
With 22 official languages and hundreds of spoken dialects, India faces a monumental challenge in building AI systems that can work across this multilingual landscape.
In the demo area of the event, this challenge was front and centre, with startups showcasing how they’re tackling it. Among those were Sarvam AI, demonstrating Sarvam-Translate, a multilingual model fine-tuned on Google’s open-source large language model (LLM), Gemma.
Next to it, CoRover demonstrated BharatGPT, a chatbot for public services such as the one used by the Indian Railway Catering and Tourism Corporation (IRCTC).
At the event, Google announced that AI startups Sarvam, Soket AI and Gnani are building the next generation of India AI models, fine-tuning them on Gemma.
At first glance, this might seem contradictory. Three of these startups are among the four selected to build India’s sovereign large language models under the ₹10,300 crore IndiaAI Mission, a government initiative to develop home-grown foundational models from scratch, trained on Indian data, languages and values. So, why Gemma?
Building competitive models from scratch is a resource-heavy task involving multiple challenges and India does not have the luxury of building from scratch, in isolation. With limited high-quality training datasets, an evolving compute infrastructure and urgent market demand, the more pragmatic path is to start with what is available.
These startups are therefore taking a layered approach, fine-tuning open-source models to solve real-world problems today, while simultaneously building the data pipelines, user feedback loops and domain-specific expertise needed to train more indigenous and independent models over time.
Fine-tuning involves taking an existing large language model already trained on vast amounts of general data and teaching it to specialize further on focused and often local data, so that it can perform better in those contexts.

Build and bootstrap
Project EKA, an open-source community driven initiative led by Soket, is a sovereign LLM effort, being developed in partnership with IIT Gandhinagar, IIT Roorkee and IISc Bangalore. It is being designed from scratch by training code, infrastructure and data pipelines, all sourced within India. A 7 billion-parameter model is expected in the next four-five months, with a 120 billion-parameter model planned over a 10-month cycle.
“We’ve mapped four key domains: agriculture, law, education and defence,” says Abhishek Upperwal, co-founder of Soket AI. “Each has a clear dataset strategy, whether from government advisory bodies or public-sector use cases.”
A key feature of the EKA pipeline is that it is entirely decoupled from foreign infrastructure. Training happens on India’s GPU cloud and the resulting models will be open-sourced for public use.
The team, however, has taken a pragmatic approach, using Gemma to run initial deployments. “The idea is not to depend on Gemma forever,” Upperwal clarifies. “It’s to use what’s there today to bootstrap and switch to sovereign stacks when ready.”

View Full Image
CoRover’s BharatGPT is another example of this dual strategy in action. It currently runs on a fine-tuned model, offering conversational agentic AI services in multiple Indian languages to various government clients, including IRCTC, Bharat Electronics Ltd, and Life Insurance Corporation.
“For applications in public health, railways and space, we needed a base model that could be fine-tuned quickly,” says Ankush Sabharwal, CoRover’s founder. “But we have also built our own foundational LLM with Indian datasets.”
Like Soket, CoRover treats the current deployments as both service delivery and dataset creation. By pre-training and fine-tuning Gemma to handle domain-specific inputs, it is trying to improve accessibility today while building a bridge to future sovereign deployments.
“You begin with an open-source model. Then you fine-tune it, add language understanding, lower latency and expand domain relevance,” Sabharwal explains.
“Eventually, you’ll swap out the core once your own sovereign model is ready,” he adds.

View Full Image
Amlan Mohanty, a technology policy expert, calls India’s approach an experiment in trade-offs, betting on models such as Gemma to enable rapid deployment without giving up the long-term goal of autonomy. “It’s an experiment in reducing dependency on adversarial countries, ensuring cultural representation and seeing whether firms from allies like the US will uphold those expectations,” he says.
Mint reached out to Sarvam and Gnani with detailed queries regarding their use of Gemma and its relevance to their sovereign AI initiatives, but the companies did not respond.
Why local context is critical
For India, building its own AI capabilities is not just a matter of nationalistic pride or keeping up with global trends. It’s more about solving problems that no foreign model can adequately address today.
Think of a migrant from Bihar working in a cement factory in rural Maharashtra, who goes to a local clinic with a persistent cough. The doctor, who speaks Marathi, shows him a chest X-ray, while the AI tool assisting the doctor explains the findings in English, in a crisp Cupertino accent, using medical assumptions based on Western body types. The migrant understands only Hindi and much of the nuance is lost. Far from being just a language problem, it’s a mismatch in cultural, physiological and contextual grounding.
A rural frontline health worker in Bihar needs an AI tool that understands local medical terms in Maithili, just as a farmer in Maharashtra needs crop advisories that align with state-specific irrigation schedules. A government portal should be able to process citizen queries in 15 languages with regional variations.
These are high-impact and everyday use cases where errors can directly affect livelihoods, functioning of public services and health outcomes. Fine-tuning open models gives Indian developers a way to address these urgent and ground-level needs right now, while building the datasets, domain knowledge and infrastructure that can eventually support a truly sovereign AI stack.
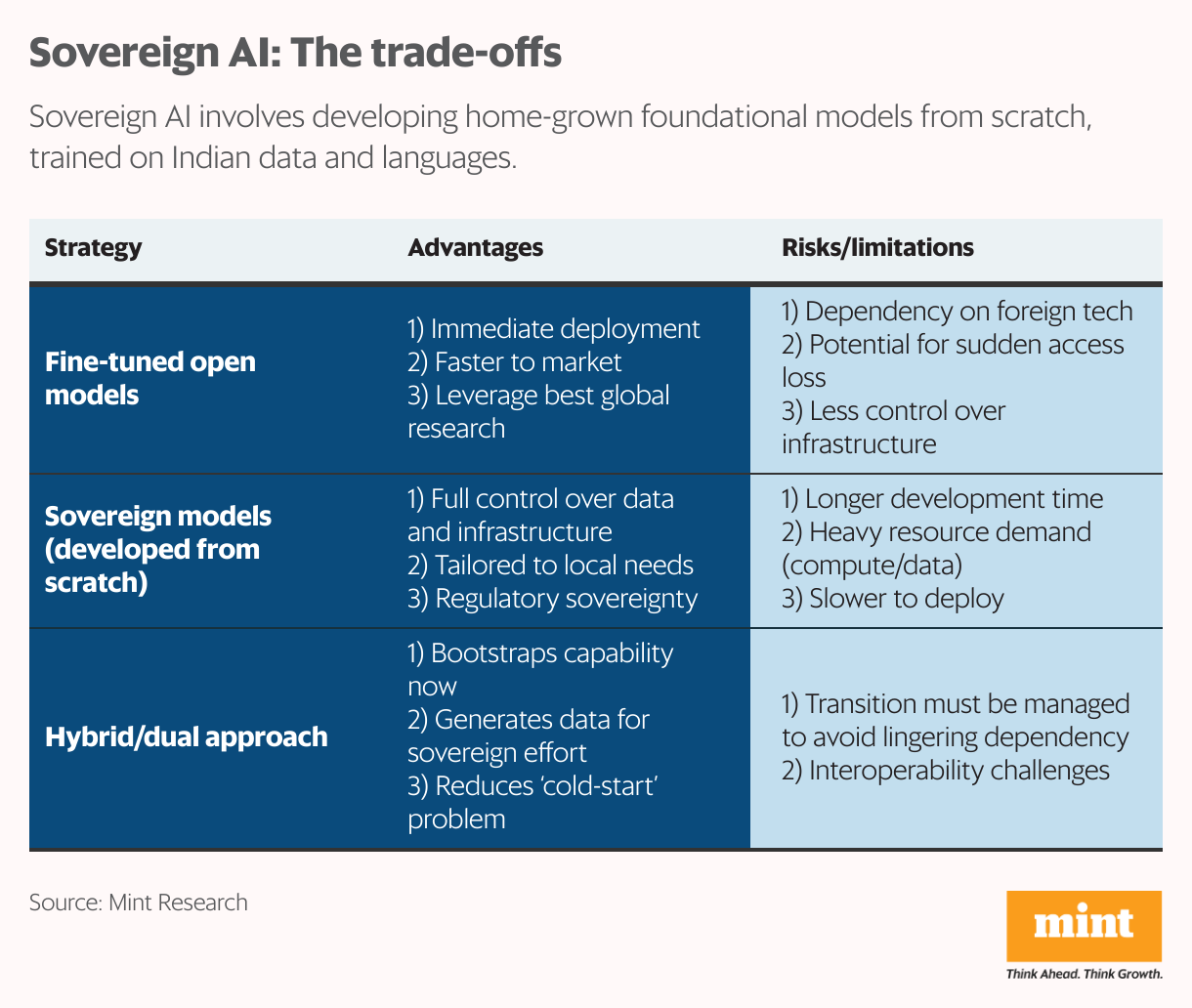
This dual-track strategy is possibly one of the fastest ways forward, using open tools to bootstrap sovereign capacity from the ground up.
“We don’t want to lose the momentum. Fine-tuning models like Gemma lets us solve real-world problems today in applications such as agriculture or education, while we build sovereign models from scratch,” says Soket AI’s Upperwal. “These are parallel but separate threads,” says Upperwal. “One is about immediate utility, the other about long-term independence. Ultimately these threads will converge.”
A strategic priority
The IndiaAI Mission is a national response to a growing geopolitical issue. As AI systems become central to education, agriculture, defence and governance, over-reliance on foreign platforms raises the risks of data exposure and loss of control.
This was highlighted last month when Microsoft abruptly cut off cloud services to Nayara Energy after European Union sanctions on its Russian-linked operations. The disruption, which was reversed only after a court intervention, raised alarms on how foreign tech providers can become geopolitical pressure points.
Around the same time, US President Donald Trump doubled tariffs on Indian imports to 50%, showing how trade and tech are increasingly being used as leverage.

View Full Image
Besides reducing dependence, sovereign AI systems are also important for India’s critical sectors to accurately represent local values, regulatory frameworks and linguistic diversity.
Most global AI models are trained on English-dominant and Western datasets, which make them poorly equipped to handle the realities of India’s multilingual population or the domain-specific complexity of its systems.
This becomes a challenge when it comes to applications such as interpreting Indian legal judgments or accounting for local crop cycles and farming practices in agriculture.
Mohanty says that sovereignty in AI isn’t about isolation, but about who controls the infrastructure and who sets the terms. “Sovereignty is basically about choice and dependencies. The more choice you have, the more sovereignty you have.”
He adds that full-stack independence from chips to models is not feasible for any country, including India. Even global powers such as the US and China balance domestic development with strategic partnerships. “Nobody has complete sovereignty or control or self-sufficiency across the stack, so you either build it yourself or you partner with a trusted ally.”
Mohanty also points out that the Indian government has taken a pragmatic approach by staying agnostic to the foundational elements of its AI stack. This stance is shaped less by ideology and more by constraints such as lack of Indic data, compute capacity and ready-made open-source alternatives built for India.
India’s data lacunae
Despite the momentum behind India’s sovereign AI push, the lack of high-quality training data, particularly in Indian languages, continues to be one of its most fundamental roadblocks. While the country is rich in linguistic diversity, that diversity has not translated into digital data that AI systems can learn from.
Manish Gupta, director of engineering at Google DeepMind India, cited internal assessments that found that 72 of India’s spoken languages, which had over 100,000 speakers, had virtually no digital presence. “Data is the fuel of AI and 72 out of those 125 languages had zero digital data,” he says.
To address this linguistic challenge for Google’s India market, the company launched Project Vaani in collaboration with the Indian Institute of Science (IISc).
This initiative aims to collect voice samples across hundreds of Indian districts. The first phase captured over 14,000 hours of speech data from 80 districts, representing 59 languages, 15 of which previously had no digital datasets. The second phase expanded coverage to 160 districts and future phases aim to reach all 773 districts in India.

“There’s a lot of work that goes into cleaning up the data, because sometimes the quality is not good,” Gupta says, referring to the challenges of transcription and audio consistency.
Google is also developing techniques to integrate these local language capabilities into its large models.
Gupta says that learnings from widely spoken languages such as English and Hindi are helping improve performance in lower-resource languages such as Gujarati and Tamil, largely due to cross-lingual transfer capabilities built into multilingual language models.
The company’s Gemma LLM incorporates Indian language capabilities derived from this body of work. Gemma ties into LLM efforts run by Indian startups through a combination of Google’s technical collaborations, infrastructure guidance and by making its collected datasets publicly available.
According to Gupta, the strategy is driven by both commercial and research imperatives. India is seen as a global testbed for multilingual and low-resource AI development. Supporting local language AI, especially through partnerships with startups such as Sarvam, Soket AI and Gnani.ai, allows Google to build inclusive tools that can scale beyond India to include other linguistically complex regions in Southeast Asia and Africa.
For India’s sovereign AI builders, the lack of readymade and high-quality Indic datasets means that model development and dataset creation must happen in parallel.
For the Global South
India’s layered strategy to use open models now, while concurrently building sovereign models, also offers a roadmap for other countries navigating similar constraints. It’s a blueprint for the Global South, where nations are wrestling with the same dilemma on how to build AI systems that reflect local languages, contexts and values without the luxury of vast compute budgets or mature data ecosystems. For these countries, fine-tuned open models offer a bridge to capability, inclusion, and control.
“Full-stack sovereignty in AI is a marathon, not a sprint,” Upperwal says. “You don’t build a 120 billion model in a vacuum. You get there by deploying fast, learning fast and shifting when ready.”
Full-stack sovereignty in AI is a marathon, not a sprint.
— Abhishek Upperwal
Singapore, Vietnam and Thailand are already exploring similar methods, using Gemma to kickstart their local LLM efforts.
By 2026, when India’s sovereign LLMs, including EKA, are expected to be production-ready, Upperwal says the dual track will likely converge, and bootstrapped models will fade while homegrown systems may take their place.
But even as these startups build on open tools such as Meta’s Llama or Google’s Gemma, which are engineered by global tech giants, the question of dependency continues to loom. Even for open-source models, control over architecture, training techniques and infrastructure support still leans heavily on Big Tech.
While Google has open-sourced speech datasets, including Project Vaani, and extended partnerships with IndiaAI Mission startups, the terms of such openness are not always symmetrical. India’s sovereign plans, therefore, depend not on shunning open models but on eventually outgrowing them.
“If Google is directed by the US government to close down its weights (model parameters), or increase API (application programming interface) prices or change transparency norms, what would the impact be on Sarvam or Soket?” questions Mohanty, adding that while the current India-US tech partnership is strong, future policies could shift and jeopardize India’s digital sovereignty.
In the years ahead, India and other nations in the Global South will face a critical question over whether they can convert this borrowed support into a complete, sovereign AI infrastructure, before the terms of access shift or the window to act closes.
Key Takeaways
As artificial intelligence systems become central to education, agriculture, defence and governance, over-reliance on foreign platforms raises the risks of data exposure and loss of control.
With 22 official languages and hundreds of spoken dialects, India faces a monumental challenge in building AI systems that can work across this multilingual landscape.
For India, building its own AI capabilities is not just a matter of nationalistic pride—it’s more about solving problems that no foreign model can adequately address today.
So, Indian startups are fine-tuning open-source models to solve real-world problems today.
Simultaneously, they are building the data pipelines and domain-specific expertise needed to train more indigenous models.
India’s layered strategy offers a roadmap for other countries navigating similar constraints.