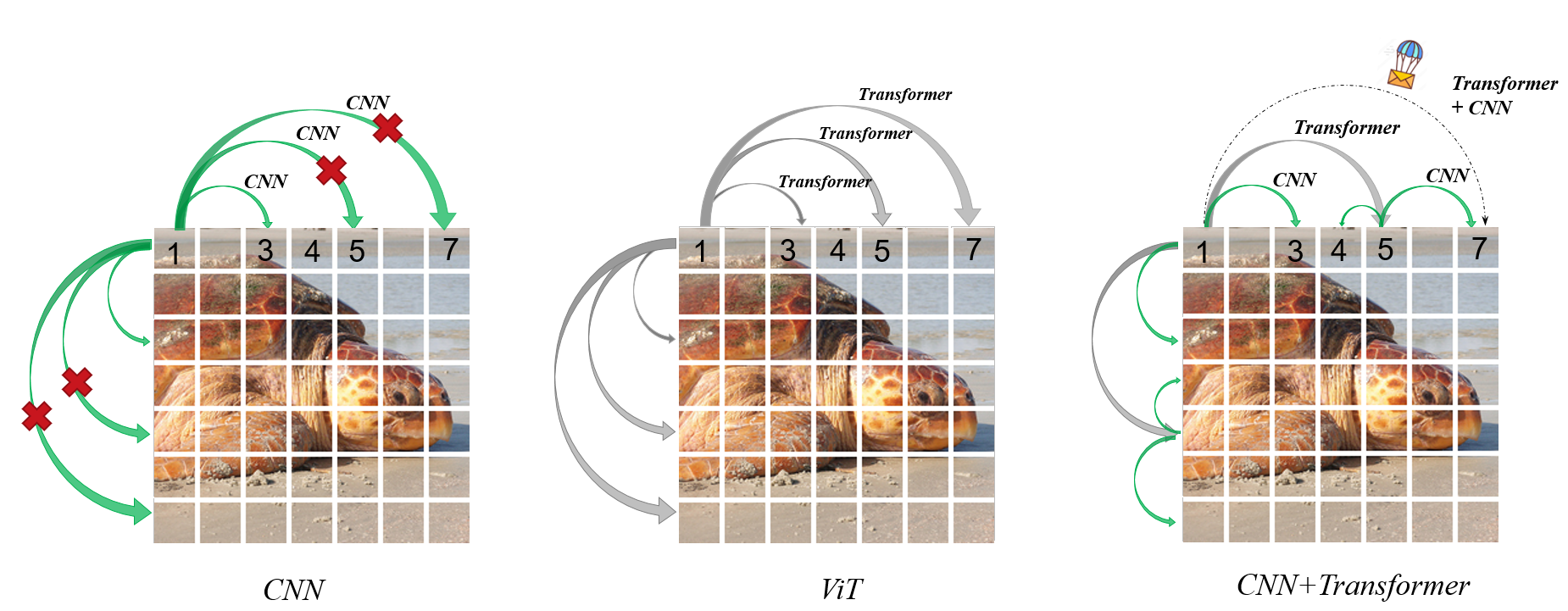
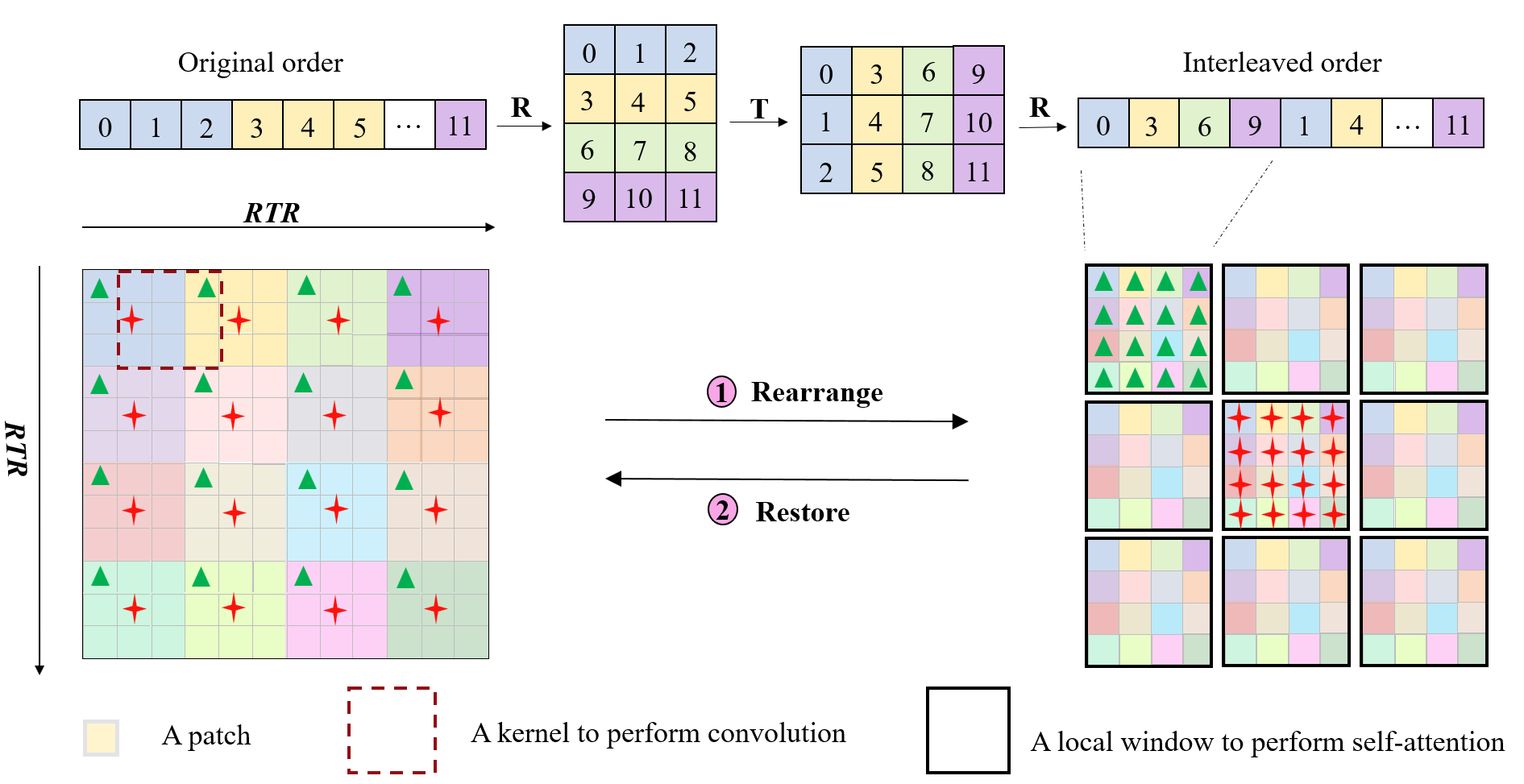
We introduce Iwin Transformer, a novel position-embedding-free hierarchical vision transformer, which can be fine-tuned directly from low to high resolution through the collaboration of innovative interleaved window attention and depthwise separable convolution. This approach uses attention to connect distant tokens and applies convolution to link neighboring tokens, enabling global information exchange within a single module, overcoming Swin Transformer’s limitation of requiring two consecutive blocks to approximate global attention. Extensive experiments on visual benchmarks demonstrate that Iwin Transformer exhibits strong competitiveness in tasks such as image classification (87.4 top-1 accuracy on ImageNet-1K), semantic segmentation, and video action recognition. We also validate the effectiveness of the core component in Iwin as a standalone module that can seamlessly replace the self-attention module in class-conditional image generation. The concepts and methods introduced by the Iwin Transformer have the potential to inspire future research, like Iwin 3D Attention in video generation. The code and models are available at https://github.com/Cominder/Iwin-Transformer.