
Last month, we launched Gemma 3, our latest generation of open models. Delivering state-of-the-art performance, Gemma 3 quickly established itself as a leading model capable of running on a single high-end GPU like the NVIDIA H100 using its native BFloat16 (BF16) precision.
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
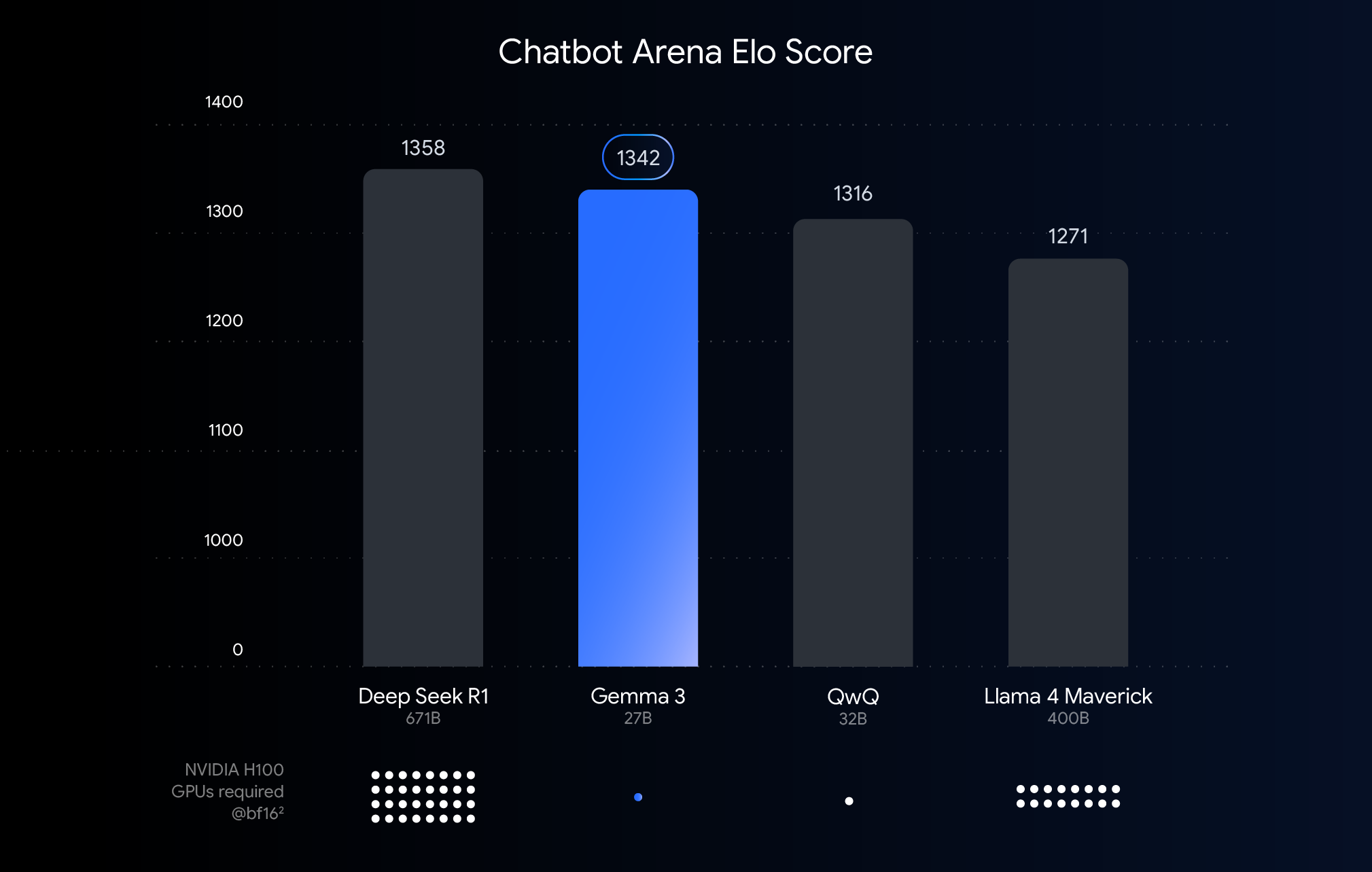
This chart ranks AI models by Chatbot Arena Elo scores; higher scores (top numbers) indicate greater user preference. Dots show estimated NVIDIA H100 GPU requirements.
Understanding performance, precision, and quantization
The chart above shows the performance (Elo score) of recently released large language models. Higher bars mean better performance in comparisons as rated by humans viewing side-by-side responses from two anonymous models. Below each bar, we indicate the estimated number of NVIDIA H100 GPUs needed to run that model using the BF16 data type.
Why BFloat16 for this comparison? BF16 is a common numerical format used during inference of many large models. It means that the model parameters are represented with 16 bits of precision. Using BF16 for all models helps us to make an apples-to-apples comparison of models in a common inference setup. This allows us to compare the inherent capabilities of the models themselves, removing variables like different hardware or optimization techniques like quantization, which we’ll discuss next.
It’s important to note that while this chart uses BF16 for a fair comparison, deploying the very largest models often involves using lower-precision formats like FP8 as a practical necessity to reduce immense hardware requirements (like the number of GPUs), potentially accepting a performance trade-off for feasibility.
The Need for Accessibility
While top performance on high-end hardware is great for cloud deployments and research, we heard you loud and clear: you want the power of Gemma 3 on the hardware you already own. We’re committed to making powerful AI accessible, and that means enabling efficient performance on the consumer-grade GPUs found in desktops, laptops, and even phones.
Performance Meets Accessibility with Quantization-Aware Training in Gemma 3
This is where quantization comes in. In AI models, quantization reduces the precision of the numbers (the model’s parameters) it stores and uses to calculate responses. Think of quantization like compressing an image by reducing the number of colors it uses. Instead of using 16 bits per number (BFloat16), we can use fewer bits, like 8 (int8) or even 4 (int4).
Using int4 means each number is represented using only 4 bits – a 4x reduction in data size compared to BF16. Quantization can often lead to performance degradation, so we’re excited to release Gemma 3 models that are robust to quantization. We released several quantized variants for each Gemma 3 model to enable inference with your favorite inference engine, such as Q4_0 (a common quantization format) for Ollama, llama.cpp, and MLX.
How do we maintain quality? We use QAT. Instead of just quantizing the model after it’s fully trained, QAT incorporates the quantization process during training. QAT simulates low-precision operations during training to allow quantization with less degradation afterwards for smaller, faster models while maintaining accuracy. Diving deeper, we applied QAT on ~5,000 steps using probabilities from the non-quantized checkpoint as targets. We reduce the perplexity drop by 54% (using llama.cpp perplexity evaluation) when quantizing down to Q4_0.
See the Difference: Massive VRAM Savings
The impact of int4 quantization is dramatic. Look at the VRAM (GPU memory) required just to load the model weights:
Gemma 3 27B: Drops from 54 GB (BF16) to just 14.1 GB (int4)Gemma 3 12B: Shrinks from 24 GB (BF16) to only 6.6 GB (int4)Gemma 3 4B: Reduces from 8 GB (BF16) to a lean 2.6 GB (int4)Gemma 3 1B: Goes from 2 GB (BF16) down to a tiny 0.5 GB (int4)
Note: This figure only represents the VRAM required to load the model weights. Running the model also requires additional VRAM for the KV cache, which stores information about the ongoing conversation and depends on the context length
Run Gemma 3 on Your Device
These dramatic reductions unlock the ability to run larger, powerful models on widely available consumer hardware:
Gemma 3 27B (int4): Now fits comfortably on a single desktop NVIDIA RTX 3090 (24GB VRAM) or similar card, allowing you to run our largest Gemma 3 variant locally.Gemma 3 12B (int4): Runs efficiently on laptop GPUs like the NVIDIA RTX 4060 Laptop GPU (8GB VRAM), bringing powerful AI capabilities to portable machines.Smaller Models (4B, 1B): Offer even greater accessibility for systems with more constrained resources, including phones and toasters (if you have a good one).
Easy Integration with Popular Tools
We want you to be able to use these models easily within your preferred workflow. Our official int4 and Q4_0 unquantized QAT models are available on Hugging Face and Kaggle. We’ve partnered with popular developer tools that enable seamlessly trying out the QAT-based quantized checkpoints:
Ollama: Get running quickly – all our Gemma 3 QAT models are natively supported starting today with a simple command.LM Studio: Easily download and run Gemma 3 QAT models on your desktop via its user-friendly interface.MLX: Leverage MLX for efficient, optimized inference of Gemma 3 QAT models on Apple Silicon.Gemma.cpp: Use our dedicated C++ implementation for highly efficient inference directly on the CPU.llama.cpp: Integrate easily into existing workflows thanks to native support for our GGUF-formatted QAT models.
More Quantizations in the Gemmaverse
Our official Quantization Aware Trained (QAT) models provide a high-quality baseline, but the vibrant Gemmaverse offers many alternatives. These often use Post-Training Quantization (PTQ), with significant contributions from members such as Bartowski, Unsloth, and GGML readily available on Hugging Face. Exploring these community options provides a wider spectrum of size, speed, and quality trade-offs to fit specific needs.
Get Started Today
Bringing state-of-the-art AI performance to accessible hardware is a key step in democratizing AI development. With Gemma 3 models, optimized through QAT, you can now leverage cutting-edge capabilities on your own desktop or laptop.
Explore the quantized models and start building:
We can’t wait to see what you build with Gemma 3 running locally!