero-shot capabilities without the need for supervised learning
Natural language interfaces for specifying location tasks
Flexible adaptation to different document types
This post demonstrates how to use foundation models (FMs) in Amazon Bedrock, specifically Amazon Nova Pro, to achieve high-accuracy document field localization while dramatically simplifying implementation. We show how these models can precisely locate and interpret document fields with minimal frontend effort, reducing processing errors and manual intervention. Through comprehensive benchmarking on the FATURA dataset, we provide benchmarking of performance and practical implementation guidance.
Understanding document information localization
Document information localization goes beyond traditional text extraction by identifying the precise spatial position of information within documents. Although OCR tells us what text exists, localization tells us where specific information resides—a crucial distinction for modern document processing workflows. This capability enables critical business operations ranging from automated quality checks and sensitive data redaction to intelligent document comparison and validation.
Traditional approaches to this challenge relied on a combination of rule-based systems and specialized computer vision models. These solutions often required extensive training data, careful template matching, and continuous maintenance to handle document variations. Financial institutions, for instance, would need separate models and rules for each type of invoice or form they processed, making scalability a significant challenge. Multimodal models with localization capabilities available on Amazon Bedrock fundamentally change this paradigm. Rather than requiring complex computer vision architectures or extensive training data, these multimodal LLMs can understand both the visual layout and semantic meaning of documents through natural language interactions. By using models with the capability to localize, organizations can implement robust document localization with significantly reduced technical overhead and greater adaptability to new document types.
Multimodal models with localization capabilities, such as those available on Amazon Bedrock, fundamentally change this paradigm. Rather than requiring complex computer vision architectures or extensive training data, these multimodal LLMs can understand both the visual layout and semantic meaning of documents through natural language interactions. By using models with the capability to localize, organizations can implement robust document localization with significantly reduced technical overhead and greater adaptability to new document types.
Solution overview
We designed a simple localization solution that takes a document image and text prompt as input, processes it through selected FMs on Amazon Bedrock, and returns the field locations using either absolute or normalized coordinates. The solution implements two distinct prompting strategies for document field localization:
Image dimension strategy – Works with absolute pixel coordinates, providing explicit image dimensions and requesting bounding box locations based on the document’s actual size
Scaled coordinate strategy – Uses a normalized 0–1000 coordinate system, making it more flexible across different document sizes and formats
The solution has a modular design to allow for straightforward extension to support custom field schemas through configuration updates rather than code changes. This flexibility, combined with the scalability of Amazon Bedrock, makes the solution suitable for both small-scale document processing and enterprise-wide deployment. In the following sections, we demonstrate the setup and implementation strategies used in our solution for document field localization using Amazon Bedrock FMs. You can see more details in our GitHub repository.
Prerequisites
For this walkthrough, you should have the following prerequisites:
An AWS account with Amazon Bedrock access
Permissions to use Amazon Nova Pro
Python 3.8+ with the boto3 library installed
Initial set ups
Complete the following setup steps:
Configure the Amazon Bedrock runtime client with appropriate retry logic and timeout settings:
from botocore.config import Config
# Configure Bedrock client with retry logic
BEDROCK_CONFIG = Config(
region_name=”us-west-2″,
signature_version=’v4′,
read_timeout=500,
retries={
‘max_attempts’: 10,
‘mode’: ‘adaptive’
}
)
# Initialize Bedrock runtime client
bedrock_runtime = boto3.client(“bedrock-runtime”, config=BEDROCK_CONFIG)
Define your field configuration to specify which elements to locate in your documents:
field_config = {
“invoice_number”: {“type”: “string”, “required”: True},
“total_amount”: {“type”: “currency”, “required”: True},
“date”: {“type”: “date”, “required”: True}
}
Initialize the BoundingBoxExtractor with your chosen model and strategy:
model_id=NOVA_PRO_MODEL_ID, # or other FMs on Amazon Bedrock
prompt_template_path=”path/to/prompt/template”,
field_config=field_config,
norm=None # Set to 1000 for scaled coordinate strategy
)
# Process a document
bboxes, metadata = extractor.get_bboxes(
document_image=document_image,
document_key=”invoice_001″ # Optional tracking key
)
Implement prompting strategies
We test two prompt strategies in this workflow: image dimension and scaled coordinate.
The following is a sample prompt template for the image dimension strategy:
Your task is to detect and localize objects in images with high precision.
Analyze each provided image (width = {w} pixels, height = {h} pixels) and return only a JSON object with bounding box data for detected objects.
Output Requirements:
1. Use absolute pixel coordinates based on provided width and height.
2. Ensure high accuracy and tight-fitting bounding boxes.
Detected Object Structure:
– “element”: Use one of these labels exactly: {elements}
– “bbox”: Array with coordinates [x1, y1, x2, y2] in absolute pixel values.
JSON Structure:
“`json
{schema}
“`
Provide only the specified JSON format without extra information.
“””
The following is a sample prompt template for the scaled coordinate strategy:
Your task is to detect and localize objects in images with high precision.
Analyze each provided image and return only a JSON object with bounding box data for detected objects.
Output Requirements:
Use (x1, y1, x2, y2) format for bounding box coordinates, scaled between 0 and 1000.
Detected Object Structure:
– “element”: Use one of these labels exactly: {elements}
– “bbox”: Array [x1, y1, x2, y2] scaled between 0 and 1000.
JSON Structure:
“`json
{schema}
“`
Provide only the specified JSON format without extra information.
“””
Evaluate performance
We implement evaluation metrics to monitor accuracy:
evaluator.set_iou_threshold(0.5) # Adjust based on requirements
evaluator.set_margin_percent(5) # Tolerance for position matching
# Evaluate predictions
results = evaluator.evaluate(predictions, ground_truth)
print(f”Mean Average Precision: {results[‘mean_ap’]:.4f}”)
This implementation provides a robust foundation for document field localization while maintaining flexibility for different use cases and document types. The choice between image dimension and scaled coordinate strategies depends on your specific accuracy requirements and document variation.
Benchmarking results
We conducted our benchmarking study using FATURA, a public invoice dataset specifically designed for document understanding tasks. The dataset comprises 10,000 single-page invoices saved as JPEG images, representing 50 distinct layout templates with 200 invoices per template. Each document is annotated with 24 key fields, including invoice numbers, dates, line items, and total amounts. The annotations provide both the text values and precise bounding box coordinates in JSON format, making it ideal for evaluating field localization tasks. The dataset has the following key characteristics:
Documents: 10,000 invoices (JPEG format)
Templates: 50 distinct layouts (200 documents each)
Fields per document: 24 annotated fields
Annotation format: JSON with bounding boxes and text values
Field types: Invoice numbers, dates, addresses, line items, amounts, taxes, totals
Image resolution: Standard A4 size at 300 DPI
Language: English
The following figure shows sample invoice templates showcasing layout variation.
The following figure is an example of annotation visualization.


Before conducting the full-scale benchmark, we performed an initial experiment to determine the optimal prompting strategy. We selected a representative subset of 50 images, comprising 5 samples from 10 different templates, and evaluated three distinct approaches:
Image dimension:
Method: Provides explicit pixel dimensions and requests absolute coordinate bounding boxes
Input: Image bytes, image dimensions, output schema
Scaled coordinate:
Method: Uses normalized 0-1000 coordinate system
Input: Image bytes, output schema
Added gridlines:
Method: Enhances image with visual gridlines at fixed intervals
Input: Modified image with gridlines bytes, image dimensions, output schema
The following figure compares performance for different approaches for Mean Average Precision (mAP).
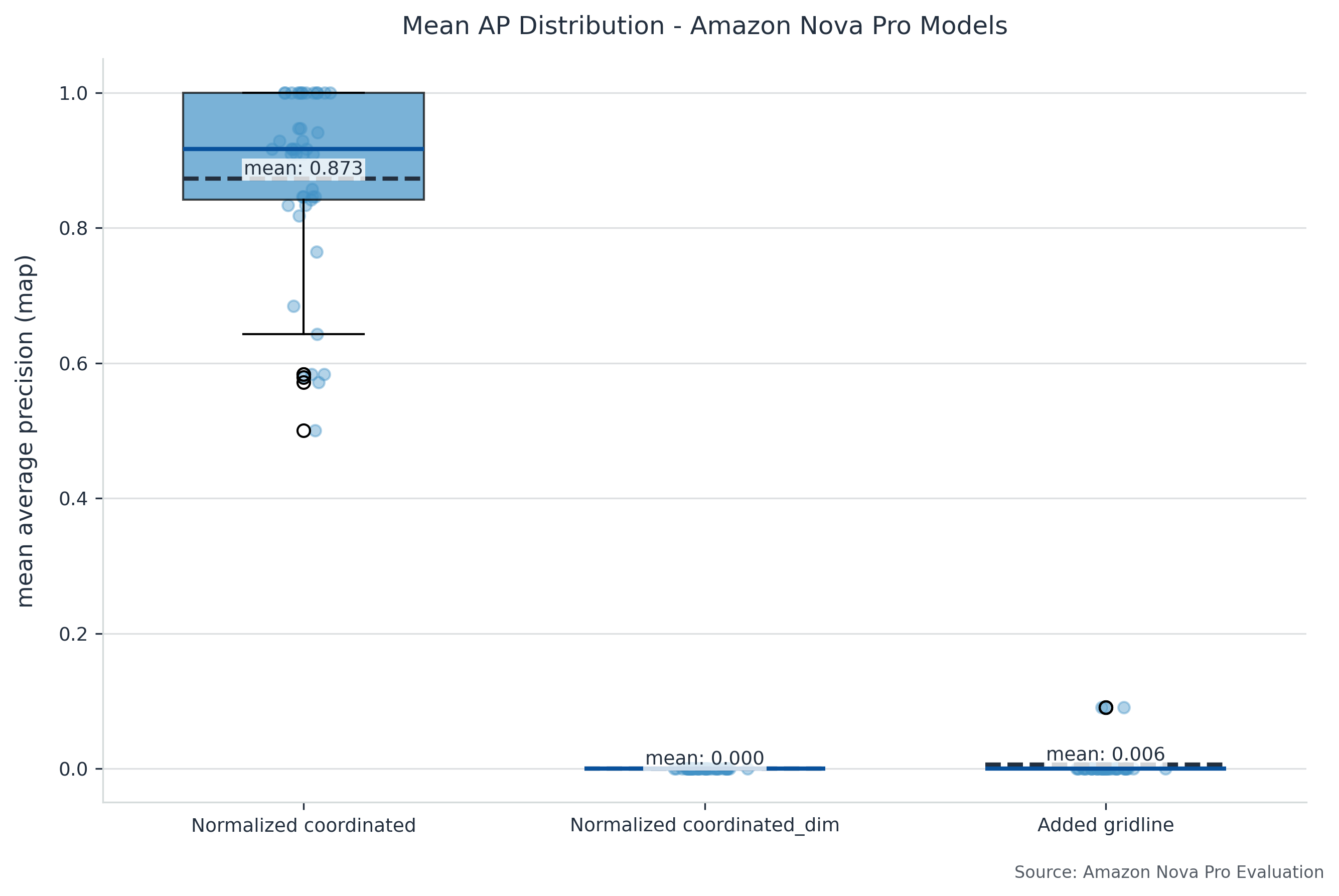
Building on insights from our initial strategy evaluation, we conducted benchmarking using the complete FATURA dataset of 10,000 documents. We employed the scaled coordinate approach for Amazon Nova models, based on their respective optimal performance characteristics from our initial testing. Our evaluation framework assessed Amazon Nova Pro through standard metrics, including Intersection over Union (IoU) and Average Precision (AP). The evaluation spanned all 50 distinct invoice templates, using an IoU threshold of 0.5 and a 5% margin tolerance for field positioning.
The following are our sample results in JSON:
“template”: “template1”,
“instance”: “Instance0”,
“metrics”: {
“mean_ap”: 0.8421052631578947,
“field_scores”: {
“TABLE”: [0.9771107575829314, 1.0, 1.0, 1.0, 1.0],
“BUYER”: [0.3842328422050217, 0.0, 0.0, 0, 0.0],
“DATE”: [0.9415158516000428, 1.0, 1.0, 1.0, 1.0],
“DISCOUNT”: [0.8773709977744115, 1.0, 1.0, 1.0, 1.0],
“DUE_DATE”: [0.9338410331219548, 1.0, 1.0, 1.0, 1.0],
“GSTIN_BUYER”: [0.8868145680064249, 1.0, 1.0, 1.0, 1.0],
“NOTE”: [0.7926162009357707, 1.0, 1.0, 1.0, 1.0],
“PAYMENT_DETAILS”: [0.9517931284002012, 1.0, 1.0, 1.0, 1.0],
“PO_NUMBER”: [0.8454266053075804, 1.0, 1.0, 1.0, 1.0],
“SELLER_ADDRESS”: [0.9687004508445741, 1.0, 1.0, 1.0, 1.0],
“SELLER_EMAIL”: [0.8771026147909002, 1.0, 1.0, 1.0, 1.0],
“SELLER_SITE”: [0.8715647216012751, 1.0, 1.0, 1.0, 1.0],
“SUB_TOTAL”: [0.8049954543667662, 1.0, 1.0, 1.0, 1.0],
“TAX”: [0.8751563641702513, 1.0, 1.0, 1.0, 1.0],
“TITLE”: [0.850667327423512, 1.0, 1.0, 1.0, 1.0],
“TOTAL”: [0.7226784112051814, 1.0, 1.0, 1.0, 1.0],
“TOTAL_WORDS”: [0.9099353099528785, 1.0, 1.0, 1.0, 1.0],
“GSTIN_SELLER”: [0.87170328009624, 1.0, 1.0, 1.0, 1.0],
“LOGO”: [0.679425211111111, 1.0, 1.0, 1.0, 1.0]
}
},
“metadata”: {
“usage”: {
“inputTokens”: 2250,
“outputTokens”: 639,
“totalTokens”: 2889
},
“metrics”: {
“latencyMs”: 17535
}
}
}
The following figure is an example of successful localization for Amazon Nova Pro.

The results demonstrate Amazon Nova Pro’s strong performance in document field localization. Amazon Nova Pro achieved a mAP of 0.8305. It demonstrated consistent performance across various document layouts, achieving a mAP above 0.80 across 45 of 50 templates, with the lowest template-specific mAP being 0.665. Although Amazon Nova Pro showed relatively high processing failures (170 out of 10,000 images), it still maintained high overall performance. Most low AP results were attributed to either complete processing failures (particularly over-refusal by its guardrail filters and malformed JSON output) or field misclassifications (particularly confusion between similar fields, such as buyer vs. seller addresses).
The following table summarizes the overall performance metrics.
Mean IoU
Mean AP
Amazon Nova Pro
0.7423
0.8331
The following graph shows the performance distribution for each individual extraction of approximately 20 labels for 10,000 documents.
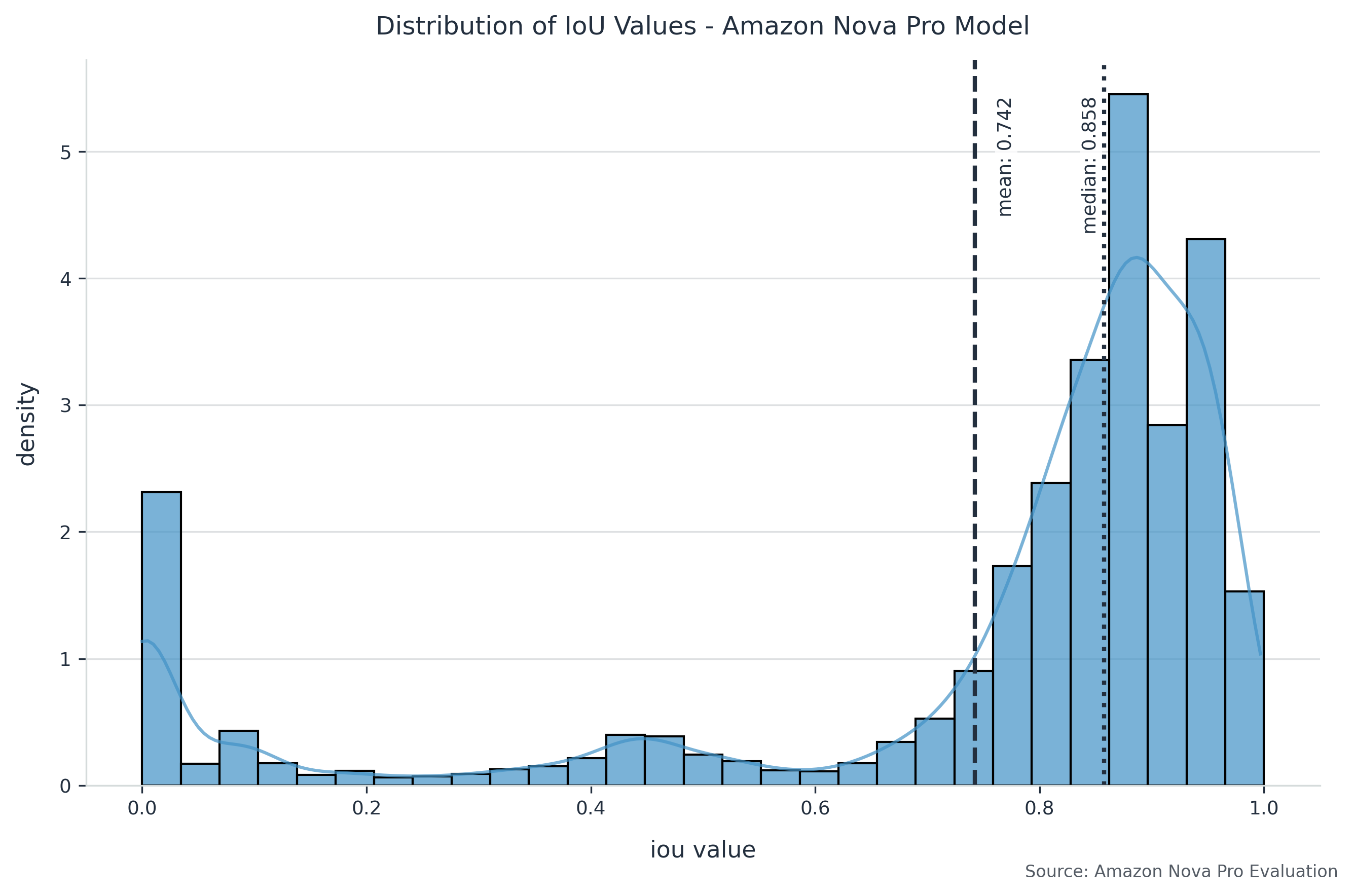
Field-specific analysis reveals that Amazon Nova Pro excels at locating structured fields like invoice numbers and dates, consistently achieving precision and recall scores above 0.85. It demonstrates particularly strong performance with text fields, maintaining robust accuracy even when dealing with varying currency formats and decimal representations. This resilience to format variations makes it especially valuable for processing documents from multiple sources or regions.
The following graph summarizes field-specific performance. The graph shows AP success percentage for each label, across all documents for each model. It is sorted by highest success.
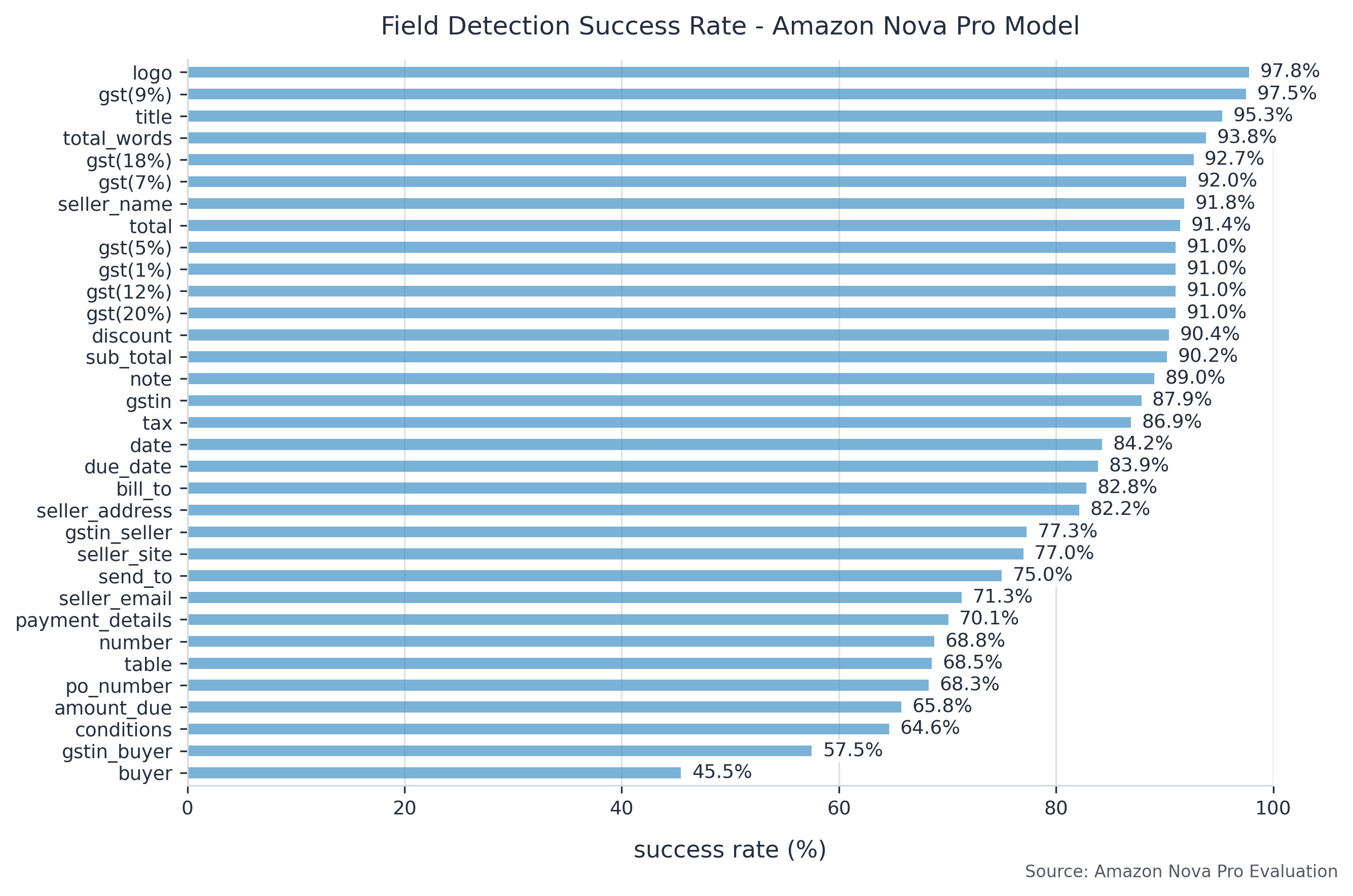
Conclusion
This benchmarking study demonstrates the significant advances in document field localization by multimodal FMs. Through comprehensive testing on the FATURA dataset, we’ve shown that these models can effectively locate and extract document fields with minimal setup effort, dramatically simplifying traditional computer vision workflows. Amazon Nova Pro emerges as an excellent choice for enterprise document processing, delivering a mAP of 0.8305 with consistent performance across diverse document types. Looking ahead, we see several promising directions for further optimization. Future work could explore extending the solution in agentic workflows to support more complex document types and field relationships.
To get started with your own implementation, you can find the complete solution code in our GitHub repository. We also recommend reviewing the Amazon Bedrock documentation for the latest model capabilities and best practices.
About the authors
 Ryan Razkenari is a Deep Learning Architect at the AWS Generative AI Innovation Center, where he uses his expertise to create cutting-edge AI solutions. With a strong background in AI and analytics, he is passionate about building innovative technologies that address real-world challenges for AWS customers.
Ryan Razkenari is a Deep Learning Architect at the AWS Generative AI Innovation Center, where he uses his expertise to create cutting-edge AI solutions. With a strong background in AI and analytics, he is passionate about building innovative technologies that address real-world challenges for AWS customers.
 Harpreet Cheema is a Deep Learning Architect at the AWS Generative AI Innovation Center. He is very passionate in the field of machine learning and in tackling different problems in the ML domain. In his role, he focuses on developing and delivering Generative AI focused solutions for real-world applications.
Harpreet Cheema is a Deep Learning Architect at the AWS Generative AI Innovation Center. He is very passionate in the field of machine learning and in tackling different problems in the ML domain. In his role, he focuses on developing and delivering Generative AI focused solutions for real-world applications.
 Spencer Romo is a Senior Data Scientist with extensive experience in deep learning applications. He specializes in intelligent document processing while maintaining broad expertise in computer vision, natural language processing, and signal processing. Spencer’s innovative work in remote sensing has resulted in multiple patents. Based in Austin, Texas, Spencer loves working directly with customers to understand their unique problems and identify impactful AI solutions. Outside of work, Spencer competes in 24 Hours of Lemons racing series, embracing the challenge of high-performance driving on a budget.
Spencer Romo is a Senior Data Scientist with extensive experience in deep learning applications. He specializes in intelligent document processing while maintaining broad expertise in computer vision, natural language processing, and signal processing. Spencer’s innovative work in remote sensing has resulted in multiple patents. Based in Austin, Texas, Spencer loves working directly with customers to understand their unique problems and identify impactful AI solutions. Outside of work, Spencer competes in 24 Hours of Lemons racing series, embracing the challenge of high-performance driving on a budget.
 Mun Kim is a Machine Learning Engineer at the AWS Generative AI Innovation Center. Mun brings expertise in building machine learning science and platform that help customers harness the power of generative AI technologies. He works closely with AWS customers to accelerate their AI adoption journey and unlock new business value.
Mun Kim is a Machine Learning Engineer at the AWS Generative AI Innovation Center. Mun brings expertise in building machine learning science and platform that help customers harness the power of generative AI technologies. He works closely with AWS customers to accelerate their AI adoption journey and unlock new business value.
 Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.
Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.